Benchmarks for ensemble¶
RandomForestClassifier-arcene¶
Benchmark setup
from sklearn.ensemble import RandomForestClassifier from deps import load_data kwargs = {} X, y, X_t, y_t = load_data('arcene') obj = RandomForestClassifier(**kwargs)
Benchmark statement
obj.fit(X, y)
Execution time

Memory usage
Additional output
cProfile
4810 function calls (4660 primitive calls) in 2.108 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 2.109 2.109 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 2.109 2.109 <f>:1(<module>)
1 0.000 0.000 2.108 2.108 /tmp/vb_sklearn/sklearn/ensemble/forest.py:211(fit)
1 0.000 0.000 2.097 2.097 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:430(__call__)
1 0.000 0.000 2.097 2.097 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:292(dispatch)
1 0.000 0.000 2.096 2.096 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:121(__init__)
1 0.627 0.627 2.096 2.096 /tmp/vb_sklearn/sklearn/ensemble/forest.py:62(_parallel_build_trees)
10 0.002 0.000 1.433 0.143 /tmp/vb_sklearn/sklearn/tree/tree.py:171(fit)
10 0.584 0.058 1.429 0.143 {method 'build' of 'sklearn.tree._tree.Tree' objects}
18 0.000 0.000 0.843 0.047 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:598(argsort)
18 0.843 0.047 0.843 0.047 {method 'argsort' of 'numpy.ndarray' objects}
10 0.000 0.000 0.035 0.003 /tmp/vb_sklearn/sklearn/ensemble/base.py:49(_make_estimator)
90/10 0.001 0.000 0.033 0.003 /tmp/vb_sklearn/sklearn/base.py:16(clone)
150/80 0.001 0.000 0.029 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:145(deepcopy)
10 0.000 0.000 0.027 0.003 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:306(_reconstruct)
10 0.025 0.003 0.025 0.003 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/random/__init__.py:93(__RandomState_ctor)
65 0.012 0.000 0.012 0.000 {numpy.core.multiarray.array}
23 0.000 0.000 0.011 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
1 0.000 0.000 0.011 0.011 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
50 0.001 0.000 0.004 0.000 /tmp/vb_sklearn/sklearn/base.py:193(get_params)
30 0.000 0.000 0.003 0.000 /tmp/vb_sklearn/sklearn/base.py:211(set_params)
50 0.000 0.000 0.003 0.000 /tmp/vb_sklearn/sklearn/base.py:164(_get_param_names)
50 0.000 0.000 0.002 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:801(getargspec)
50 0.001 0.000 0.001 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:741(getargs)
11 0.001 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
83 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
20 0.000 0.000 0.001 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:234(_deepcopy_tuple)
83 0.001 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
10 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1774(amax)
150 0.001 0.000 0.001 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:267(_keep_alive)
348 0.001 0.000 0.001 0.000 {hasattr}
10 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:32(_wrapit)
10 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
587 0.000 0.000 0.000 0.000 {getattr}
11 0.000 0.000 0.000 0.000 {numpy.core.multiarray.concatenate}
10 0.000 0.000 0.000 0.000 {method 'sum' of 'numpy.ndarray' objects}
10 0.000 0.000 0.000 0.000 {method '__reduce_ex__' of 'object' objects}
395 0.000 0.000 0.000 0.000 {isinstance}
18 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:325(asfortranarray)
11 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:6(atleast_1d)
10 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/tree/tree.py:436(__init__)
256 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
18 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
21 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:181(check_random_state)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:94(check_arrays)
10 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/tree/tree.py:144(__init__)
12 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/forest.py:281(<genexpr>)
11 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:757(searchsorted)
10 0.000 0.000 0.000 0.000 {method 'max' of 'numpy.ndarray' objects}
50 0.000 0.000 0.000 0.000 {method 'sort' of 'list' objects}
10 0.000 0.000 0.000 0.000 {method '__setstate__' of 'mtrand.RandomState' objects}
21 0.000 0.000 0.000 0.000 {method 'randint' of 'mtrand.RandomState' objects}
50 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:67(ismethod)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:101(delayed)
410 0.000 0.000 0.000 0.000 {id}
80 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/base.py:56(<genexpr>)
310 0.000 0.000 0.000 0.000 {method 'get' of 'dict' objects}
11 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:781(copy)
11 0.000 0.000 0.000 0.000 {method 'searchsorted' of 'numpy.ndarray' objects}
50 0.000 0.000 0.000 0.000 <string>:8(__new__)
70 0.000 0.000 0.000 0.000 {range}
100 0.000 0.000 0.000 0.000 {built-in method __new__ of type object at 0x781380}
20 0.000 0.000 0.000 0.000 {max}
168 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
11 0.000 0.000 0.000 0.000 {method 'sort' of 'numpy.ndarray' objects}
18 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
93 0.000 0.000 0.000 0.000 {setattr}
50 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:142(isfunction)
50 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:209(iscode)
10 0.000 0.000 0.000 0.000 {method '__deepcopy__' of 'numpy.ndarray' objects}
51 0.000 0.000 0.000 0.000 {method 'pop' of 'list' objects}
18 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
159 0.000 0.000 0.000 0.000 {len}
11 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {cPickle.dumps}
110 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:198(_deepcopy_atomic)
3 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:87(_num_samples)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/logger.py:39(short_format_time)
1 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/functools.py:17(update_wrapper)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:390(retrieve)
20 0.000 0.000 0.000 0.000 {issubclass}
40 0.000 0.000 0.000 0.000 {method 'iteritems' of 'dict' objects}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/forest.py:123(_partition_trees)
10 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:449(isfortran)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/logger.py:23(_squeeze_time)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:289(ascontiguousarray)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:282(__init__)
1 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/functools.py:39(wraps)
2 0.000 0.000 0.000 0.000 {time.time}
1 0.000 0.000 0.000 0.000 {method 'startswith' of 'str' objects}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:337(_print)
1 0.000 0.000 0.000 0.000 {min}
1 0.000 0.000 0.000 0.000 {method 'update' of 'dict' objects}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:49(_verbosity_filter)
4 0.000 0.000 0.000 0.000 {method 'pop' of 'dict' objects}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:108(delayed_function)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:126(get)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/ensemble/forest.py
Function: fit at line 211
Total time: 2.21975 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
211 def fit(self, X, y):
212 """Build a forest of trees from the training set (X, y).
213
214 Parameters
215 ----------
216 X : array-like of shape = [n_samples, n_features]
217 The training input samples.
218
219 y : array-like, shape = [n_samples] or [n_samples, n_outputs]
220 The target values (integers that correspond to classes in
221 classification, real numbers in regression).
222
223 Returns
224 -------
225 self : object
226 Returns self.
227 """
228 # Precompute some data
229 1 152 152.0 0.0 X, y = check_arrays(X, y, sparse_format="dense")
230 1 12 12.0 0.0 if getattr(X, "dtype", None) != DTYPE or \
231 X.ndim != 2 or not X.flags.fortran:
232 1 9328 9328.0 0.4 X = array2d(X, dtype=DTYPE, order="F")
233
234 1 13 13.0 0.0 n_samples, self.n_features_ = X.shape
235
236 1 7 7.0 0.0 if self.bootstrap:
237 1 6 6.0 0.0 sample_mask = None
238 1 7 7.0 0.0 X_argsorted = None
239
240 else:
241 if self.oob_score:
242 raise ValueError("Out of bag estimation only available"
243 " if bootstrap=True")
244
245 sample_mask = np.ones((n_samples,), dtype=np.bool)
246
247 n_jobs, _, starts = _partition_features(self, self.n_features_)
248
249 all_X_argsorted = Parallel(n_jobs=n_jobs)(
250 delayed(_parallel_X_argsort)(
251 X[:, starts[i]:starts[i + 1]])
252 for i in xrange(n_jobs))
253
254 X_argsorted = np.asfortranarray(np.hstack(all_X_argsorted))
255
256 1 47 47.0 0.0 y = np.atleast_1d(y)
257 1 7 7.0 0.0 if y.ndim == 1:
258 1 19 19.0 0.0 y = y[:, np.newaxis]
259
260 1 7 7.0 0.0 self.classes_ = []
261 1 7 7.0 0.0 self.n_classes_ = []
262 1 8 8.0 0.0 self.n_outputs_ = y.shape[1]
263
264 1 11 11.0 0.0 if isinstance(self.base_estimator, ClassifierMixin):
265 1 29 29.0 0.0 y = np.copy(y)
266
267 2 19 9.5 0.0 for k in xrange(self.n_outputs_):
268 1 129 129.0 0.0 unique = np.unique(y[:, k])
269 1 9 9.0 0.0 self.classes_.append(unique)
270 1 9 9.0 0.0 self.n_classes_.append(unique.shape[0])
271 1 36 36.0 0.0 y[:, k] = np.searchsorted(unique, y[:, k])
272
273 1 12 12.0 0.0 if getattr(y, "dtype", None) != DTYPE or not y.flags.contiguous:
274 1 21 21.0 0.0 y = np.ascontiguousarray(y, dtype=DOUBLE)
275
276 # Assign chunk of trees to jobs
277 1 34 34.0 0.0 n_jobs, n_trees, _ = _partition_trees(self)
278
279 # Parallel loop
280 1 25 25.0 0.0 all_trees = Parallel(n_jobs=n_jobs, verbose=self.verbose)(
281 1 8 8.0 0.0 delayed(_parallel_build_trees)(
282 n_trees[i],
283 self,
284 X,
285 y,
286 sample_mask,
287 X_argsorted,
288 self.random_state.randint(MAX_INT),
289 verbose=self.verbose)
290 1 2209689 2209689.0 99.5 for i in xrange(n_jobs))
291
292 # Reduce
293 11 81 7.4 0.0 self.estimators_ = [tree for tree in itertools.chain(*all_trees)]
294
295 # Calculate out of bag predictions and score
296 1 6 6.0 0.0 if self.oob_score:
297 if isinstance(self, ClassifierMixin):
298 self.oob_decision_function_ = []
299 self.oob_score_ = 0.0
300
301 predictions = []
302 for k in xrange(self.n_outputs_):
303 predictions.append(np.zeros((n_samples,
304 self.n_classes_[k])))
305
306 for estimator in self.estimators_:
307 mask = np.ones(n_samples, dtype=np.bool)
308 mask[estimator.indices_] = False
309
310 p_estimator = estimator.predict_proba(X[mask, :])
311 if self.n_outputs_ == 1:
312 p_estimator = [p_estimator]
313
314 for k in xrange(self.n_outputs_):
315 predictions[k][mask, :] += p_estimator[k]
316
317 for k in xrange(self.n_outputs_):
318 if (predictions[k].sum(axis=1) == 0).any():
319 warn("Some inputs do not have OOB scores. "
320 "This probably means too few trees were used "
321 "to compute any reliable oob estimates.")
322 decision = predictions[k] \
323 / predictions[k].sum(axis=1)[:, np.newaxis]
324 self.oob_decision_function_.append(decision)
325
326 self.oob_score_ += np.mean(y[:, k] \
327 == np.argmax(predictions[k], axis=1))
328
329 if self.n_outputs_ == 1:
330 self.oob_decision_function_ = \
331 self.oob_decision_function_[0]
332
333 self.oob_score_ /= self.n_outputs_
334
335 else:
336 # Regression:
337 predictions = np.zeros((n_samples, self.n_outputs_))
338 n_predictions = np.zeros((n_samples, self.n_outputs_))
339
340 for estimator in self.estimators_:
341 mask = np.ones(n_samples, dtype=np.bool)
342 mask[estimator.indices_] = False
343
344 p_estimator = estimator.predict(X[mask, :])
345 if self.n_outputs_ == 1:
346 p_estimator = p_estimator[:, np.newaxis]
347
348 predictions[mask, :] += p_estimator
349 n_predictions[mask, :] += 1
350 if (n_predictions == 0).any():
351 warn("Some inputs do not have OOB scores. "
352 "This probably means too few trees were used "
353 "to compute any reliable oob estimates.")
354 n_predictions[n_predictions == 0] = 1
355 predictions /= n_predictions
356
357 self.oob_prediction_ = predictions
358 if self.n_outputs_ == 1:
359 self.oob_prediction_ = \
360 self.oob_prediction_.reshape((n_samples, ))
361
362 self.oob_score_ = 0.0
363 for k in xrange(self.n_outputs_):
364 self.oob_score_ += r2_score(y[:, k], predictions[:, k])
365 self.oob_score_ /= self.n_outputs_
366
367 # Sum the importances
368 1 6 6.0 0.0 if self.compute_importances:
369 self.feature_importances_ = \
370 sum(tree.feature_importances_ for tree in self.estimators_) \
371 / self.n_estimators
372
373 1 6 6.0 0.0 return self
RandomForestClassifier-madelon¶
Benchmark setup
from sklearn.ensemble import RandomForestClassifier from deps import load_data kwargs = {} X, y, X_t, y_t = load_data('madelon') obj = RandomForestClassifier(**kwargs)
Benchmark statement
obj.fit(X, y)
Execution time

Memory usage
Additional output
cProfile
8912 function calls (8762 primitive calls) in 6.091 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 6.091 6.091 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 6.091 6.091 <f>:1(<module>)
1 0.000 0.000 6.091 6.091 /tmp/vb_sklearn/sklearn/ensemble/forest.py:211(fit)
1 0.000 0.000 6.080 6.080 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:430(__call__)
1 0.000 0.000 6.080 6.080 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:292(dispatch)
1 0.000 0.000 6.079 6.079 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:121(__init__)
1 0.841 0.841 6.079 6.079 /tmp/vb_sklearn/sklearn/ensemble/forest.py:62(_parallel_build_trees)
10 0.002 0.000 5.201 0.520 /tmp/vb_sklearn/sklearn/tree/tree.py:171(fit)
10 2.390 0.239 5.194 0.519 {method 'build' of 'sklearn.tree._tree.Tree' objects}
604 0.003 0.000 2.792 0.005 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:598(argsort)
604 2.789 0.005 2.789 0.005 {method 'argsort' of 'numpy.ndarray' objects}
10 0.000 0.000 0.035 0.003 /tmp/vb_sklearn/sklearn/ensemble/base.py:49(_make_estimator)
90/10 0.001 0.000 0.033 0.003 /tmp/vb_sklearn/sklearn/base.py:16(clone)
150/80 0.001 0.000 0.029 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:145(deepcopy)
10 0.000 0.000 0.027 0.003 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:306(_reconstruct)
10 0.025 0.003 0.025 0.003 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/random/__init__.py:93(__RandomState_ctor)
651 0.014 0.000 0.014 0.000 {numpy.core.multiarray.array}
23 0.000 0.000 0.010 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
1 0.000 0.000 0.010 0.010 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
604 0.002 0.000 0.006 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
604 0.002 0.000 0.006 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:325(asfortranarray)
50 0.001 0.000 0.004 0.000 /tmp/vb_sklearn/sklearn/base.py:193(get_params)
30 0.000 0.000 0.003 0.000 /tmp/vb_sklearn/sklearn/base.py:211(set_params)
50 0.000 0.000 0.003 0.000 /tmp/vb_sklearn/sklearn/base.py:164(_get_param_names)
11 0.001 0.000 0.003 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
604 0.002 0.000 0.002 0.000 {method 'fill' of 'numpy.ndarray' objects}
50 0.000 0.000 0.002 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:801(getargspec)
604 0.002 0.000 0.002 0.000 {numpy.core.multiarray.empty}
11 0.001 0.000 0.001 0.000 {method 'sort' of 'numpy.ndarray' objects}
50 0.001 0.000 0.001 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:741(getargs)
20 0.000 0.000 0.001 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:234(_deepcopy_tuple)
83 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
11 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:757(searchsorted)
11 0.001 0.000 0.001 0.000 {method 'searchsorted' of 'numpy.ndarray' objects}
83 0.001 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
10 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1774(amax)
21 0.001 0.000 0.001 0.000 {method 'randint' of 'mtrand.RandomState' objects}
150 0.001 0.000 0.001 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:267(_keep_alive)
348 0.001 0.000 0.001 0.000 {hasattr}
10 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
10 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:32(_wrapit)
587 0.000 0.000 0.000 0.000 {getattr}
10 0.000 0.000 0.000 0.000 {method 'sum' of 'numpy.ndarray' objects}
11 0.000 0.000 0.000 0.000 {numpy.core.multiarray.concatenate}
395 0.000 0.000 0.000 0.000 {isinstance}
10 0.000 0.000 0.000 0.000 {method '__reduce_ex__' of 'object' objects}
11 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:6(atleast_1d)
10 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/tree/tree.py:436(__init__)
256 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
21 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:181(check_random_state)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:94(check_arrays)
10 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/tree/tree.py:144(__init__)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/forest.py:281(<genexpr>)
11 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:781(copy)
12 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
50 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:67(ismethod)
10 0.000 0.000 0.000 0.000 {method 'max' of 'numpy.ndarray' objects}
50 0.000 0.000 0.000 0.000 {method 'sort' of 'list' objects}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:101(delayed)
80 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/base.py:56(<genexpr>)
310 0.000 0.000 0.000 0.000 {method 'get' of 'dict' objects}
50 0.000 0.000 0.000 0.000 <string>:8(__new__)
168 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
410 0.000 0.000 0.000 0.000 {id}
10 0.000 0.000 0.000 0.000 {method '__setstate__' of 'mtrand.RandomState' objects}
70 0.000 0.000 0.000 0.000 {range}
100 0.000 0.000 0.000 0.000 {built-in method __new__ of type object at 0x781380}
93 0.000 0.000 0.000 0.000 {setattr}
11 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
10 0.000 0.000 0.000 0.000 {method '__deepcopy__' of 'numpy.ndarray' objects}
50 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:142(isfunction)
50 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:209(iscode)
51 0.000 0.000 0.000 0.000 {method 'pop' of 'list' objects}
20 0.000 0.000 0.000 0.000 {max}
159 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 {cPickle.dumps}
110 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:198(_deepcopy_atomic)
1 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/functools.py:17(update_wrapper)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/logger.py:39(short_format_time)
3 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:87(_num_samples)
20 0.000 0.000 0.000 0.000 {issubclass}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:390(retrieve)
40 0.000 0.000 0.000 0.000 {method 'iteritems' of 'dict' objects}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/forest.py:123(_partition_trees)
10 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:449(isfortran)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/logger.py:23(_squeeze_time)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:282(__init__)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:289(ascontiguousarray)
1 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/functools.py:39(wraps)
2 0.000 0.000 0.000 0.000 {time.time}
4 0.000 0.000 0.000 0.000 {method 'pop' of 'dict' objects}
1 0.000 0.000 0.000 0.000 {method 'startswith' of 'str' objects}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:108(delayed_function)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:337(_print)
1 0.000 0.000 0.000 0.000 {min}
1 0.000 0.000 0.000 0.000 {method 'update' of 'dict' objects}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:49(_verbosity_filter)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:126(get)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/ensemble/forest.py
Function: fit at line 211
Total time: 6.15436 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
211 def fit(self, X, y):
212 """Build a forest of trees from the training set (X, y).
213
214 Parameters
215 ----------
216 X : array-like of shape = [n_samples, n_features]
217 The training input samples.
218
219 y : array-like, shape = [n_samples] or [n_samples, n_outputs]
220 The target values (integers that correspond to classes in
221 classification, real numbers in regression).
222
223 Returns
224 -------
225 self : object
226 Returns self.
227 """
228 # Precompute some data
229 1 131 131.0 0.0 X, y = check_arrays(X, y, sparse_format="dense")
230 1 11 11.0 0.0 if getattr(X, "dtype", None) != DTYPE or \
231 X.ndim != 2 or not X.flags.fortran:
232 1 20345 20345.0 0.3 X = array2d(X, dtype=DTYPE, order="F")
233
234 1 13 13.0 0.0 n_samples, self.n_features_ = X.shape
235
236 1 7 7.0 0.0 if self.bootstrap:
237 1 7 7.0 0.0 sample_mask = None
238 1 7 7.0 0.0 X_argsorted = None
239
240 else:
241 if self.oob_score:
242 raise ValueError("Out of bag estimation only available"
243 " if bootstrap=True")
244
245 sample_mask = np.ones((n_samples,), dtype=np.bool)
246
247 n_jobs, _, starts = _partition_features(self, self.n_features_)
248
249 all_X_argsorted = Parallel(n_jobs=n_jobs)(
250 delayed(_parallel_X_argsort)(
251 X[:, starts[i]:starts[i + 1]])
252 for i in xrange(n_jobs))
253
254 X_argsorted = np.asfortranarray(np.hstack(all_X_argsorted))
255
256 1 46 46.0 0.0 y = np.atleast_1d(y)
257 1 8 8.0 0.0 if y.ndim == 1:
258 1 18 18.0 0.0 y = y[:, np.newaxis]
259
260 1 7 7.0 0.0 self.classes_ = []
261 1 6 6.0 0.0 self.n_classes_ = []
262 1 8 8.0 0.0 self.n_outputs_ = y.shape[1]
263
264 1 12 12.0 0.0 if isinstance(self.base_estimator, ClassifierMixin):
265 1 32 32.0 0.0 y = np.copy(y)
266
267 2 19 9.5 0.0 for k in xrange(self.n_outputs_):
268 1 218 218.0 0.0 unique = np.unique(y[:, k])
269 1 9 9.0 0.0 self.classes_.append(unique)
270 1 9 9.0 0.0 self.n_classes_.append(unique.shape[0])
271 1 112 112.0 0.0 y[:, k] = np.searchsorted(unique, y[:, k])
272
273 1 11 11.0 0.0 if getattr(y, "dtype", None) != DTYPE or not y.flags.contiguous:
274 1 25 25.0 0.0 y = np.ascontiguousarray(y, dtype=DOUBLE)
275
276 # Assign chunk of trees to jobs
277 1 35 35.0 0.0 n_jobs, n_trees, _ = _partition_trees(self)
278
279 # Parallel loop
280 1 26 26.0 0.0 all_trees = Parallel(n_jobs=n_jobs, verbose=self.verbose)(
281 1 8 8.0 0.0 delayed(_parallel_build_trees)(
282 n_trees[i],
283 self,
284 X,
285 y,
286 sample_mask,
287 X_argsorted,
288 self.random_state.randint(MAX_INT),
289 verbose=self.verbose)
290 1 6133133 6133133.0 99.7 for i in xrange(n_jobs))
291
292 # Reduce
293 11 80 7.3 0.0 self.estimators_ = [tree for tree in itertools.chain(*all_trees)]
294
295 # Calculate out of bag predictions and score
296 1 7 7.0 0.0 if self.oob_score:
297 if isinstance(self, ClassifierMixin):
298 self.oob_decision_function_ = []
299 self.oob_score_ = 0.0
300
301 predictions = []
302 for k in xrange(self.n_outputs_):
303 predictions.append(np.zeros((n_samples,
304 self.n_classes_[k])))
305
306 for estimator in self.estimators_:
307 mask = np.ones(n_samples, dtype=np.bool)
308 mask[estimator.indices_] = False
309
310 p_estimator = estimator.predict_proba(X[mask, :])
311 if self.n_outputs_ == 1:
312 p_estimator = [p_estimator]
313
314 for k in xrange(self.n_outputs_):
315 predictions[k][mask, :] += p_estimator[k]
316
317 for k in xrange(self.n_outputs_):
318 if (predictions[k].sum(axis=1) == 0).any():
319 warn("Some inputs do not have OOB scores. "
320 "This probably means too few trees were used "
321 "to compute any reliable oob estimates.")
322 decision = predictions[k] \
323 / predictions[k].sum(axis=1)[:, np.newaxis]
324 self.oob_decision_function_.append(decision)
325
326 self.oob_score_ += np.mean(y[:, k] \
327 == np.argmax(predictions[k], axis=1))
328
329 if self.n_outputs_ == 1:
330 self.oob_decision_function_ = \
331 self.oob_decision_function_[0]
332
333 self.oob_score_ /= self.n_outputs_
334
335 else:
336 # Regression:
337 predictions = np.zeros((n_samples, self.n_outputs_))
338 n_predictions = np.zeros((n_samples, self.n_outputs_))
339
340 for estimator in self.estimators_:
341 mask = np.ones(n_samples, dtype=np.bool)
342 mask[estimator.indices_] = False
343
344 p_estimator = estimator.predict(X[mask, :])
345 if self.n_outputs_ == 1:
346 p_estimator = p_estimator[:, np.newaxis]
347
348 predictions[mask, :] += p_estimator
349 n_predictions[mask, :] += 1
350 if (n_predictions == 0).any():
351 warn("Some inputs do not have OOB scores. "
352 "This probably means too few trees were used "
353 "to compute any reliable oob estimates.")
354 n_predictions[n_predictions == 0] = 1
355 predictions /= n_predictions
356
357 self.oob_prediction_ = predictions
358 if self.n_outputs_ == 1:
359 self.oob_prediction_ = \
360 self.oob_prediction_.reshape((n_samples, ))
361
362 self.oob_score_ = 0.0
363 for k in xrange(self.n_outputs_):
364 self.oob_score_ += r2_score(y[:, k], predictions[:, k])
365 self.oob_score_ /= self.n_outputs_
366
367 # Sum the importances
368 1 7 7.0 0.0 if self.compute_importances:
369 self.feature_importances_ = \
370 sum(tree.feature_importances_ for tree in self.estimators_) \
371 / self.n_estimators
372
373 1 6 6.0 0.0 return self
ExtraTreesClassifier-arcene¶
Benchmark setup
from sklearn.ensemble import ExtraTreesClassifier from deps import load_data kwargs = {} X, y, X_t, y_t = load_data('arcene') obj = ExtraTreesClassifier(**kwargs)
Benchmark statement
obj.fit(X, y)
Execution time
Memory usage
Additional output
cProfile
5077 function calls (4927 primitive calls) in 1.558 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 1.558 1.558 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 1.558 1.558 <f>:1(<module>)
1 0.000 0.000 1.558 1.558 /tmp/vb_sklearn/sklearn/ensemble/forest.py:211(fit)
2 0.000 0.000 1.545 0.773 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:430(__call__)
2 0.000 0.000 1.545 0.772 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:292(dispatch)
2 0.000 0.000 1.545 0.772 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:121(__init__)
1 0.000 0.000 1.464 1.464 /tmp/vb_sklearn/sklearn/ensemble/forest.py:62(_parallel_build_trees)
10 0.001 0.000 1.426 0.143 /tmp/vb_sklearn/sklearn/tree/tree.py:171(fit)
10 1.301 0.130 1.423 0.142 {method 'build' of 'sklearn.tree._tree.Tree' objects}
46 0.000 0.000 0.198 0.004 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:598(argsort)
46 0.198 0.004 0.198 0.004 {method 'argsort' of 'numpy.ndarray' objects}
1 0.000 0.000 0.081 0.081 /tmp/vb_sklearn/sklearn/ensemble/forest.py:146(_parallel_X_argsort)
10 0.000 0.000 0.035 0.003 /tmp/vb_sklearn/sklearn/ensemble/base.py:49(_make_estimator)
90/10 0.001 0.000 0.033 0.003 /tmp/vb_sklearn/sklearn/base.py:16(clone)
150/80 0.001 0.000 0.029 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:145(deepcopy)
10 0.000 0.000 0.027 0.003 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:306(_reconstruct)
10 0.025 0.002 0.025 0.002 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/random/__init__.py:93(__RandomState_ctor)
95 0.015 0.000 0.015 0.000 {numpy.core.multiarray.array}
24 0.000 0.000 0.015 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
1 0.000 0.000 0.011 0.011 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
50 0.001 0.000 0.004 0.000 /tmp/vb_sklearn/sklearn/base.py:193(get_params)
30 0.000 0.000 0.003 0.000 /tmp/vb_sklearn/sklearn/base.py:211(set_params)
50 0.000 0.000 0.003 0.000 /tmp/vb_sklearn/sklearn/base.py:164(_get_param_names)
50 0.000 0.000 0.002 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:801(getargspec)
12 0.002 0.000 0.002 0.000 {numpy.core.multiarray.concatenate}
1 0.000 0.000 0.001 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:228(hstack)
50 0.001 0.000 0.001 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:741(getargs)
11 0.001 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
20 0.000 0.000 0.001 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:234(_deepcopy_tuple)
83 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
83 0.001 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
150 0.001 0.000 0.001 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:267(_keep_alive)
10 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1774(amax)
350 0.001 0.000 0.001 0.000 {hasattr}
46 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:325(asfortranarray)
46 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
592 0.001 0.000 0.001 0.000 {getattr}
10 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:32(_wrapit)
10 0.000 0.000 0.000 0.000 {method '__reduce_ex__' of 'object' objects}
10 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
10 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/tree/tree.py:660(__init__)
395 0.000 0.000 0.000 0.000 {isinstance}
10 0.000 0.000 0.000 0.000 {method 'sum' of 'numpy.ndarray' objects}
10 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/tree/tree.py:436(__init__)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:101(delayed)
256 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
21 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:181(check_random_state)
12 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:6(atleast_1d)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:94(check_arrays)
10 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/tree/tree.py:144(__init__)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/forest.py:250(<genexpr>)
46 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
10 0.000 0.000 0.000 0.000 {method 'max' of 'numpy.ndarray' objects}
46 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
50 0.000 0.000 0.000 0.000 {method 'sort' of 'list' objects}
80 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/base.py:56(<genexpr>)
50 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:67(ismethod)
11 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:757(searchsorted)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/forest.py:281(<genexpr>)
310 0.000 0.000 0.000 0.000 {method 'get' of 'dict' objects}
410 0.000 0.000 0.000 0.000 {id}
10 0.000 0.000 0.000 0.000 {method '__setstate__' of 'mtrand.RandomState' objects}
100 0.000 0.000 0.000 0.000 {built-in method __new__ of type object at 0x781380}
50 0.000 0.000 0.000 0.000 <string>:8(__new__)
70 0.000 0.000 0.000 0.000 {range}
2 0.000 0.000 0.000 0.000 {cPickle.dumps}
11 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:781(copy)
13 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
11 0.000 0.000 0.000 0.000 {method 'searchsorted' of 'numpy.ndarray' objects}
96 0.000 0.000 0.000 0.000 {setattr}
11 0.000 0.000 0.000 0.000 {method 'sort' of 'numpy.ndarray' objects}
171 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
50 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:209(iscode)
52 0.000 0.000 0.000 0.000 {method 'pop' of 'list' objects}
50 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:142(isfunction)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:390(retrieve)
10 0.000 0.000 0.000 0.000 {method '__deepcopy__' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/functools.py:17(update_wrapper)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/logger.py:39(short_format_time)
184 0.000 0.000 0.000 0.000 {len}
110 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:198(_deepcopy_atomic)
1 0.000 0.000 0.000 0.000 {map}
11 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
20 0.000 0.000 0.000 0.000 {max}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/forest.py:151(_partition_features)
40 0.000 0.000 0.000 0.000 {method 'iteritems' of 'dict' objects}
3 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:87(_num_samples)
20 0.000 0.000 0.000 0.000 {issubclass}
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/logger.py:23(_squeeze_time)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:282(__init__)
11 0.000 0.000 0.000 0.000 {method 'randint' of 'mtrand.RandomState' objects}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/forest.py:123(_partition_trees)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
10 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:449(isfortran)
2 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/functools.py:39(wraps)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:289(ascontiguousarray)
4 0.000 0.000 0.000 0.000 {time.time}
2 0.000 0.000 0.000 0.000 {method 'startswith' of 'str' objects}
2 0.000 0.000 0.000 0.000 {min}
2 0.000 0.000 0.000 0.000 {method 'update' of 'dict' objects}
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:337(_print)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:49(_verbosity_filter)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:126(get)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:108(delayed_function)
4 0.000 0.000 0.000 0.000 {method 'pop' of 'dict' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/ensemble/forest.py
Function: fit at line 211
Total time: 1.56702 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
211 def fit(self, X, y):
212 """Build a forest of trees from the training set (X, y).
213
214 Parameters
215 ----------
216 X : array-like of shape = [n_samples, n_features]
217 The training input samples.
218
219 y : array-like, shape = [n_samples] or [n_samples, n_outputs]
220 The target values (integers that correspond to classes in
221 classification, real numbers in regression).
222
223 Returns
224 -------
225 self : object
226 Returns self.
227 """
228 # Precompute some data
229 1 133 133.0 0.0 X, y = check_arrays(X, y, sparse_format="dense")
230 1 11 11.0 0.0 if getattr(X, "dtype", None) != DTYPE or \
231 X.ndim != 2 or not X.flags.fortran:
232 1 9217 9217.0 0.6 X = array2d(X, dtype=DTYPE, order="F")
233
234 1 13 13.0 0.0 n_samples, self.n_features_ = X.shape
235
236 1 7 7.0 0.0 if self.bootstrap:
237 sample_mask = None
238 X_argsorted = None
239
240 else:
241 1 7 7.0 0.0 if self.oob_score:
242 raise ValueError("Out of bag estimation only available"
243 " if bootstrap=True")
244
245 1 42 42.0 0.0 sample_mask = np.ones((n_samples,), dtype=np.bool)
246
247 1 38 38.0 0.0 n_jobs, _, starts = _partition_features(self, self.n_features_)
248
249 1 25 25.0 0.0 all_X_argsorted = Parallel(n_jobs=n_jobs)(
250 1 9 9.0 0.0 delayed(_parallel_X_argsort)(
251 X[:, starts[i]:starts[i + 1]])
252 1 98773 98773.0 6.3 for i in xrange(n_jobs))
253
254 1 1438 1438.0 0.1 X_argsorted = np.asfortranarray(np.hstack(all_X_argsorted))
255
256 1 37 37.0 0.0 y = np.atleast_1d(y)
257 1 8 8.0 0.0 if y.ndim == 1:
258 1 17 17.0 0.0 y = y[:, np.newaxis]
259
260 1 8 8.0 0.0 self.classes_ = []
261 1 7 7.0 0.0 self.n_classes_ = []
262 1 8 8.0 0.0 self.n_outputs_ = y.shape[1]
263
264 1 11 11.0 0.0 if isinstance(self.base_estimator, ClassifierMixin):
265 1 30 30.0 0.0 y = np.copy(y)
266
267 2 18 9.0 0.0 for k in xrange(self.n_outputs_):
268 1 116 116.0 0.0 unique = np.unique(y[:, k])
269 1 9 9.0 0.0 self.classes_.append(unique)
270 1 8 8.0 0.0 self.n_classes_.append(unique.shape[0])
271 1 36 36.0 0.0 y[:, k] = np.searchsorted(unique, y[:, k])
272
273 1 11 11.0 0.0 if getattr(y, "dtype", None) != DTYPE or not y.flags.contiguous:
274 1 22 22.0 0.0 y = np.ascontiguousarray(y, dtype=DOUBLE)
275
276 # Assign chunk of trees to jobs
277 1 38 38.0 0.0 n_jobs, n_trees, _ = _partition_trees(self)
278
279 # Parallel loop
280 1 23 23.0 0.0 all_trees = Parallel(n_jobs=n_jobs, verbose=self.verbose)(
281 1 9 9.0 0.0 delayed(_parallel_build_trees)(
282 n_trees[i],
283 self,
284 X,
285 y,
286 sample_mask,
287 X_argsorted,
288 self.random_state.randint(MAX_INT),
289 verbose=self.verbose)
290 1 1456787 1456787.0 93.0 for i in xrange(n_jobs))
291
292 # Reduce
293 11 88 8.0 0.0 self.estimators_ = [tree for tree in itertools.chain(*all_trees)]
294
295 # Calculate out of bag predictions and score
296 1 7 7.0 0.0 if self.oob_score:
297 if isinstance(self, ClassifierMixin):
298 self.oob_decision_function_ = []
299 self.oob_score_ = 0.0
300
301 predictions = []
302 for k in xrange(self.n_outputs_):
303 predictions.append(np.zeros((n_samples,
304 self.n_classes_[k])))
305
306 for estimator in self.estimators_:
307 mask = np.ones(n_samples, dtype=np.bool)
308 mask[estimator.indices_] = False
309
310 p_estimator = estimator.predict_proba(X[mask, :])
311 if self.n_outputs_ == 1:
312 p_estimator = [p_estimator]
313
314 for k in xrange(self.n_outputs_):
315 predictions[k][mask, :] += p_estimator[k]
316
317 for k in xrange(self.n_outputs_):
318 if (predictions[k].sum(axis=1) == 0).any():
319 warn("Some inputs do not have OOB scores. "
320 "This probably means too few trees were used "
321 "to compute any reliable oob estimates.")
322 decision = predictions[k] \
323 / predictions[k].sum(axis=1)[:, np.newaxis]
324 self.oob_decision_function_.append(decision)
325
326 self.oob_score_ += np.mean(y[:, k] \
327 == np.argmax(predictions[k], axis=1))
328
329 if self.n_outputs_ == 1:
330 self.oob_decision_function_ = \
331 self.oob_decision_function_[0]
332
333 self.oob_score_ /= self.n_outputs_
334
335 else:
336 # Regression:
337 predictions = np.zeros((n_samples, self.n_outputs_))
338 n_predictions = np.zeros((n_samples, self.n_outputs_))
339
340 for estimator in self.estimators_:
341 mask = np.ones(n_samples, dtype=np.bool)
342 mask[estimator.indices_] = False
343
344 p_estimator = estimator.predict(X[mask, :])
345 if self.n_outputs_ == 1:
346 p_estimator = p_estimator[:, np.newaxis]
347
348 predictions[mask, :] += p_estimator
349 n_predictions[mask, :] += 1
350 if (n_predictions == 0).any():
351 warn("Some inputs do not have OOB scores. "
352 "This probably means too few trees were used "
353 "to compute any reliable oob estimates.")
354 n_predictions[n_predictions == 0] = 1
355 predictions /= n_predictions
356
357 self.oob_prediction_ = predictions
358 if self.n_outputs_ == 1:
359 self.oob_prediction_ = \
360 self.oob_prediction_.reshape((n_samples, ))
361
362 self.oob_score_ = 0.0
363 for k in xrange(self.n_outputs_):
364 self.oob_score_ += r2_score(y[:, k], predictions[:, k])
365 self.oob_score_ /= self.n_outputs_
366
367 # Sum the importances
368 1 6 6.0 0.0 if self.compute_importances:
369 self.feature_importances_ = \
370 sum(tree.feature_importances_ for tree in self.estimators_) \
371 / self.n_estimators
372
373 1 6 6.0 0.0 return self
ExtraTreesClassifier-madelon¶
Benchmark setup
from sklearn.ensemble import ExtraTreesClassifier from deps import load_data kwargs = {} X, y, X_t, y_t = load_data('madelon') obj = ExtraTreesClassifier(**kwargs)
Benchmark statement
obj.fit(X, y)
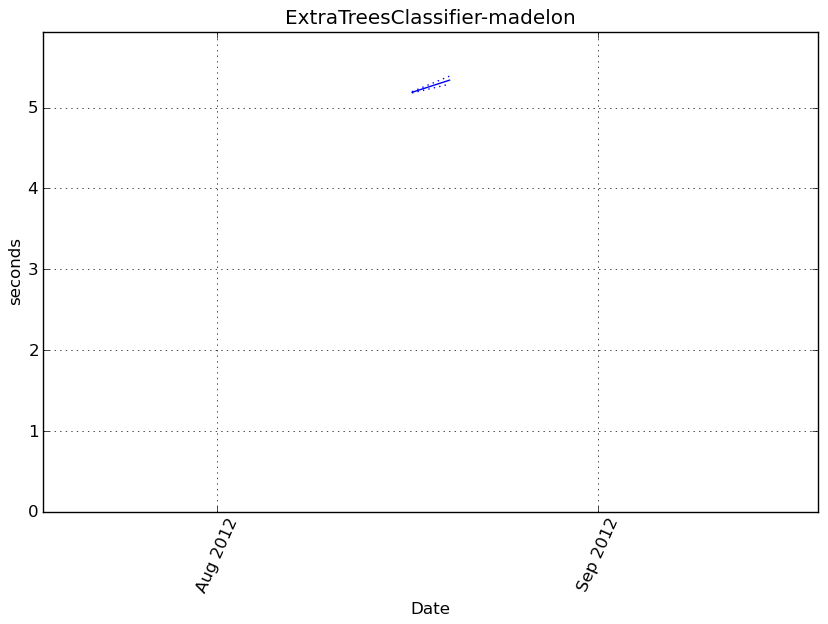
Execution time
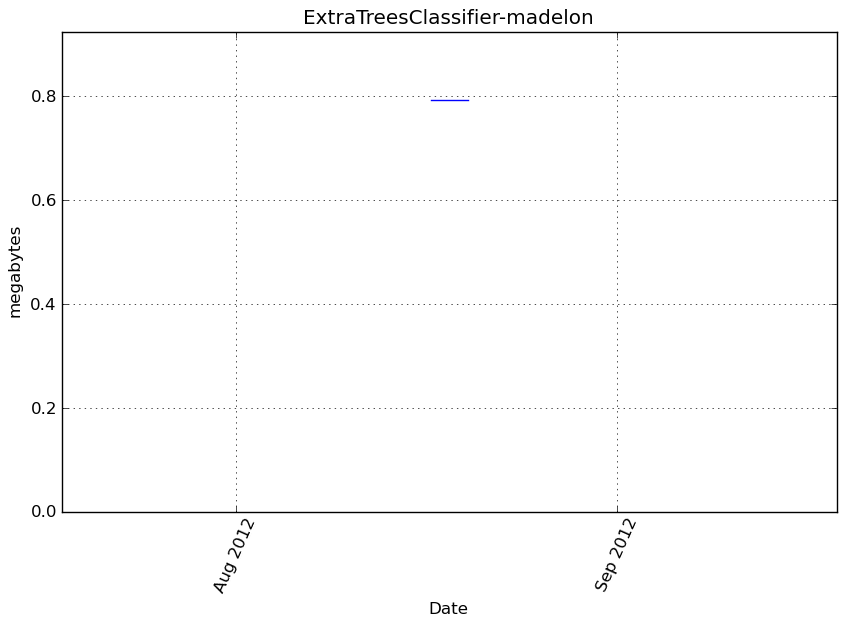
Memory usage
Additional output
cProfile
15409 function calls (15259 primitive calls) in 5.432 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 5.432 5.432 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 5.432 5.432 <f>:1(<module>)
1 0.000 0.000 5.432 5.432 /tmp/vb_sklearn/sklearn/ensemble/forest.py:211(fit)
2 0.000 0.000 5.419 2.710 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:430(__call__)
2 0.000 0.000 5.419 2.709 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:292(dispatch)
2 0.000 0.000 5.419 2.709 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:121(__init__)
1 0.000 0.000 5.265 5.265 /tmp/vb_sklearn/sklearn/ensemble/forest.py:62(_parallel_build_trees)
10 0.001 0.000 5.217 0.522 /tmp/vb_sklearn/sklearn/tree/tree.py:171(fit)
10 3.795 0.379 5.212 0.521 {method 'build' of 'sklearn.tree._tree.Tree' objects}
1522 0.006 0.000 1.540 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:598(argsort)
1522 1.534 0.001 1.534 0.001 {method 'argsort' of 'numpy.ndarray' objects}
1 0.000 0.000 0.153 0.153 /tmp/vb_sklearn/sklearn/ensemble/forest.py:146(_parallel_X_argsort)
10 0.000 0.000 0.046 0.005 /tmp/vb_sklearn/sklearn/ensemble/base.py:49(_make_estimator)
90/10 0.001 0.000 0.044 0.004 /tmp/vb_sklearn/sklearn/base.py:16(clone)
150/80 0.001 0.000 0.040 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:145(deepcopy)
10 0.000 0.000 0.038 0.004 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:306(_reconstruct)
10 0.036 0.004 0.036 0.004 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/random/__init__.py:93(__RandomState_ctor)
1571 0.021 0.000 0.021 0.000 {numpy.core.multiarray.array}
1522 0.005 0.000 0.014 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
24 0.000 0.000 0.014 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
1522 0.005 0.000 0.012 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:325(asfortranarray)
1 0.000 0.000 0.010 0.010 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
1522 0.005 0.000 0.005 0.000 {method 'fill' of 'numpy.ndarray' objects}
50 0.001 0.000 0.004 0.000 /tmp/vb_sklearn/sklearn/base.py:193(get_params)
1522 0.004 0.000 0.004 0.000 {numpy.core.multiarray.empty}
30 0.000 0.000 0.003 0.000 /tmp/vb_sklearn/sklearn/base.py:211(set_params)
50 0.000 0.000 0.003 0.000 /tmp/vb_sklearn/sklearn/base.py:164(_get_param_names)
11 0.001 0.000 0.003 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
50 0.000 0.000 0.002 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:801(getargspec)
12 0.002 0.000 0.002 0.000 {numpy.core.multiarray.concatenate}
1 0.000 0.000 0.001 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:228(hstack)
11 0.001 0.000 0.001 0.000 {method 'sort' of 'numpy.ndarray' objects}
50 0.001 0.000 0.001 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:741(getargs)
20 0.000 0.000 0.001 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:234(_deepcopy_tuple)
83 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
11 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:757(searchsorted)
11 0.001 0.000 0.001 0.000 {method 'searchsorted' of 'numpy.ndarray' objects}
83 0.001 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
150 0.001 0.000 0.001 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:267(_keep_alive)
10 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1774(amax)
350 0.001 0.000 0.001 0.000 {hasattr}
10 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:32(_wrapit)
592 0.001 0.000 0.001 0.000 {getattr}
10 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
10 0.000 0.000 0.000 0.000 {method '__reduce_ex__' of 'object' objects}
10 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/tree/tree.py:660(__init__)
10 0.000 0.000 0.000 0.000 {method 'sum' of 'numpy.ndarray' objects}
395 0.000 0.000 0.000 0.000 {isinstance}
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:101(delayed)
21 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:181(check_random_state)
10 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/tree/tree.py:436(__init__)
256 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:94(check_arrays)
12 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:6(atleast_1d)
10 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/tree/tree.py:144(__init__)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/forest.py:250(<genexpr>)
10 0.000 0.000 0.000 0.000 {method 'max' of 'numpy.ndarray' objects}
11 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:781(copy)
50 0.000 0.000 0.000 0.000 {method 'sort' of 'list' objects}
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/forest.py:281(<genexpr>)
50 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:67(ismethod)
80 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/base.py:56(<genexpr>)
310 0.000 0.000 0.000 0.000 {method 'get' of 'dict' objects}
2 0.000 0.000 0.000 0.000 {cPickle.dumps}
10 0.000 0.000 0.000 0.000 {method '__setstate__' of 'mtrand.RandomState' objects}
100 0.000 0.000 0.000 0.000 {built-in method __new__ of type object at 0x781380}
50 0.000 0.000 0.000 0.000 <string>:8(__new__)
70 0.000 0.000 0.000 0.000 {range}
410 0.000 0.000 0.000 0.000 {id}
96 0.000 0.000 0.000 0.000 {setattr}
13 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
11 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
52 0.000 0.000 0.000 0.000 {method 'pop' of 'list' objects}
171 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
50 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:209(iscode)
10 0.000 0.000 0.000 0.000 {method '__deepcopy__' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:390(retrieve)
50 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/inspect.py:142(isfunction)
20 0.000 0.000 0.000 0.000 {issubclass}
184 0.000 0.000 0.000 0.000 {len}
2 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/functools.py:17(update_wrapper)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/logger.py:39(short_format_time)
110 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/copy.py:198(_deepcopy_atomic)
1 0.000 0.000 0.000 0.000 {map}
20 0.000 0.000 0.000 0.000 {max}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/forest.py:151(_partition_features)
3 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:87(_num_samples)
40 0.000 0.000 0.000 0.000 {method 'iteritems' of 'dict' objects}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/forest.py:123(_partition_trees)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/logger.py:23(_squeeze_time)
10 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:449(isfortran)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:282(__init__)
11 0.000 0.000 0.000 0.000 {method 'randint' of 'mtrand.RandomState' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:289(ascontiguousarray)
2 0.000 0.000 0.000 0.000 /sp/lib/python/cpython-2.7.2/lib/python2.7/functools.py:39(wraps)
4 0.000 0.000 0.000 0.000 {time.time}
2 0.000 0.000 0.000 0.000 {min}
2 0.000 0.000 0.000 0.000 {method 'startswith' of 'str' objects}
2 0.000 0.000 0.000 0.000 {method 'update' of 'dict' objects}
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:108(delayed_function)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:337(_print)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:49(_verbosity_filter)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/externals/joblib/parallel.py:126(get)
4 0.000 0.000 0.000 0.000 {method 'pop' of 'dict' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/ensemble/forest.py
Function: fit at line 211
Total time: 5.38112 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
211 def fit(self, X, y):
212 """Build a forest of trees from the training set (X, y).
213
214 Parameters
215 ----------
216 X : array-like of shape = [n_samples, n_features]
217 The training input samples.
218
219 y : array-like, shape = [n_samples] or [n_samples, n_outputs]
220 The target values (integers that correspond to classes in
221 classification, real numbers in regression).
222
223 Returns
224 -------
225 self : object
226 Returns self.
227 """
228 # Precompute some data
229 1 142 142.0 0.0 X, y = check_arrays(X, y, sparse_format="dense")
230 1 11 11.0 0.0 if getattr(X, "dtype", None) != DTYPE or \
231 X.ndim != 2 or not X.flags.fortran:
232 1 21090 21090.0 0.4 X = array2d(X, dtype=DTYPE, order="F")
233
234 1 14 14.0 0.0 n_samples, self.n_features_ = X.shape
235
236 1 7 7.0 0.0 if self.bootstrap:
237 sample_mask = None
238 X_argsorted = None
239
240 else:
241 1 6 6.0 0.0 if self.oob_score:
242 raise ValueError("Out of bag estimation only available"
243 " if bootstrap=True")
244
245 1 43 43.0 0.0 sample_mask = np.ones((n_samples,), dtype=np.bool)
246
247 1 37 37.0 0.0 n_jobs, _, starts = _partition_features(self, self.n_features_)
248
249 1 26 26.0 0.0 all_X_argsorted = Parallel(n_jobs=n_jobs)(
250 1 8 8.0 0.0 delayed(_parallel_X_argsort)(
251 X[:, starts[i]:starts[i + 1]])
252 1 148770 148770.0 2.8 for i in xrange(n_jobs))
253
254 1 1300 1300.0 0.0 X_argsorted = np.asfortranarray(np.hstack(all_X_argsorted))
255
256 1 35 35.0 0.0 y = np.atleast_1d(y)
257 1 7 7.0 0.0 if y.ndim == 1:
258 1 17 17.0 0.0 y = y[:, np.newaxis]
259
260 1 8 8.0 0.0 self.classes_ = []
261 1 7 7.0 0.0 self.n_classes_ = []
262 1 8 8.0 0.0 self.n_outputs_ = y.shape[1]
263
264 1 11 11.0 0.0 if isinstance(self.base_estimator, ClassifierMixin):
265 1 34 34.0 0.0 y = np.copy(y)
266
267 2 18 9.0 0.0 for k in xrange(self.n_outputs_):
268 1 209 209.0 0.0 unique = np.unique(y[:, k])
269 1 10 10.0 0.0 self.classes_.append(unique)
270 1 8 8.0 0.0 self.n_classes_.append(unique.shape[0])
271 1 101 101.0 0.0 y[:, k] = np.searchsorted(unique, y[:, k])
272
273 1 11 11.0 0.0 if getattr(y, "dtype", None) != DTYPE or not y.flags.contiguous:
274 1 24 24.0 0.0 y = np.ascontiguousarray(y, dtype=DOUBLE)
275
276 # Assign chunk of trees to jobs
277 1 39 39.0 0.0 n_jobs, n_trees, _ = _partition_trees(self)
278
279 # Parallel loop
280 1 23 23.0 0.0 all_trees = Parallel(n_jobs=n_jobs, verbose=self.verbose)(
281 1 8 8.0 0.0 delayed(_parallel_build_trees)(
282 n_trees[i],
283 self,
284 X,
285 y,
286 sample_mask,
287 X_argsorted,
288 self.random_state.randint(MAX_INT),
289 verbose=self.verbose)
290 1 5208979 5208979.0 96.8 for i in xrange(n_jobs))
291
292 # Reduce
293 11 87 7.9 0.0 self.estimators_ = [tree for tree in itertools.chain(*all_trees)]
294
295 # Calculate out of bag predictions and score
296 1 7 7.0 0.0 if self.oob_score:
297 if isinstance(self, ClassifierMixin):
298 self.oob_decision_function_ = []
299 self.oob_score_ = 0.0
300
301 predictions = []
302 for k in xrange(self.n_outputs_):
303 predictions.append(np.zeros((n_samples,
304 self.n_classes_[k])))
305
306 for estimator in self.estimators_:
307 mask = np.ones(n_samples, dtype=np.bool)
308 mask[estimator.indices_] = False
309
310 p_estimator = estimator.predict_proba(X[mask, :])
311 if self.n_outputs_ == 1:
312 p_estimator = [p_estimator]
313
314 for k in xrange(self.n_outputs_):
315 predictions[k][mask, :] += p_estimator[k]
316
317 for k in xrange(self.n_outputs_):
318 if (predictions[k].sum(axis=1) == 0).any():
319 warn("Some inputs do not have OOB scores. "
320 "This probably means too few trees were used "
321 "to compute any reliable oob estimates.")
322 decision = predictions[k] \
323 / predictions[k].sum(axis=1)[:, np.newaxis]
324 self.oob_decision_function_.append(decision)
325
326 self.oob_score_ += np.mean(y[:, k] \
327 == np.argmax(predictions[k], axis=1))
328
329 if self.n_outputs_ == 1:
330 self.oob_decision_function_ = \
331 self.oob_decision_function_[0]
332
333 self.oob_score_ /= self.n_outputs_
334
335 else:
336 # Regression:
337 predictions = np.zeros((n_samples, self.n_outputs_))
338 n_predictions = np.zeros((n_samples, self.n_outputs_))
339
340 for estimator in self.estimators_:
341 mask = np.ones(n_samples, dtype=np.bool)
342 mask[estimator.indices_] = False
343
344 p_estimator = estimator.predict(X[mask, :])
345 if self.n_outputs_ == 1:
346 p_estimator = p_estimator[:, np.newaxis]
347
348 predictions[mask, :] += p_estimator
349 n_predictions[mask, :] += 1
350 if (n_predictions == 0).any():
351 warn("Some inputs do not have OOB scores. "
352 "This probably means too few trees were used "
353 "to compute any reliable oob estimates.")
354 n_predictions[n_predictions == 0] = 1
355 predictions /= n_predictions
356
357 self.oob_prediction_ = predictions
358 if self.n_outputs_ == 1:
359 self.oob_prediction_ = \
360 self.oob_prediction_.reshape((n_samples, ))
361
362 self.oob_score_ = 0.0
363 for k in xrange(self.n_outputs_):
364 self.oob_score_ += r2_score(y[:, k], predictions[:, k])
365 self.oob_score_ /= self.n_outputs_
366
367 # Sum the importances
368 1 7 7.0 0.0 if self.compute_importances:
369 self.feature_importances_ = \
370 sum(tree.feature_importances_ for tree in self.estimators_) \
371 / self.n_estimators
372
373 1 6 6.0 0.0 return self
GradientBoostingClassifier-arcene¶
Benchmark setup
from sklearn.ensemble import GradientBoostingClassifier from deps import load_data kwargs = {} X, y, X_t, y_t = load_data('arcene') obj = GradientBoostingClassifier(**kwargs)
Benchmark statement
obj.fit(X, y)
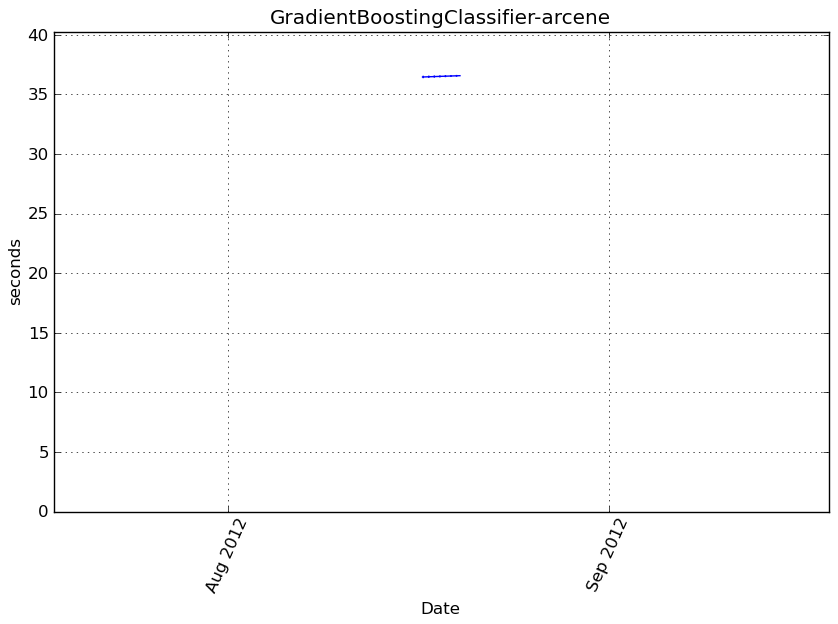
Execution time
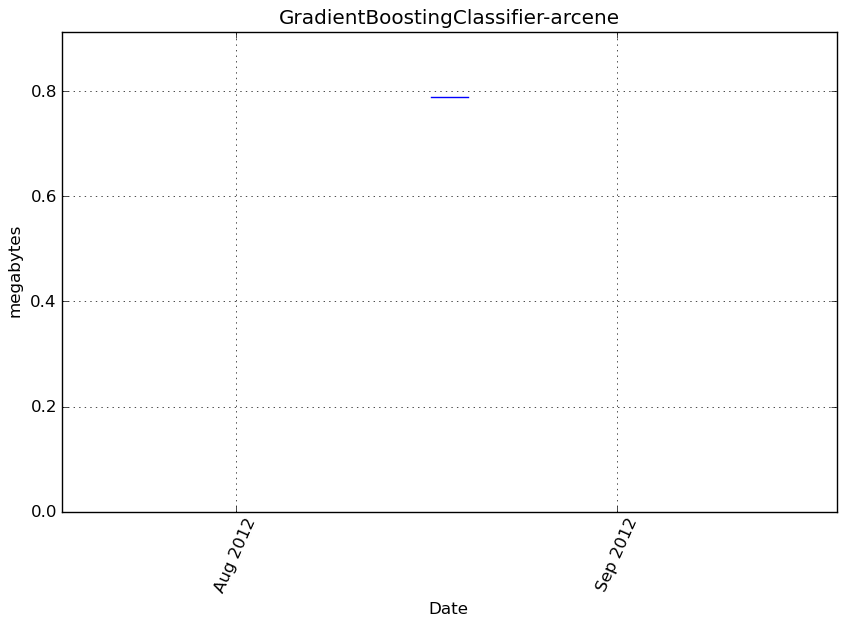
Memory usage
Additional output
cProfile
9021 function calls in 36.665 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 36.665 36.665 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 36.665 36.665 <f>:1(<module>)
1 0.000 0.000 36.665 36.665 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:735(fit)
1 0.001 0.001 36.665 36.665 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:507(fit)
100 0.006 0.000 36.564 0.366 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:478(fit_stage)
100 36.453 0.365 36.457 0.365 {method 'build' of 'sklearn.tree._tree.Tree' objects}
100 0.017 0.000 0.088 0.001 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:143(update_terminal_regions)
1 0.000 0.000 0.078 0.078 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:598(argsort)
1 0.078 0.078 0.078 0.078 {method 'argsort' of 'numpy.ndarray' objects}
781 0.045 0.000 0.067 0.000 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:352(_update_terminal_region)
205 0.015 0.000 0.015 0.000 {numpy.core.multiarray.array}
982 0.003 0.000 0.013 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
1763 0.013 0.000 0.013 0.000 {method 'sum' of 'numpy.ndarray' objects}
2 0.000 0.000 0.011 0.005 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:325(asfortranarray)
100 0.002 0.000 0.008 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1774(amax)
100 0.006 0.000 0.007 0.000 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:343(__call__)
100 0.001 0.000 0.006 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:32(_wrapit)
100 0.005 0.000 0.006 0.000 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:349(negative_gradient)
1662 0.005 0.000 0.005 0.000 {method 'take' of 'numpy.ndarray' objects}
203 0.001 0.000 0.005 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
881 0.004 0.000 0.004 0.000 {numpy.core.multiarray.where}
1 0.003 0.003 0.003 0.003 {method 'astype' of 'numpy.ndarray' objects}
984 0.002 0.000 0.002 0.000 {isinstance}
100 0.002 0.000 0.002 0.000 {method 'apply' of 'sklearn.tree._tree.Tree' objects}
100 0.001 0.000 0.001 0.000 {method 'max' of 'numpy.ndarray' objects}
100 0.001 0.000 0.001 0.000 {method 'copy' of 'numpy.ndarray' objects}
201 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
100 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:449(isfortran)
101 0.000 0.000 0.000 0.000 {range}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:94(check_arrays)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
100 0.000 0.000 0.000 0.000 {getattr}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:83(fit)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.concatenate}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1044(ravel)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:87(predict)
3 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
3 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:87(_num_samples)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:757(searchsorted)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
2 0.000 0.000 0.000 0.000 {numpy.core.multiarray.zeros}
1 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:333(__init__)
2 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'sort' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'searchsorted' of 'numpy.ndarray' objects}
6 0.000 0.000 0.000 0.000 {hasattr}
4 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
1 0.000 0.000 0.000 0.000 {max}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:340(init_estimator)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:121(__init__)
3 0.000 0.000 0.000 0.000 {len}
4 0.000 0.000 0.000 0.000 {method 'pop' of 'dict' objects}
2 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py
Function: fit at line 735
Total time: 36.8206 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
735 def fit(self, X, y):
736 """Fit the gradient boosting model.
737
738 Parameters
739 ----------
740 X : array-like, shape = [n_samples, n_features]
741 Training vectors, where n_samples is the number of samples
742 and n_features is the number of features. Use fortran-style
743 to avoid memory copies.
744
745 y : array-like, shape = [n_samples]
746 Target values (integers in classification, real numbers in
747 regression)
748 For classification, labels must correspond to classes
749 ``0, 1, ..., n_classes_-1``
750
751 Returns
752 -------
753 self : object
754 Returns self.
755 """
756 1 133 133.0 0.0 self.classes_ = np.unique(y)
757 1 4 4.0 0.0 self.n_classes_ = len(self.classes_)
758 1 17 17.0 0.0 y = np.searchsorted(self.classes_, y)
759 1 2 2.0 0.0 if self.loss == 'deviance':
760 1 3 3.0 0.0 self.loss = 'mdeviance' if len(self.classes_) > 2 else 'bdeviance'
761
762 1 36820484 36820484.0 100.0 return super(GradientBoostingClassifier, self).fit(X, y)
GradientBoostingClassifier-madelon¶
Benchmark setup
from sklearn.ensemble import GradientBoostingClassifier from deps import load_data kwargs = {} X, y, X_t, y_t = load_data('madelon') obj = GradientBoostingClassifier(**kwargs)
Benchmark statement
obj.fit(X, y)
Execution time
Memory usage
Additional output
cProfile
9117 function calls in 29.657 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 29.657 29.657 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 29.657 29.657 <f>:1(<module>)
1 0.000 0.000 29.657 29.657 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:735(fit)
1 0.002 0.002 29.656 29.656 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:507(fit)
100 0.006 0.000 29.460 0.295 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:478(fit_stage)
100 29.187 0.292 29.193 0.292 {method 'build' of 'sklearn.tree._tree.Tree' objects}
100 0.032 0.000 0.214 0.002 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:143(update_terminal_regions)
793 0.093 0.000 0.168 0.000 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:352(_update_terminal_region)
1 0.000 0.000 0.138 0.138 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:598(argsort)
1 0.138 0.138 0.138 0.138 {method 'argsort' of 'numpy.ndarray' objects}
100 0.040 0.000 0.043 0.000 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:343(__call__)
100 0.039 0.000 0.039 0.000 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:349(negative_gradient)
1787 0.039 0.000 0.039 0.000 {method 'sum' of 'numpy.ndarray' objects}
893 0.030 0.000 0.030 0.000 {numpy.core.multiarray.where}
994 0.003 0.000 0.016 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
205 0.014 0.000 0.014 0.000 {numpy.core.multiarray.array}
100 0.010 0.000 0.010 0.000 {method 'apply' of 'sklearn.tree._tree.Tree' objects}
2 0.000 0.000 0.010 0.005 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:325(asfortranarray)
1686 0.009 0.000 0.009 0.000 {method 'take' of 'numpy.ndarray' objects}
100 0.002 0.000 0.008 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1774(amax)
100 0.001 0.000 0.006 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:32(_wrapit)
203 0.001 0.000 0.005 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
1 0.004 0.004 0.004 0.004 {method 'astype' of 'numpy.ndarray' objects}
996 0.002 0.000 0.002 0.000 {isinstance}
100 0.001 0.000 0.001 0.000 {method 'max' of 'numpy.ndarray' objects}
100 0.001 0.000 0.001 0.000 {method 'copy' of 'numpy.ndarray' objects}
201 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
100 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:449(isfortran)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
101 0.000 0.000 0.000 0.000 {range}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:94(check_arrays)
100 0.000 0.000 0.000 0.000 {getattr}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:83(fit)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:757(searchsorted)
1 0.000 0.000 0.000 0.000 {method 'searchsorted' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'sort' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.concatenate}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:87(predict)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1044(ravel)
3 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
3 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:87(_num_samples)
2 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
2 0.000 0.000 0.000 0.000 {numpy.core.multiarray.zeros}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:333(__init__)
4 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
6 0.000 0.000 0.000 0.000 {hasattr}
1 0.000 0.000 0.000 0.000 {max}
3 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:340(init_estimator)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py:121(__init__)
4 0.000 0.000 0.000 0.000 {method 'pop' of 'dict' objects}
2 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/ensemble/gradient_boosting.py
Function: fit at line 735
Total time: 29.7849 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
735 def fit(self, X, y):
736 """Fit the gradient boosting model.
737
738 Parameters
739 ----------
740 X : array-like, shape = [n_samples, n_features]
741 Training vectors, where n_samples is the number of samples
742 and n_features is the number of features. Use fortran-style
743 to avoid memory copies.
744
745 y : array-like, shape = [n_samples]
746 Target values (integers in classification, real numbers in
747 regression)
748 For classification, labels must correspond to classes
749 ``0, 1, ..., n_classes_-1``
750
751 Returns
752 -------
753 self : object
754 Returns self.
755 """
756 1 235 235.0 0.0 self.classes_ = np.unique(y)
757 1 5 5.0 0.0 self.n_classes_ = len(self.classes_)
758 1 110 110.0 0.0 y = np.searchsorted(self.classes_, y)
759 1 5 5.0 0.0 if self.loss == 'deviance':
760 1 6 6.0 0.0 self.loss = 'mdeviance' if len(self.classes_) > 2 else 'bdeviance'
761
762 1 29784551 29784551.0 100.0 return super(GradientBoostingClassifier, self).fit(X, y)