Benchmarks for mixture¶
DPGMM-blobs¶
Benchmark setup
from sklearn.mixture import DPGMM from deps import load_data kwargs = {'n_components': 10, 'covariance_type': 'full'} X, y, X_t, y_t = load_data('blobs') obj = DPGMM(**kwargs)
Benchmark statement
obj.fit(X)
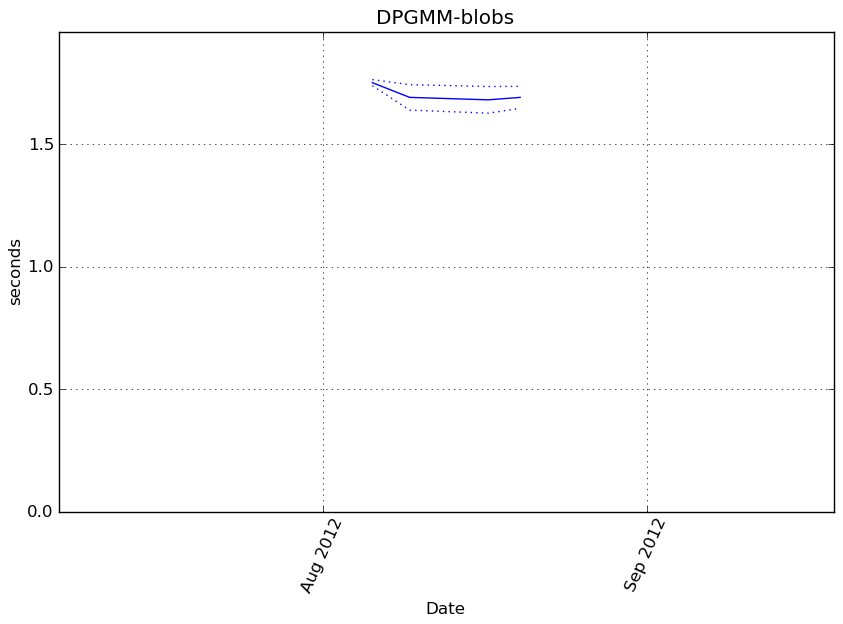
Execution time
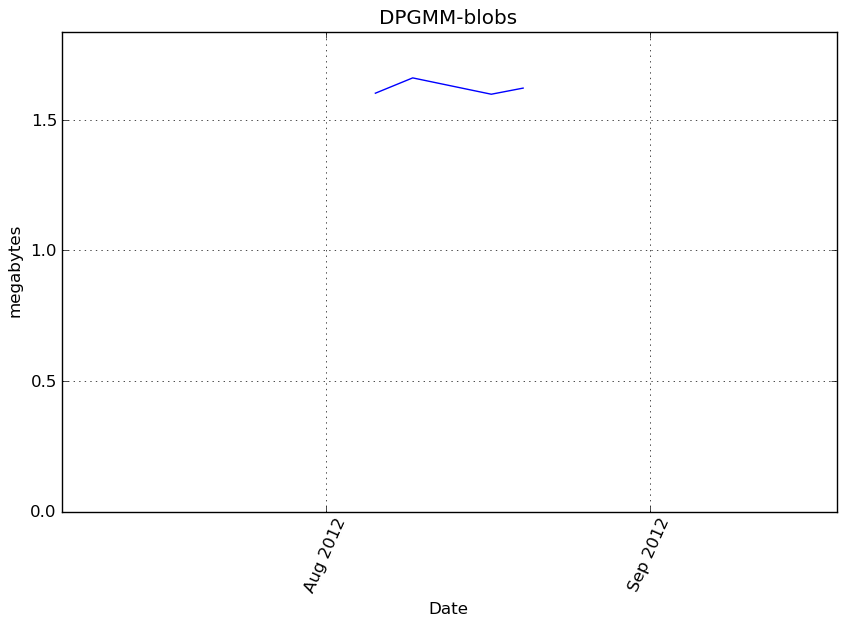
Memory usage
Additional output
cProfile
39554 function calls in 1.592 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 1.592 1.592 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 1.592 1.592 <f>:1(<module>)
1 0.001 0.001 1.592 1.592 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:472(fit)
10 0.000 0.000 1.124 0.112 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:372(_do_mstep)
200 0.847 0.004 0.895 0.004 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/basic.py:365(lstsq)
10 0.025 0.002 0.608 0.061 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:303(_update_precisions)
10 0.015 0.001 0.515 0.051 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:284(_update_means)
100 0.001 0.000 0.417 0.004 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/basic.py:457(pinv)
10 0.002 0.000 0.255 0.026 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:224(eval)
10 0.004 0.000 0.244 0.024 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:92(_bound_state_log_lik)
100 0.003 0.000 0.241 0.002 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:86(_sym_quad_form)
100 0.004 0.000 0.237 0.002 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/spatial/distance.py:1693(cdist)
100 0.222 0.002 0.222 0.002 {scipy.spatial._distance_wrap.cdist_mahalanobis_wrap}
1 0.000 0.000 0.165 0.165 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:738(fit)
1 0.000 0.000 0.165 0.165 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:151(k_means)
10 0.001 0.000 0.164 0.016 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:303(_kmeans_single)
320 0.154 0.000 0.154 0.000 {numpy.core._dotblas.dot}
10 0.000 0.000 0.103 0.010 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:525(_init_centroids)
10 0.013 0.001 0.102 0.010 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:36(_k_init)
120 0.014 0.000 0.100 0.001 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:101(euclidean_distances)
600 0.037 0.000 0.053 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:526(asarray_chkfinite)
10 0.000 0.000 0.044 0.004 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:450(_logprior)
120 0.001 0.000 0.039 0.000 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:52(check_pairwise_arrays)
10 0.000 0.000 0.035 0.003 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:414(_bound_precisions)
100 0.002 0.000 0.034 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:68(_bound_wishart)
120 0.002 0.000 0.033 0.000 /tmp/vb_sklearn/sklearn/utils/extmath.py:70(safe_sparse_dot)
20 0.024 0.001 0.033 0.002 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:478(_centers)
361 0.002 0.000 0.033 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
1972 0.032 0.000 0.032 0.000 {method 'sum' of 'numpy.ndarray' objects}
200 0.001 0.000 0.032 0.000 {map}
100 0.014 0.000 0.028 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/basic.py:336(det)
20 0.000 0.000 0.027 0.001 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:431(_labels_inertia)
20 0.006 0.000 0.026 0.001 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:414(_labels_inertia_precompute_dense)
601 0.007 0.000 0.023 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
200 0.012 0.000 0.021 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:58(wishart_logz)
1477 0.003 0.000 0.019 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
210 0.008 0.000 0.018 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:48(wishart_log_det)
970 0.003 0.000 0.017 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
1477 0.011 0.000 0.017 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
240 0.001 0.000 0.015 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:23(safe_asarray)
1400 0.015 0.000 0.015 0.000 {method 'any' of 'numpy.ndarray' objects}
1932 0.004 0.000 0.014 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
361 0.002 0.000 0.012 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
2294 0.011 0.000 0.011 0.000 {numpy.core.multiarray.array}
430 0.008 0.000 0.011 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:28(digamma)
200 0.003 0.000 0.009 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/lapack.py:60(get_lapack_funcs)
240 0.005 0.000 0.007 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:32(gammaln)
10 0.003 0.000 0.007 0.001 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:36(log_normalize)
300 0.001 0.000 0.007 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/spatial/distance.py:132(_copy_arrays_if_base_present)
420 0.004 0.000 0.006 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1830(identity)
300 0.001 0.000 0.006 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/spatial/distance.py:120(_copy_array_if_base_present)
202 0.006 0.000 0.006 0.000 {method 'mean' of 'numpy.ndarray' objects}
361 0.003 0.000 0.006 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
300 0.001 0.000 0.005 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numerictypes.py:703(issubsctype)
200 0.002 0.000 0.005 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/lapack.py:45(find_best_lapack_type)
210 0.001 0.000 0.005 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:986(trace)
690 0.002 0.000 0.005 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/getlimits.py:91(__new__)
3523 0.004 0.000 0.004 0.000 {isinstance}
10 0.003 0.000 0.004 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:437(_bound_proportions)
10 0.001 0.000 0.004 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:390(_bound_concentration)
3354 0.004 0.000 0.004 0.000 {method 'split' of 'str' objects}
600 0.002 0.000 0.004 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numerictypes.py:608(obj2sctype)
210 0.003 0.000 0.003 0.000 {method 'trace' of 'numpy.ndarray' objects}
10 0.002 0.000 0.003 0.000 /tmp/vb_sklearn/sklearn/utils/extmath.py:210(logsumexp)
551 0.003 0.000 0.003 0.000 {numpy.core.multiarray.zeros}
710 0.002 0.000 0.002 0.000 {method 'get' of 'dict' objects}
100 0.001 0.000 0.002 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/flinalg.py:24(get_flinalg_funcs)
361 0.001 0.000 0.002 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
200 0.000 0.000 0.002 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1508(any)
1700 0.002 0.000 0.002 0.000 {issubclass}
410 0.002 0.000 0.002 0.000 {numpy.core.multiarray.arange}
400 0.001 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/lapack.py:23(cast_to_lapack_prefix)
100 0.001 0.000 0.001 0.000 {method 'cumsum' of 'numpy.ndarray' objects}
200 0.001 0.000 0.001 0.000 {method 'astype' of 'numpy.generic' objects}
500 0.001 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/spatial/distance.py:151(_convert_to_double)
202 0.001 0.000 0.001 0.000 {method 'reshape' of 'numpy.ndarray' objects}
620 0.001 0.000 0.001 0.000 {getattr}
20 0.001 0.000 0.001 0.000 {method 'max' of 'numpy.ndarray' objects}
90 0.001 0.000 0.001 0.000 {method 'random_sample' of 'mtrand.RandomState' objects}
10 0.001 0.000 0.001 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:275(_update_concentration)
1181 0.001 0.000 0.001 0.000 {method 'append' of 'list' objects}
10 0.000 0.000 0.001 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:407(_bound_means)
10 0.000 0.000 0.001 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:24(sqnorm)
2324 0.001 0.000 0.001 0.000 {len}
361 0.001 0.000 0.001 0.000 {range}
10 0.000 0.000 0.001 0.000 /tmp/vb_sklearn/sklearn/utils/extmath.py:15(norm)
90 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:757(searchsorted)
104 0.001 0.000 0.001 0.000 {numpy.core.multiarray.empty}
1 0.000 0.000 0.001 0.001 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:142(_tolerance)
300 0.000 0.000 0.000 0.000 {method 'sort' of 'list' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:2470(var)
1 0.000 0.000 0.000 0.000 {method 'var' of 'numpy.ndarray' objects}
74 0.000 0.000 0.000 0.000 {method 'copy' of 'numpy.ndarray' objects}
90 0.000 0.000 0.000 0.000 {method 'searchsorted' of 'numpy.ndarray' objects}
24 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
10 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/blas.py:30(get_blas_funcs)
10 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1643(cumsum)
74 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
200 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:449(isfortran)
500 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/misc.py:22(_datacopied)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:710(_check_fit_data)
20 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1069(rollaxis)
33 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:181(check_random_state)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:404(_squared_norms)
100 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/flinalg.py:19(has_column_major_storage)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:33(as_float_array)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/shape_base.py:766(tile)
100 0.000 0.000 0.000 0.000 {method 'lower' of 'str' objects}
10 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:397(swapaxes)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:386(_initialize_gamma)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:690(__init__)
40 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:359(_monitor)
10 0.000 0.000 0.000 0.000 {method 'swapaxes' of 'numpy.ndarray' objects}
100 0.000 0.000 0.000 0.000 {callable}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:2299(mean)
10 0.000 0.000 0.000 0.000 {method 'remove' of 'list' objects}
10 0.000 0.000 0.000 0.000 {method 'transpose' of 'numpy.ndarray' objects}
10 0.000 0.000 0.000 0.000 {method 'randint' of 'mtrand.RandomState' objects}
12 0.000 0.000 0.000 0.000 {max}
2 0.000 0.000 0.000 0.000 {hasattr}
10 0.000 0.000 0.000 0.000 {method 'insert' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'repeat' of 'numpy.ndarray' objects}
9 0.000 0.000 0.000 0.000 {abs}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/mixture/dpgmm.py
Function: fit at line 472
Total time: 2.04353 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
472 def fit(self, X, **kwargs):
473 """Estimate model parameters with the variational
474 algorithm.
475
476 For a full derivation and description of the algorithm see
477 doc/dp-derivation/dp-derivation.tex
478
479 A initialization step is performed before entering the em
480 algorithm. If you want to avoid this step, set the keyword
481 argument init_params to the empty string '' when when creating
482 the object. Likewise, if you would like just to do an
483 initialization, set n_iter=0.
484
485 Parameters
486 ----------
487 X : array_like, shape (n, n_features)
488 List of n_features-dimensional data points. Each row
489 corresponds to a single data point.
490 """
491 1 8 8.0 0.0 self.random_state = check_random_state(self.random_state)
492 1 3 3.0 0.0 if kwargs:
493 warnings.warn("Setting parameters in the 'fit' method is"
494 "deprecated. Set it on initialization instead.",
495 DeprecationWarning)
496 # initialisations for in case the user still adds parameters to fit
497 # so things don't break
498 if 'n_iter' in kwargs:
499 self.n_iter = kwargs['n_iter']
500 if 'params' in kwargs:
501 self.params = kwargs['params']
502 if 'init_params' in kwargs:
503 self.init_params = kwargs['init_params']
504
505 ## initialization step
506 1 8 8.0 0.0 X = np.asarray(X)
507 1 3 3.0 0.0 if X.ndim == 1:
508 X = X[:, np.newaxis]
509
510 1 3 3.0 0.0 n_features = X.shape[1]
511 1 15 15.0 0.0 z = np.ones((X.shape[0], self.n_components))
512 1 46 46.0 0.0 z /= self.n_components
513
514 1 14 14.0 0.0 self._initial_bound = - 0.5 * n_features * np.log(2 * np.pi)
515 1 9 9.0 0.0 self._initial_bound -= np.log(2 * np.pi * np.e)
516
517 1 3 3.0 0.0 if (self.init_params != '') or not hasattr(self, 'gamma_'):
518 1 20 20.0 0.0 self._initialize_gamma()
519
520 1 3 3.0 0.0 if 'm' in self.init_params or not hasattr(self, 'means_'):
521 1 3 3.0 0.0 self.means_ = cluster.KMeans(
522 1 2 2.0 0.0 n_clusters=self.n_components,
523 1 231420 231420.0 11.3 random_state=self.random_state).fit(X).cluster_centers_[::-1]
524
525 1 4 4.0 0.0 if 'w' in self.init_params or not hasattr(self, 'weights_'):
526 1 72 72.0 0.0 self.weights_ = np.tile(1.0 / self.n_components, self.n_components)
527
528 1 4 4.0 0.0 if 'c' in self.init_params or not hasattr(self, 'precs_'):
529 1 2 2.0 0.0 if self.covariance_type == 'spherical':
530 self.dof_ = np.ones(self.n_components)
531 self.scale_ = np.ones(self.n_components)
532 self.precs_ = np.ones((self.n_components, n_features))
533 self.bound_prec_ = 0.5 * n_features * (
534 digamma(self.dof_) - np.log(self.scale_))
535 1 2 2.0 0.0 elif self.covariance_type == 'diag':
536 self.dof_ = 1 + 0.5 * n_features
537 self.dof_ *= np.ones((self.n_components, n_features))
538 self.scale_ = np.ones((self.n_components, n_features))
539 self.precs_ = np.ones((self.n_components, n_features))
540 self.bound_prec_ = 0.5 * (np.sum(digamma(self.dof_) -
541 np.log(self.scale_), 1))
542 self.bound_prec_ -= 0.5 * np.sum(self.precs_, 1)
543 1 3 3.0 0.0 elif self.covariance_type == 'tied':
544 self.dof_ = 1.
545 self.scale_ = np.identity(n_features)
546 self.precs_ = np.identity(n_features)
547 self.det_scale_ = 1.
548 self.bound_prec_ = 0.5 * wishart_log_det(
549 self.dof_, self.scale_, self.det_scale_, n_features)
550 self.bound_prec_ -= 0.5 * self.dof_ * np.trace(self.scale_)
551 1 3 3.0 0.0 elif self.covariance_type == 'full':
552 1 4 4.0 0.0 self.dof_ = (1 + self.n_components + X.shape[0])
553 1 25 25.0 0.0 self.dof_ *= np.ones(self.n_components)
554 1 3 3.0 0.0 self.scale_ = [2 * np.identity(n_features)
555 11 309 28.1 0.0 for i in xrange(self.n_components)]
556 1 3 3.0 0.0 self.precs_ = [np.identity(n_features)
557 11 123 11.2 0.0 for i in xrange(self.n_components)]
558 1 12 12.0 0.0 self.det_scale_ = np.ones(self.n_components)
559 1 6 6.0 0.0 self.bound_prec_ = np.zeros(self.n_components)
560 11 34 3.1 0.0 for k in xrange(self.n_components):
561 10 23 2.3 0.0 self.bound_prec_[k] = wishart_log_det(
562 10 36 3.6 0.0 self.dof_[k], self.scale_[k], self.det_scale_[k],
563 10 671 67.1 0.0 n_features)
564 10 36 3.6 0.0 self.bound_prec_[k] -= (self.dof_[k] *
565 10 203 20.3 0.0 np.trace(self.scale_[k]))
566 1 9 9.0 0.0 self.bound_prec_ *= 0.5
567
568 1 2 2.0 0.0 logprob = []
569 # reset self.converged_ to False
570 1 3 3.0 0.0 self.converged_ = False
571 11 69 6.3 0.0 for i in xrange(self.n_iter):
572 # Expectation step
573 10 381361 38136.1 18.7 curr_logprob, z = self.eval(X)
574 10 69378 6937.8 3.4 logprob.append(curr_logprob.sum() + self._logprior(z))
575
576 # Check for convergence.
577 10 140 14.0 0.0 if i > 0 and abs(logprob[-1] - logprob[-2]) < self.thresh:
578 self.converged_ = True
579 break
580
581 # Maximization step
582 10 1359431 135943.1 66.5 self._do_mstep(X, z, self.params)
583
584 1 4 4.0 0.0 return self
File: /tmp/vb_sklearn/sklearn/mixture/gmm.py
Function: predict at line 353
Total time: 0 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
353 def predict(self, X):
354 """Predict label for data.
355
356 Parameters
357 ----------
358 X : array-like, shape = [n_samples, n_features]
359
360 Returns
361 -------
362 C : array, shape = (n_samples,)
363 """
364 logprob, responsibilities = self.eval(X)
365 return responsibilities.argmax(axis=1)
Benchmark statement
obj.predict(X_t)
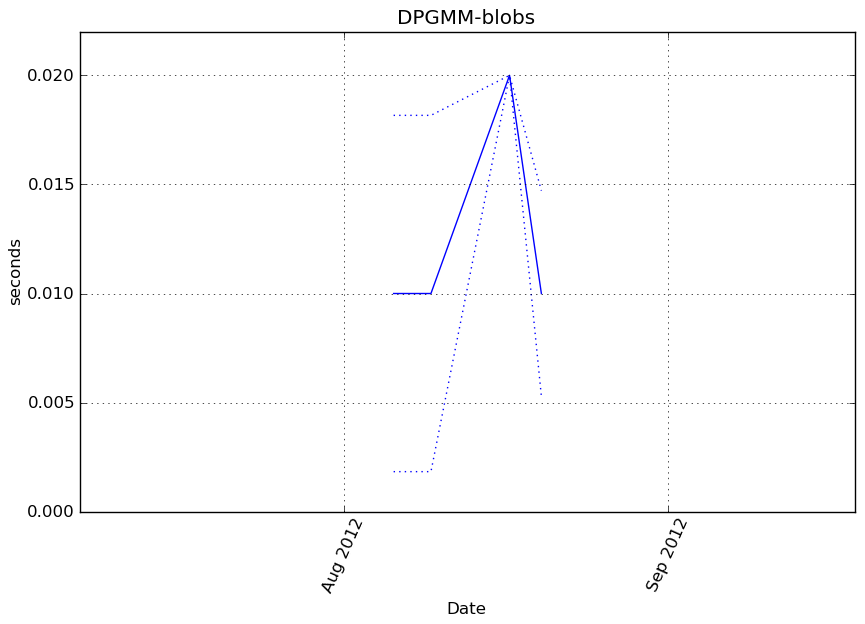
Execution time
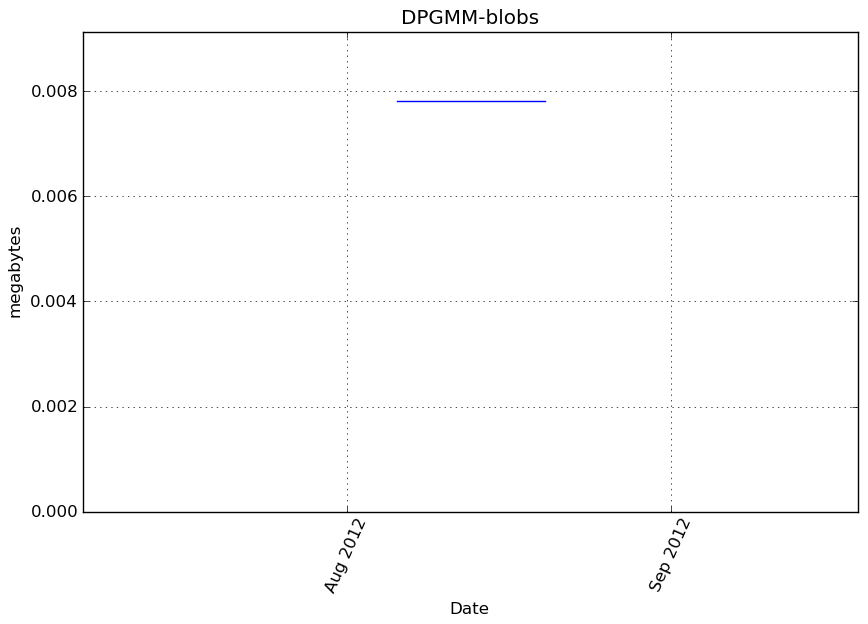
Memory usage
Additional output
cProfile
615 function calls in 0.010 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.010 0.010 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 0.010 0.010 <f>:1(<module>)
1 0.000 0.000 0.010 0.010 /tmp/vb_sklearn/sklearn/mixture/gmm.py:353(predict)
1 0.000 0.000 0.010 0.010 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:224(eval)
1 0.000 0.000 0.009 0.009 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:92(_bound_state_log_lik)
10 0.000 0.000 0.009 0.001 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:86(_sym_quad_form)
10 0.000 0.000 0.008 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/spatial/distance.py:1693(cdist)
10 0.007 0.001 0.007 0.001 {scipy.spatial._distance_wrap.cdist_mahalanobis_wrap}
30 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/spatial/distance.py:132(_copy_arrays_if_base_present)
30 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/spatial/distance.py:120(_copy_array_if_base_present)
30 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numerictypes.py:703(issubsctype)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:36(log_normalize)
60 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numerictypes.py:608(obj2sctype)
31 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
31 0.000 0.000 0.000 0.000 {numpy.core.multiarray.array}
13 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:28(digamma)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/extmath.py:210(logsumexp)
50 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/spatial/distance.py:151(_convert_to_double)
90 0.000 0.000 0.000 0.000 {issubclass}
14 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/getlimits.py:91(__new__)
3 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
103 0.000 0.000 0.000 0.000 {isinstance}
2 0.000 0.000 0.000 0.000 {method 'max' of 'numpy.ndarray' objects}
10 0.000 0.000 0.000 0.000 {method 'reshape' of 'numpy.ndarray' objects}
3 0.000 0.000 0.000 0.000 {method 'sum' of 'numpy.ndarray' objects}
12 0.000 0.000 0.000 0.000 {numpy.core.multiarray.zeros}
14 0.000 0.000 0.000 0.000 {method 'get' of 'dict' objects}
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1069(rollaxis)
1 0.000 0.000 0.000 0.000 {method 'copy' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:397(swapaxes)
10 0.000 0.000 0.000 0.000 {method 'lower' of 'str' objects}
20 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
1 0.000 0.000 0.000 0.000 {method 'remove' of 'list' objects}
10 0.000 0.000 0.000 0.000 {callable}
1 0.000 0.000 0.000 0.000 {range}
1 0.000 0.000 0.000 0.000 {method 'swapaxes' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'transpose' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'insert' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/mixture/dpgmm.py
Function: fit at line 472
Total time: 2.04353 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
472 def fit(self, X, **kwargs):
473 """Estimate model parameters with the variational
474 algorithm.
475
476 For a full derivation and description of the algorithm see
477 doc/dp-derivation/dp-derivation.tex
478
479 A initialization step is performed before entering the em
480 algorithm. If you want to avoid this step, set the keyword
481 argument init_params to the empty string '' when when creating
482 the object. Likewise, if you would like just to do an
483 initialization, set n_iter=0.
484
485 Parameters
486 ----------
487 X : array_like, shape (n, n_features)
488 List of n_features-dimensional data points. Each row
489 corresponds to a single data point.
490 """
491 1 8 8.0 0.0 self.random_state = check_random_state(self.random_state)
492 1 3 3.0 0.0 if kwargs:
493 warnings.warn("Setting parameters in the 'fit' method is"
494 "deprecated. Set it on initialization instead.",
495 DeprecationWarning)
496 # initialisations for in case the user still adds parameters to fit
497 # so things don't break
498 if 'n_iter' in kwargs:
499 self.n_iter = kwargs['n_iter']
500 if 'params' in kwargs:
501 self.params = kwargs['params']
502 if 'init_params' in kwargs:
503 self.init_params = kwargs['init_params']
504
505 ## initialization step
506 1 8 8.0 0.0 X = np.asarray(X)
507 1 3 3.0 0.0 if X.ndim == 1:
508 X = X[:, np.newaxis]
509
510 1 3 3.0 0.0 n_features = X.shape[1]
511 1 15 15.0 0.0 z = np.ones((X.shape[0], self.n_components))
512 1 46 46.0 0.0 z /= self.n_components
513
514 1 14 14.0 0.0 self._initial_bound = - 0.5 * n_features * np.log(2 * np.pi)
515 1 9 9.0 0.0 self._initial_bound -= np.log(2 * np.pi * np.e)
516
517 1 3 3.0 0.0 if (self.init_params != '') or not hasattr(self, 'gamma_'):
518 1 20 20.0 0.0 self._initialize_gamma()
519
520 1 3 3.0 0.0 if 'm' in self.init_params or not hasattr(self, 'means_'):
521 1 3 3.0 0.0 self.means_ = cluster.KMeans(
522 1 2 2.0 0.0 n_clusters=self.n_components,
523 1 231420 231420.0 11.3 random_state=self.random_state).fit(X).cluster_centers_[::-1]
524
525 1 4 4.0 0.0 if 'w' in self.init_params or not hasattr(self, 'weights_'):
526 1 72 72.0 0.0 self.weights_ = np.tile(1.0 / self.n_components, self.n_components)
527
528 1 4 4.0 0.0 if 'c' in self.init_params or not hasattr(self, 'precs_'):
529 1 2 2.0 0.0 if self.covariance_type == 'spherical':
530 self.dof_ = np.ones(self.n_components)
531 self.scale_ = np.ones(self.n_components)
532 self.precs_ = np.ones((self.n_components, n_features))
533 self.bound_prec_ = 0.5 * n_features * (
534 digamma(self.dof_) - np.log(self.scale_))
535 1 2 2.0 0.0 elif self.covariance_type == 'diag':
536 self.dof_ = 1 + 0.5 * n_features
537 self.dof_ *= np.ones((self.n_components, n_features))
538 self.scale_ = np.ones((self.n_components, n_features))
539 self.precs_ = np.ones((self.n_components, n_features))
540 self.bound_prec_ = 0.5 * (np.sum(digamma(self.dof_) -
541 np.log(self.scale_), 1))
542 self.bound_prec_ -= 0.5 * np.sum(self.precs_, 1)
543 1 3 3.0 0.0 elif self.covariance_type == 'tied':
544 self.dof_ = 1.
545 self.scale_ = np.identity(n_features)
546 self.precs_ = np.identity(n_features)
547 self.det_scale_ = 1.
548 self.bound_prec_ = 0.5 * wishart_log_det(
549 self.dof_, self.scale_, self.det_scale_, n_features)
550 self.bound_prec_ -= 0.5 * self.dof_ * np.trace(self.scale_)
551 1 3 3.0 0.0 elif self.covariance_type == 'full':
552 1 4 4.0 0.0 self.dof_ = (1 + self.n_components + X.shape[0])
553 1 25 25.0 0.0 self.dof_ *= np.ones(self.n_components)
554 1 3 3.0 0.0 self.scale_ = [2 * np.identity(n_features)
555 11 309 28.1 0.0 for i in xrange(self.n_components)]
556 1 3 3.0 0.0 self.precs_ = [np.identity(n_features)
557 11 123 11.2 0.0 for i in xrange(self.n_components)]
558 1 12 12.0 0.0 self.det_scale_ = np.ones(self.n_components)
559 1 6 6.0 0.0 self.bound_prec_ = np.zeros(self.n_components)
560 11 34 3.1 0.0 for k in xrange(self.n_components):
561 10 23 2.3 0.0 self.bound_prec_[k] = wishart_log_det(
562 10 36 3.6 0.0 self.dof_[k], self.scale_[k], self.det_scale_[k],
563 10 671 67.1 0.0 n_features)
564 10 36 3.6 0.0 self.bound_prec_[k] -= (self.dof_[k] *
565 10 203 20.3 0.0 np.trace(self.scale_[k]))
566 1 9 9.0 0.0 self.bound_prec_ *= 0.5
567
568 1 2 2.0 0.0 logprob = []
569 # reset self.converged_ to False
570 1 3 3.0 0.0 self.converged_ = False
571 11 69 6.3 0.0 for i in xrange(self.n_iter):
572 # Expectation step
573 10 381361 38136.1 18.7 curr_logprob, z = self.eval(X)
574 10 69378 6937.8 3.4 logprob.append(curr_logprob.sum() + self._logprior(z))
575
576 # Check for convergence.
577 10 140 14.0 0.0 if i > 0 and abs(logprob[-1] - logprob[-2]) < self.thresh:
578 self.converged_ = True
579 break
580
581 # Maximization step
582 10 1359431 135943.1 66.5 self._do_mstep(X, z, self.params)
583
584 1 4 4.0 0.0 return self
File: /tmp/vb_sklearn/sklearn/mixture/gmm.py
Function: predict at line 353
Total time: 0.019285 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
353 def predict(self, X):
354 """Predict label for data.
355
356 Parameters
357 ----------
358 X : array-like, shape = [n_samples, n_features]
359
360 Returns
361 -------
362 C : array, shape = (n_samples,)
363 """
364 1 19246 19246.0 99.8 logprob, responsibilities = self.eval(X)
365 1 39 39.0 0.2 return responsibilities.argmax(axis=1)
GMM-blobs¶
Benchmark setup
from sklearn.mixture import GMM from deps import load_data kwargs = {'n_components': 10, 'covariance_type': 'full'} X, y, X_t, y_t = load_data('blobs') obj = GMM(**kwargs)
Benchmark statement
obj.fit(X)
Execution time
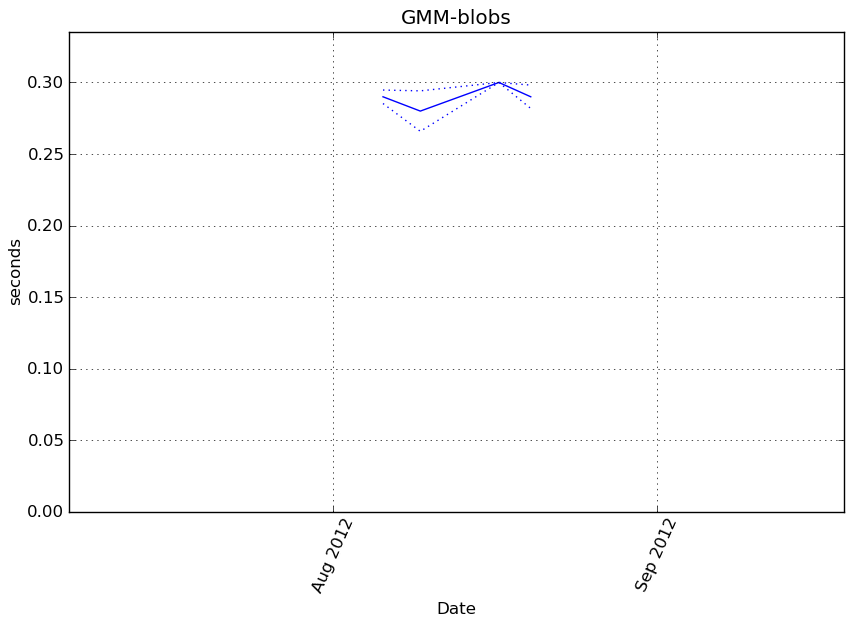
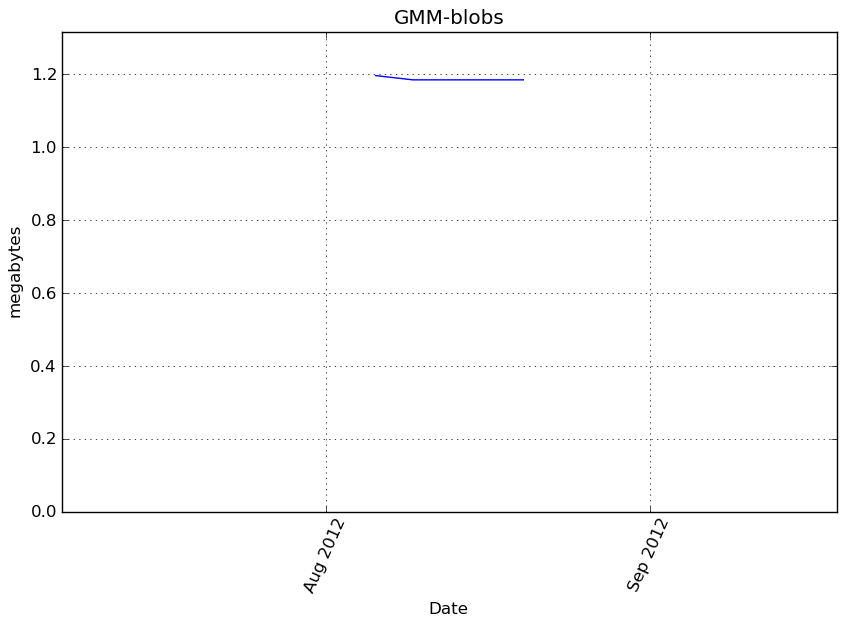
Memory usage
Additional output
cProfile
19389 function calls in 0.299 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.299 0.299 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 0.299 0.299 <f>:1(<module>)
1 0.000 0.000 0.299 0.299 /tmp/vb_sklearn/sklearn/mixture/gmm.py:434(fit)
1 0.000 0.000 0.166 0.166 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:738(fit)
1 0.000 0.000 0.166 0.166 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:151(k_means)
10 0.001 0.000 0.164 0.016 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:303(_kmeans_single)
10 0.000 0.000 0.103 0.010 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:525(_init_centroids)
10 0.013 0.001 0.103 0.010 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:36(_k_init)
120 0.014 0.000 0.100 0.001 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:101(euclidean_distances)
4 0.001 0.000 0.092 0.023 /tmp/vb_sklearn/sklearn/mixture/gmm.py:275(eval)
4 0.000 0.000 0.089 0.022 /tmp/vb_sklearn/sklearn/mixture/gmm.py:23(log_multivariate_normal_density)
4 0.011 0.003 0.089 0.022 /tmp/vb_sklearn/sklearn/mixture/gmm.py:626(_log_multivariate_normal_density_full)
40 0.031 0.001 0.061 0.002 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/basic.py:72(solve_triangular)
184 0.059 0.000 0.059 0.000 {numpy.core._dotblas.dot}
3 0.000 0.000 0.039 0.013 /tmp/vb_sklearn/sklearn/mixture/gmm.py:527(_do_mstep)
120 0.001 0.000 0.039 0.000 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:52(check_pairwise_arrays)
3 0.008 0.003 0.038 0.013 /tmp/vb_sklearn/sklearn/mixture/gmm.py:729(_covar_mstep_full)
20 0.025 0.001 0.033 0.002 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:478(_centers)
120 0.024 0.000 0.033 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:526(asarray_chkfinite)
120 0.002 0.000 0.033 0.000 /tmp/vb_sklearn/sklearn/utils/extmath.py:70(safe_sparse_dot)
361 0.002 0.000 0.033 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
40 0.000 0.000 0.028 0.001 {map}
20 0.000 0.000 0.027 0.001 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:431(_labels_inertia)
1256 0.026 0.000 0.026 0.000 {method 'sum' of 'numpy.ndarray' objects}
20 0.006 0.000 0.026 0.001 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:414(_labels_inertia_precompute_dense)
601 0.007 0.000 0.023 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
1477 0.003 0.000 0.020 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
1477 0.011 0.000 0.017 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
240 0.001 0.000 0.015 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:23(safe_asarray)
40 0.000 0.000 0.013 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/decomp_cholesky.py:30(cholesky)
40 0.006 0.000 0.013 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/decomp_cholesky.py:13(_cholesky)
361 0.002 0.000 0.012 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
440 0.009 0.000 0.009 0.000 {method 'any' of 'numpy.ndarray' objects}
224 0.001 0.000 0.006 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
203 0.006 0.000 0.006 0.000 {method 'mean' of 'numpy.ndarray' objects}
361 0.003 0.000 0.006 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
80 0.001 0.000 0.004 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/lapack.py:60(get_lapack_funcs)
3114 0.004 0.000 0.004 0.000 {method 'split' of 'str' objects}
766 0.002 0.000 0.004 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
1130 0.003 0.000 0.003 0.000 {numpy.core.multiarray.array}
1765 0.003 0.000 0.003 0.000 {isinstance}
80 0.001 0.000 0.002 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/lapack.py:45(find_best_lapack_type)
361 0.001 0.000 0.002 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
200 0.000 0.000 0.002 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1508(any)
4 0.001 0.000 0.002 0.000 /tmp/vb_sklearn/sklearn/utils/extmath.py:210(logsumexp)
1 0.000 0.000 0.001 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:1888(cov)
90 0.001 0.000 0.001 0.000 {method 'cumsum' of 'numpy.ndarray' objects}
40 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:902(diagonal)
90 0.001 0.000 0.001 0.000 {method 'random_sample' of 'mtrand.RandomState' objects}
31 0.001 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/twodim_base.py:169(eye)
90 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:757(searchsorted)
120 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/lapack.py:23(cast_to_lapack_prefix)
1 0.000 0.000 0.001 0.001 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:142(_tolerance)
30 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:2036(seterr)
97 0.001 0.000 0.001 0.000 {numpy.core.multiarray.empty}
1489 0.001 0.000 0.001 0.000 {len}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:2470(var)
1 0.000 0.000 0.000 0.000 {method 'var' of 'numpy.ndarray' objects}
90 0.000 0.000 0.000 0.000 {method 'searchsorted' of 'numpy.ndarray' objects}
565 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
40 0.000 0.000 0.000 0.000 {method 'diagonal' of 'numpy.ndarray' objects}
41 0.000 0.000 0.000 0.000 {numpy.core.multiarray.zeros}
64 0.000 0.000 0.000 0.000 {method 'copy' of 'numpy.ndarray' objects}
136 0.000 0.000 0.000 0.000 {range}
20 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:710(_check_fit_data)
240 0.000 0.000 0.000 0.000 {issubclass}
60 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
120 0.000 0.000 0.000 0.000 {getattr}
4 0.000 0.000 0.000 0.000 {method 'max' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/shape_base.py:766(tile)
30 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:2132(geterr)
32 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:181(check_random_state)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:404(_squared_norms)
80 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:449(isfortran)
80 0.000 0.000 0.000 0.000 {method 'sort' of 'list' objects}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/mixture/gmm.py:695(distribute_covar_matrix_to_match_covariance_type)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:33(as_float_array)
2 0.000 0.000 0.000 0.000 {method 'repeat' of 'numpy.ndarray' objects}
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1069(rollaxis)
30 0.000 0.000 0.000 0.000 {numpy.core.umath.seterrobj}
80 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/misc.py:22(_datacopied)
60 0.000 0.000 0.000 0.000 {numpy.core.umath.geterrobj}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:690(__init__)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:2299(mean)
40 0.000 0.000 0.000 0.000 {method 'get' of 'dict' objects}
10 0.000 0.000 0.000 0.000 {method 'randint' of 'mtrand.RandomState' objects}
6 0.000 0.000 0.000 0.000 {hasattr}
4 0.000 0.000 0.000 0.000 {method 'reshape' of 'numpy.ndarray' objects}
4 0.000 0.000 0.000 0.000 {method 'transpose' of 'numpy.ndarray' objects}
4 0.000 0.000 0.000 0.000 {method 'remove' of 'list' objects}
6 0.000 0.000 0.000 0.000 {max}
4 0.000 0.000 0.000 0.000 {method 'insert' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'squeeze' of 'numpy.ndarray' objects}
3 0.000 0.000 0.000 0.000 {abs}
1 0.000 0.000 0.000 0.000 {method 'conj' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/mixture/gmm.py
Function: predict at line 353
Total time: 0 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
353 def predict(self, X):
354 """Predict label for data.
355
356 Parameters
357 ----------
358 X : array-like, shape = [n_samples, n_features]
359
360 Returns
361 -------
362 C : array, shape = (n_samples,)
363 """
364 logprob, responsibilities = self.eval(X)
365 return responsibilities.argmax(axis=1)
File: /tmp/vb_sklearn/sklearn/mixture/gmm.py
Function: fit at line 434
Total time: 0.299136 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
434 def fit(self, X, **kwargs):
435 """Estimate model parameters with the expectation-maximization
436 algorithm.
437
438 A initialization step is performed before entering the em
439 algorithm. If you want to avoid this step, set the keyword
440 argument init_params to the empty string '' when creating the
441 GMM object. Likewise, if you would like just to do an
442 initialization, set n_iter=0.
443
444 Parameters
445 ----------
446 X : array_like, shape (n, n_features)
447 List of n_features-dimensional data points. Each row
448 corresponds to a single data point.
449 """
450 ## initialization step
451 1 15 15.0 0.0 X = np.asarray(X)
452 1 5 5.0 0.0 if X.ndim == 1:
453 X = X[:, np.newaxis]
454 1 5 5.0 0.0 if X.shape[0] < self.n_components:
455 raise ValueError(
456 'GMM estimation with %s components, but got only %s samples' %
457 (self.n_components, X.shape[0]))
458 1 4 4.0 0.0 if kwargs:
459 warnings.warn("Setting parameters in the 'fit' method is"
460 "deprecated. Set it on initialization instead.",
461 DeprecationWarning)
462 # initialisations for in case the user still adds parameters to fit
463 # so things don't break
464 if 'n_iter' in kwargs:
465 self.n_iter = kwargs['n_iter']
466 if 'n_init' in kwargs:
467 if kwargs['n_init'] < 1:
468 raise ValueError('GMM estimation requires n_init > 0.')
469 else:
470 self.n_init = kwargs['n_init']
471 if 'params' in kwargs:
472 self.params = kwargs['params']
473 if 'init_params' in kwargs:
474 self.init_params = kwargs['init_params']
475
476 1 5 5.0 0.0 max_log_prob = - np.infty
477
478 2 13 6.5 0.0 for _ in range(self.n_init):
479 1 5 5.0 0.0 if 'm' in self.init_params or not hasattr(self, 'means_'):
480 1 5 5.0 0.0 self.means_ = cluster.KMeans(
481 1 173771 173771.0 58.1 n_clusters=self.n_components).fit(X).cluster_centers_
482
483 1 6 6.0 0.0 if 'w' in self.init_params or not hasattr(self, 'weights_'):
484 1 6 6.0 0.0 self.weights_ = np.tile(1.0 / self.n_components,
485 1 80 80.0 0.0 self.n_components)
486
487 1 4 4.0 0.0 if 'c' in self.init_params or not hasattr(self, 'covars_'):
488 1 1107 1107.0 0.4 cv = np.cov(X.T) + self.min_covar * np.eye(X.shape[1])
489 1 5 5.0 0.0 if not cv.shape:
490 cv.shape = (1, 1)
491 self.covars_ = \
492 1 3 3.0 0.0 distribute_covar_matrix_to_match_covariance_type(
493 1 107 107.0 0.0 cv, self.covariance_type, self.n_components)
494
495 # EM algorithms
496 1 4 4.0 0.0 log_likelihood = []
497 # reset self.converged_ to False
498 1 4 4.0 0.0 self.converged_ = False
499 4 20 5.0 0.0 for i in xrange(self.n_iter):
500 # Expectation step
501 4 87302 21825.5 29.2 curr_log_likelihood, responsibilities = self.eval(X)
502 4 66 16.5 0.0 log_likelihood.append(curr_log_likelihood.sum())
503
504 # Check for convergence.
505 4 30 7.5 0.0 if i > 0 and abs(log_likelihood[-1] - log_likelihood[-2]) < \
506 3 27 9.0 0.0 self.thresh:
507 1 4 4.0 0.0 self.converged_ = True
508 1 3 3.0 0.0 break
509
510 # Maximization step
511 3 16 5.3 0.0 self._do_mstep(X, responsibilities, self.params,
512 3 36427 12142.3 12.2 self.min_covar)
513
514 # if the results are better, keep it
515 1 4 4.0 0.0 if self.n_iter:
516 1 6 6.0 0.0 if log_likelihood[-1] > max_log_prob:
517 1 4 4.0 0.0 max_log_prob = log_likelihood[-1]
518 1 4 4.0 0.0 best_params = {'weights': self.weights_,
519 1 4 4.0 0.0 'means': self.means_,
520 1 4 4.0 0.0 'covars': self.covars_}
521 1 45 45.0 0.0 if self.n_iter:
522 1 5 5.0 0.0 self.covars_ = best_params['covars']
523 1 4 4.0 0.0 self.means_ = best_params['means']
524 1 4 4.0 0.0 self.weights_ = best_params['weights']
525 1 3 3.0 0.0 return self
Benchmark statement
obj.predict(X_t)
Execution time
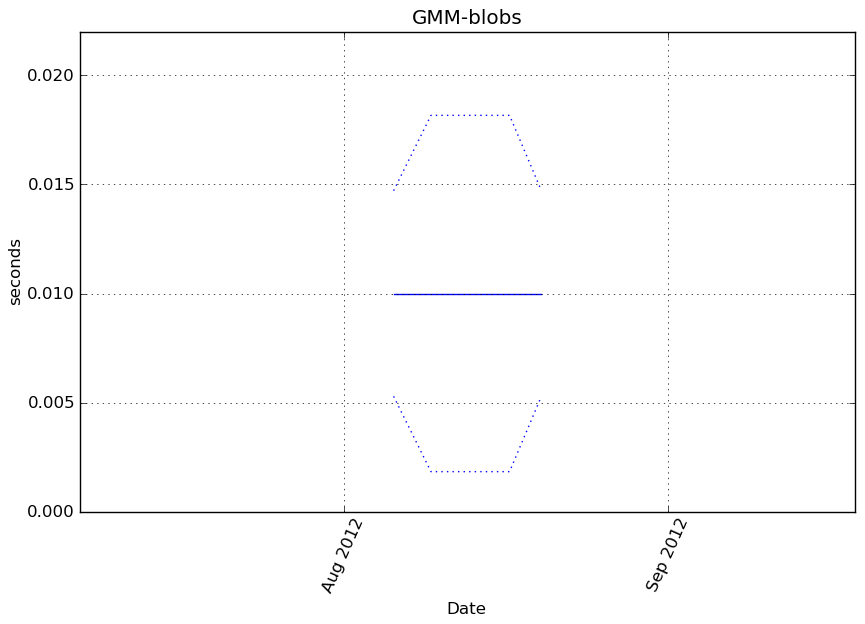
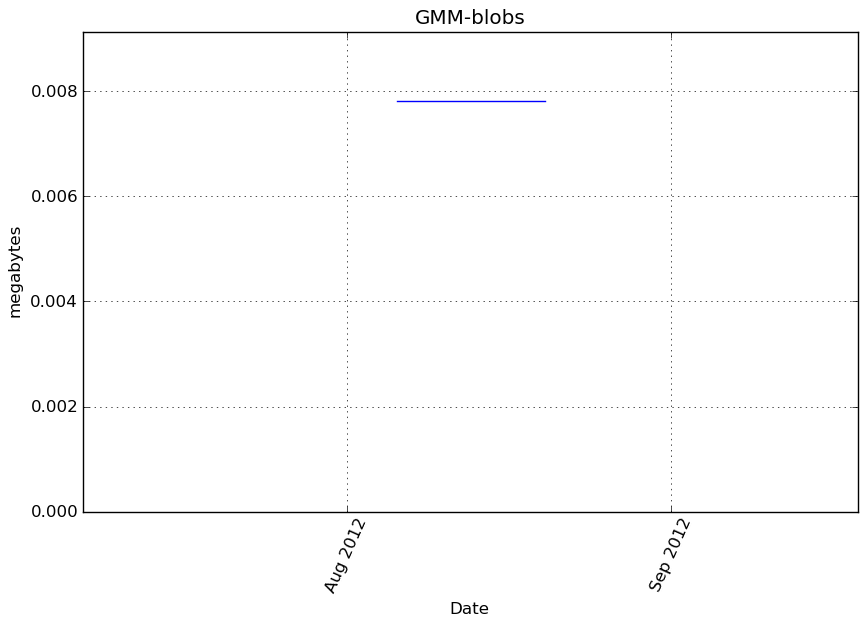
Memory usage
Additional output
cProfile
693 function calls in 0.018 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.018 0.018 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 0.018 0.018 <f>:1(<module>)
1 0.000 0.000 0.018 0.018 /tmp/vb_sklearn/sklearn/mixture/gmm.py:353(predict)
1 0.000 0.000 0.018 0.018 /tmp/vb_sklearn/sklearn/mixture/gmm.py:275(eval)
1 0.000 0.000 0.018 0.018 /tmp/vb_sklearn/sklearn/mixture/gmm.py:23(log_multivariate_normal_density)
1 0.002 0.002 0.018 0.018 /tmp/vb_sklearn/sklearn/mixture/gmm.py:626(_log_multivariate_normal_density_full)
10 0.005 0.001 0.011 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/basic.py:72(solve_triangular)
30 0.005 0.000 0.006 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:526(asarray_chkfinite)
10 0.000 0.000 0.005 0.001 {map}
10 0.000 0.000 0.003 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/decomp_cholesky.py:30(cholesky)
10 0.002 0.000 0.003 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/decomp_cholesky.py:13(_cholesky)
60 0.002 0.000 0.002 0.000 {method 'any' of 'numpy.ndarray' objects}
20 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/lapack.py:60(get_lapack_funcs)
21 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
21 0.001 0.000 0.001 0.000 {method 'sum' of 'numpy.ndarray' objects}
20 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/lapack.py:45(find_best_lapack_type)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/extmath.py:210(logsumexp)
41 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
10 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:902(diagonal)
41 0.000 0.000 0.000 0.000 {numpy.core.multiarray.array}
30 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/lapack.py:23(cast_to_lapack_prefix)
10 0.000 0.000 0.000 0.000 {method 'diagonal' of 'numpy.ndarray' objects}
21 0.000 0.000 0.000 0.000 {isinstance}
60 0.000 0.000 0.000 0.000 {issubclass}
40 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
30 0.000 0.000 0.000 0.000 {getattr}
1 0.000 0.000 0.000 0.000 {method 'max' of 'numpy.ndarray' objects}
20 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:449(isfortran)
20 0.000 0.000 0.000 0.000 {method 'sort' of 'list' objects}
21 0.000 0.000 0.000 0.000 {range}
50 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1069(rollaxis)
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
41 0.000 0.000 0.000 0.000 {len}
20 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/misc.py:22(_datacopied)
10 0.000 0.000 0.000 0.000 {method 'get' of 'dict' objects}
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
1 0.000 0.000 0.000 0.000 {method 'transpose' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'remove' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'insert' of 'list' objects}
1 0.000 0.000 0.000 0.000 {hasattr}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/mixture/gmm.py
Function: predict at line 353
Total time: 0.017772 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
353 def predict(self, X):
354 """Predict label for data.
355
356 Parameters
357 ----------
358 X : array-like, shape = [n_samples, n_features]
359
360 Returns
361 -------
362 C : array, shape = (n_samples,)
363 """
364 1 17746 17746.0 99.9 logprob, responsibilities = self.eval(X)
365 1 26 26.0 0.1 return responsibilities.argmax(axis=1)
File: /tmp/vb_sklearn/sklearn/mixture/gmm.py
Function: fit at line 434
Total time: 0.299136 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
434 def fit(self, X, **kwargs):
435 """Estimate model parameters with the expectation-maximization
436 algorithm.
437
438 A initialization step is performed before entering the em
439 algorithm. If you want to avoid this step, set the keyword
440 argument init_params to the empty string '' when creating the
441 GMM object. Likewise, if you would like just to do an
442 initialization, set n_iter=0.
443
444 Parameters
445 ----------
446 X : array_like, shape (n, n_features)
447 List of n_features-dimensional data points. Each row
448 corresponds to a single data point.
449 """
450 ## initialization step
451 1 15 15.0 0.0 X = np.asarray(X)
452 1 5 5.0 0.0 if X.ndim == 1:
453 X = X[:, np.newaxis]
454 1 5 5.0 0.0 if X.shape[0] < self.n_components:
455 raise ValueError(
456 'GMM estimation with %s components, but got only %s samples' %
457 (self.n_components, X.shape[0]))
458 1 4 4.0 0.0 if kwargs:
459 warnings.warn("Setting parameters in the 'fit' method is"
460 "deprecated. Set it on initialization instead.",
461 DeprecationWarning)
462 # initialisations for in case the user still adds parameters to fit
463 # so things don't break
464 if 'n_iter' in kwargs:
465 self.n_iter = kwargs['n_iter']
466 if 'n_init' in kwargs:
467 if kwargs['n_init'] < 1:
468 raise ValueError('GMM estimation requires n_init > 0.')
469 else:
470 self.n_init = kwargs['n_init']
471 if 'params' in kwargs:
472 self.params = kwargs['params']
473 if 'init_params' in kwargs:
474 self.init_params = kwargs['init_params']
475
476 1 5 5.0 0.0 max_log_prob = - np.infty
477
478 2 13 6.5 0.0 for _ in range(self.n_init):
479 1 5 5.0 0.0 if 'm' in self.init_params or not hasattr(self, 'means_'):
480 1 5 5.0 0.0 self.means_ = cluster.KMeans(
481 1 173771 173771.0 58.1 n_clusters=self.n_components).fit(X).cluster_centers_
482
483 1 6 6.0 0.0 if 'w' in self.init_params or not hasattr(self, 'weights_'):
484 1 6 6.0 0.0 self.weights_ = np.tile(1.0 / self.n_components,
485 1 80 80.0 0.0 self.n_components)
486
487 1 4 4.0 0.0 if 'c' in self.init_params or not hasattr(self, 'covars_'):
488 1 1107 1107.0 0.4 cv = np.cov(X.T) + self.min_covar * np.eye(X.shape[1])
489 1 5 5.0 0.0 if not cv.shape:
490 cv.shape = (1, 1)
491 self.covars_ = \
492 1 3 3.0 0.0 distribute_covar_matrix_to_match_covariance_type(
493 1 107 107.0 0.0 cv, self.covariance_type, self.n_components)
494
495 # EM algorithms
496 1 4 4.0 0.0 log_likelihood = []
497 # reset self.converged_ to False
498 1 4 4.0 0.0 self.converged_ = False
499 4 20 5.0 0.0 for i in xrange(self.n_iter):
500 # Expectation step
501 4 87302 21825.5 29.2 curr_log_likelihood, responsibilities = self.eval(X)
502 4 66 16.5 0.0 log_likelihood.append(curr_log_likelihood.sum())
503
504 # Check for convergence.
505 4 30 7.5 0.0 if i > 0 and abs(log_likelihood[-1] - log_likelihood[-2]) < \
506 3 27 9.0 0.0 self.thresh:
507 1 4 4.0 0.0 self.converged_ = True
508 1 3 3.0 0.0 break
509
510 # Maximization step
511 3 16 5.3 0.0 self._do_mstep(X, responsibilities, self.params,
512 3 36427 12142.3 12.2 self.min_covar)
513
514 # if the results are better, keep it
515 1 4 4.0 0.0 if self.n_iter:
516 1 6 6.0 0.0 if log_likelihood[-1] > max_log_prob:
517 1 4 4.0 0.0 max_log_prob = log_likelihood[-1]
518 1 4 4.0 0.0 best_params = {'weights': self.weights_,
519 1 4 4.0 0.0 'means': self.means_,
520 1 4 4.0 0.0 'covars': self.covars_}
521 1 45 45.0 0.0 if self.n_iter:
522 1 5 5.0 0.0 self.covars_ = best_params['covars']
523 1 4 4.0 0.0 self.means_ = best_params['means']
524 1 4 4.0 0.0 self.weights_ = best_params['weights']
525 1 3 3.0 0.0 return self
VBGMM-blobs¶
Benchmark setup
from sklearn.mixture import VBGMM from deps import load_data kwargs = {'n_components': 10, 'covariance_type': 'full'} X, y, X_t, y_t = load_data('blobs') obj = VBGMM(**kwargs)
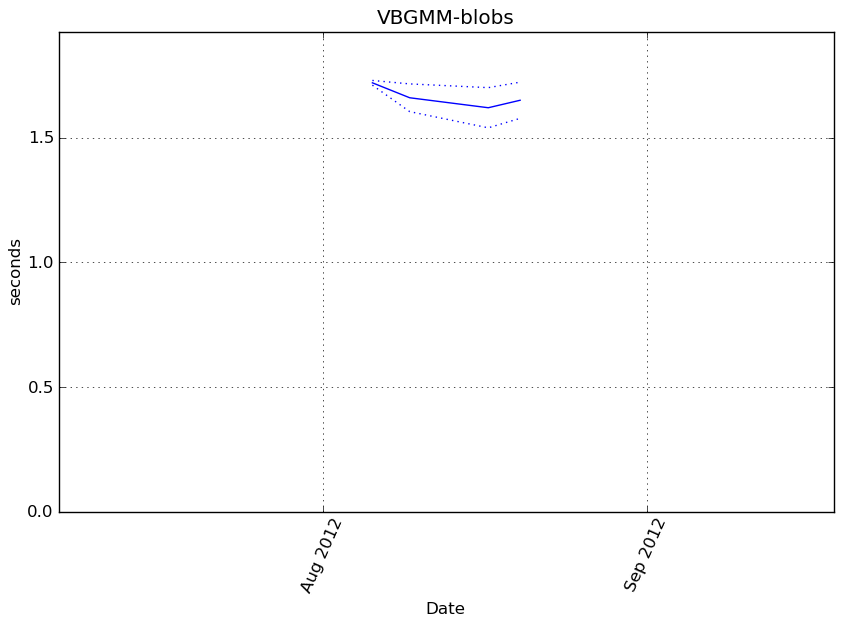
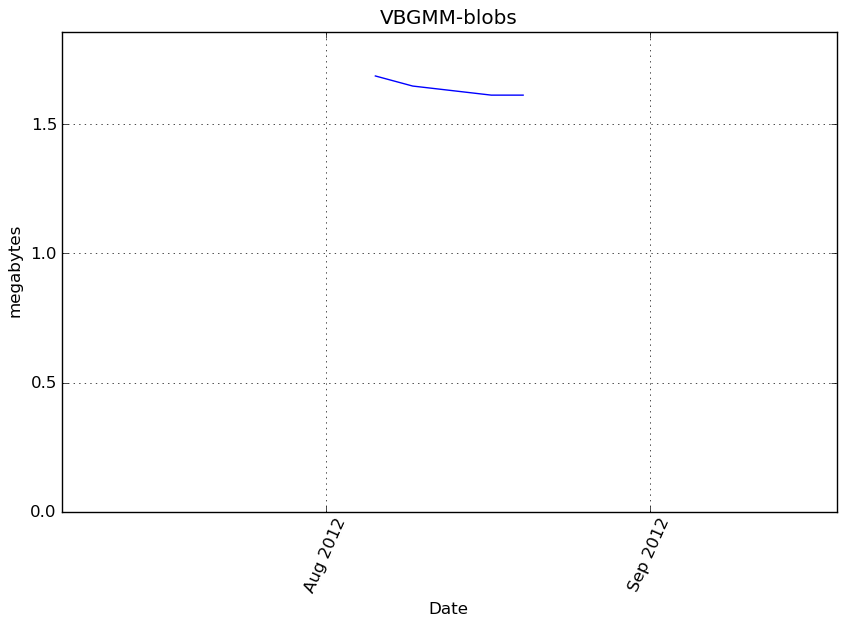
Benchmark statement
obj.fit(X)
Execution time
Memory usage
Additional output
cProfile
39334 function calls in 1.743 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 1.743 1.743 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 1.743 1.743 <f>:1(<module>)
1 0.001 0.001 1.743 1.743 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:472(fit)
10 0.000 0.000 1.255 0.126 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:372(_do_mstep)
200 0.950 0.005 1.011 0.005 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/basic.py:365(lstsq)
10 0.032 0.003 0.687 0.069 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:303(_update_precisions)
10 0.017 0.002 0.566 0.057 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:284(_update_means)
100 0.001 0.000 0.490 0.005 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/basic.py:457(pinv)
10 0.001 0.000 0.269 0.027 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:663(eval)
10 0.005 0.000 0.258 0.026 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:92(_bound_state_log_lik)
100 0.003 0.000 0.254 0.003 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:86(_sym_quad_form)
100 0.005 0.000 0.250 0.002 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/spatial/distance.py:1693(cdist)
100 0.231 0.002 0.231 0.002 {scipy.spatial._distance_wrap.cdist_mahalanobis_wrap}
1 0.000 0.000 0.166 0.166 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:738(fit)
1 0.000 0.000 0.166 0.166 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:151(k_means)
10 0.001 0.000 0.164 0.016 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:303(_kmeans_single)
320 0.129 0.000 0.129 0.000 {numpy.core._dotblas.dot}
10 0.000 0.000 0.103 0.010 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:525(_init_centroids)
10 0.014 0.001 0.103 0.010 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:36(_k_init)
120 0.014 0.000 0.100 0.001 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:101(euclidean_distances)
600 0.047 0.000 0.080 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:526(asarray_chkfinite)
10 0.000 0.000 0.050 0.005 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:450(_logprior)
100 0.017 0.000 0.047 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/basic.py:336(det)
10 0.001 0.000 0.043 0.004 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:414(_bound_precisions)
100 0.002 0.000 0.042 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:68(_bound_wishart)
200 0.001 0.000 0.040 0.000 {map}
120 0.001 0.000 0.039 0.000 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:52(check_pairwise_arrays)
2062 0.035 0.000 0.035 0.000 {method 'sum' of 'numpy.ndarray' objects}
120 0.002 0.000 0.033 0.000 /tmp/vb_sklearn/sklearn/utils/extmath.py:70(safe_sparse_dot)
20 0.025 0.001 0.033 0.002 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:478(_centers)
361 0.002 0.000 0.032 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
1400 0.030 0.000 0.030 0.000 {method 'any' of 'numpy.ndarray' objects}
20 0.000 0.000 0.027 0.001 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:431(_labels_inertia)
200 0.015 0.000 0.026 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:58(wishart_logz)
20 0.006 0.000 0.026 0.001 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:414(_labels_inertia_precompute_dense)
601 0.007 0.000 0.024 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
210 0.010 0.000 0.023 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:48(wishart_log_det)
1060 0.003 0.000 0.021 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
1477 0.003 0.000 0.020 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
1932 0.005 0.000 0.017 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
1477 0.011 0.000 0.017 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
240 0.001 0.000 0.016 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:23(safe_asarray)
2294 0.014 0.000 0.014 0.000 {numpy.core.multiarray.array}
361 0.002 0.000 0.012 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
200 0.003 0.000 0.011 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/lapack.py:60(get_lapack_funcs)
270 0.007 0.000 0.010 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:28(digamma)
240 0.007 0.000 0.009 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:32(gammaln)
300 0.001 0.000 0.008 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/spatial/distance.py:132(_copy_arrays_if_base_present)
10 0.003 0.000 0.008 0.001 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:36(log_normalize)
420 0.005 0.000 0.007 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1830(identity)
300 0.001 0.000 0.007 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/spatial/distance.py:120(_copy_array_if_base_present)
300 0.001 0.000 0.007 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numerictypes.py:703(issubsctype)
200 0.003 0.000 0.006 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/lapack.py:45(find_best_lapack_type)
210 0.001 0.000 0.006 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:986(trace)
202 0.006 0.000 0.006 0.000 {method 'mean' of 'numpy.ndarray' objects}
361 0.003 0.000 0.006 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
3613 0.005 0.000 0.005 0.000 {isinstance}
600 0.003 0.000 0.005 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numerictypes.py:608(obj2sctype)
530 0.002 0.000 0.005 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/getlimits.py:91(__new__)
3354 0.004 0.000 0.004 0.000 {method 'split' of 'str' objects}
210 0.004 0.000 0.004 0.000 {method 'trace' of 'numpy.ndarray' objects}
10 0.002 0.000 0.003 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:714(_bound_proportions)
561 0.003 0.000 0.003 0.000 {numpy.core.multiarray.zeros}
10 0.002 0.000 0.003 0.000 /tmp/vb_sklearn/sklearn/utils/extmath.py:210(logsumexp)
100 0.002 0.000 0.003 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/flinalg.py:24(get_flinalg_funcs)
10 0.001 0.000 0.003 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:723(_bound_concentration)
550 0.002 0.000 0.002 0.000 {method 'get' of 'dict' objects}
410 0.002 0.000 0.002 0.000 {numpy.core.multiarray.arange}
1700 0.002 0.000 0.002 0.000 {issubclass}
361 0.001 0.000 0.002 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
200 0.000 0.000 0.002 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1508(any)
10 0.001 0.000 0.002 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:707(_update_concentration)
400 0.001 0.000 0.002 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/lapack.py:23(cast_to_lapack_prefix)
200 0.002 0.000 0.002 0.000 {method 'astype' of 'numpy.generic' objects}
500 0.001 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/spatial/distance.py:151(_convert_to_double)
620 0.001 0.000 0.001 0.000 {getattr}
212 0.001 0.000 0.001 0.000 {method 'reshape' of 'numpy.ndarray' objects}
20 0.001 0.000 0.001 0.000 {method 'max' of 'numpy.ndarray' objects}
90 0.001 0.000 0.001 0.000 {method 'cumsum' of 'numpy.ndarray' objects}
10 0.000 0.000 0.001 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:407(_bound_means)
1181 0.001 0.000 0.001 0.000 {method 'append' of 'list' objects}
10 0.000 0.000 0.001 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:24(sqnorm)
2324 0.001 0.000 0.001 0.000 {len}
90 0.001 0.000 0.001 0.000 {method 'random_sample' of 'mtrand.RandomState' objects}
10 0.000 0.000 0.001 0.000 /tmp/vb_sklearn/sklearn/utils/extmath.py:15(norm)
361 0.001 0.000 0.001 0.000 {range}
90 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:757(searchsorted)
300 0.001 0.000 0.001 0.000 {method 'sort' of 'list' objects}
104 0.001 0.000 0.001 0.000 {numpy.core.multiarray.empty}
1 0.000 0.000 0.001 0.001 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:142(_tolerance)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:2470(var)
1 0.000 0.000 0.000 0.000 {method 'var' of 'numpy.ndarray' objects}
74 0.000 0.000 0.000 0.000 {method 'copy' of 'numpy.ndarray' objects}
90 0.000 0.000 0.000 0.000 {method 'searchsorted' of 'numpy.ndarray' objects}
10 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/blas.py:30(get_blas_funcs)
200 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:449(isfortran)
24 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
500 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/misc.py:22(_datacopied)
64 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:710(_check_fit_data)
20 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1069(rollaxis)
100 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/linalg/flinalg.py:19(has_column_major_storage)
33 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:181(check_random_state)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:404(_squared_norms)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:33(as_float_array)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/shape_base.py:766(tile)
100 0.000 0.000 0.000 0.000 {method 'lower' of 'str' objects}
10 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:397(swapaxes)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:711(_initialize_gamma)
40 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:733(_monitor)
100 0.000 0.000 0.000 0.000 {callable}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/cluster/k_means_.py:690(__init__)
10 0.000 0.000 0.000 0.000 {method 'transpose' of 'numpy.ndarray' objects}
10 0.000 0.000 0.000 0.000 {method 'swapaxes' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:2299(mean)
10 0.000 0.000 0.000 0.000 {method 'remove' of 'list' objects}
10 0.000 0.000 0.000 0.000 {method 'randint' of 'mtrand.RandomState' objects}
12 0.000 0.000 0.000 0.000 {max}
10 0.000 0.000 0.000 0.000 {method 'insert' of 'list' objects}
2 0.000 0.000 0.000 0.000 {hasattr}
1 0.000 0.000 0.000 0.000 {method 'repeat' of 'numpy.ndarray' objects}
9 0.000 0.000 0.000 0.000 {abs}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/mixture/dpgmm.py
Function: fit at line 472
Total time: 2.00456 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
472 def fit(self, X, **kwargs):
473 """Estimate model parameters with the variational
474 algorithm.
475
476 For a full derivation and description of the algorithm see
477 doc/dp-derivation/dp-derivation.tex
478
479 A initialization step is performed before entering the em
480 algorithm. If you want to avoid this step, set the keyword
481 argument init_params to the empty string '' when when creating
482 the object. Likewise, if you would like just to do an
483 initialization, set n_iter=0.
484
485 Parameters
486 ----------
487 X : array_like, shape (n, n_features)
488 List of n_features-dimensional data points. Each row
489 corresponds to a single data point.
490 """
491 1 14 14.0 0.0 self.random_state = check_random_state(self.random_state)
492 1 5 5.0 0.0 if kwargs:
493 warnings.warn("Setting parameters in the 'fit' method is"
494 "deprecated. Set it on initialization instead.",
495 DeprecationWarning)
496 # initialisations for in case the user still adds parameters to fit
497 # so things don't break
498 if 'n_iter' in kwargs:
499 self.n_iter = kwargs['n_iter']
500 if 'params' in kwargs:
501 self.params = kwargs['params']
502 if 'init_params' in kwargs:
503 self.init_params = kwargs['init_params']
504
505 ## initialization step
506 1 14 14.0 0.0 X = np.asarray(X)
507 1 5 5.0 0.0 if X.ndim == 1:
508 X = X[:, np.newaxis]
509
510 1 6 6.0 0.0 n_features = X.shape[1]
511 1 26 26.0 0.0 z = np.ones((X.shape[0], self.n_components))
512 1 79 79.0 0.0 z /= self.n_components
513
514 1 26 26.0 0.0 self._initial_bound = - 0.5 * n_features * np.log(2 * np.pi)
515 1 16 16.0 0.0 self._initial_bound -= np.log(2 * np.pi * np.e)
516
517 1 5 5.0 0.0 if (self.init_params != '') or not hasattr(self, 'gamma_'):
518 1 38 38.0 0.0 self._initialize_gamma()
519
520 1 5 5.0 0.0 if 'm' in self.init_params or not hasattr(self, 'means_'):
521 1 5 5.0 0.0 self.means_ = cluster.KMeans(
522 1 4 4.0 0.0 n_clusters=self.n_components,
523 1 209252 209252.0 10.4 random_state=self.random_state).fit(X).cluster_centers_[::-1]
524
525 1 7 7.0 0.0 if 'w' in self.init_params or not hasattr(self, 'weights_'):
526 1 91 91.0 0.0 self.weights_ = np.tile(1.0 / self.n_components, self.n_components)
527
528 1 5 5.0 0.0 if 'c' in self.init_params or not hasattr(self, 'precs_'):
529 1 5 5.0 0.0 if self.covariance_type == 'spherical':
530 self.dof_ = np.ones(self.n_components)
531 self.scale_ = np.ones(self.n_components)
532 self.precs_ = np.ones((self.n_components, n_features))
533 self.bound_prec_ = 0.5 * n_features * (
534 digamma(self.dof_) - np.log(self.scale_))
535 1 4 4.0 0.0 elif self.covariance_type == 'diag':
536 self.dof_ = 1 + 0.5 * n_features
537 self.dof_ *= np.ones((self.n_components, n_features))
538 self.scale_ = np.ones((self.n_components, n_features))
539 self.precs_ = np.ones((self.n_components, n_features))
540 self.bound_prec_ = 0.5 * (np.sum(digamma(self.dof_) -
541 np.log(self.scale_), 1))
542 self.bound_prec_ -= 0.5 * np.sum(self.precs_, 1)
543 1 5 5.0 0.0 elif self.covariance_type == 'tied':
544 self.dof_ = 1.
545 self.scale_ = np.identity(n_features)
546 self.precs_ = np.identity(n_features)
547 self.det_scale_ = 1.
548 self.bound_prec_ = 0.5 * wishart_log_det(
549 self.dof_, self.scale_, self.det_scale_, n_features)
550 self.bound_prec_ -= 0.5 * self.dof_ * np.trace(self.scale_)
551 1 4 4.0 0.0 elif self.covariance_type == 'full':
552 1 8 8.0 0.0 self.dof_ = (1 + self.n_components + X.shape[0])
553 1 41 41.0 0.0 self.dof_ *= np.ones(self.n_components)
554 1 5 5.0 0.0 self.scale_ = [2 * np.identity(n_features)
555 11 440 40.0 0.0 for i in xrange(self.n_components)]
556 1 4 4.0 0.0 self.precs_ = [np.identity(n_features)
557 11 212 19.3 0.0 for i in xrange(self.n_components)]
558 1 19 19.0 0.0 self.det_scale_ = np.ones(self.n_components)
559 1 8 8.0 0.0 self.bound_prec_ = np.zeros(self.n_components)
560 11 57 5.2 0.0 for k in xrange(self.n_components):
561 10 45 4.5 0.0 self.bound_prec_[k] = wishart_log_det(
562 10 62 6.2 0.0 self.dof_[k], self.scale_[k], self.det_scale_[k],
563 10 1193 119.3 0.1 n_features)
564 10 66 6.6 0.0 self.bound_prec_[k] -= (self.dof_[k] *
565 10 427 42.7 0.0 np.trace(self.scale_[k]))
566 1 16 16.0 0.0 self.bound_prec_ *= 0.5
567
568 1 5 5.0 0.0 logprob = []
569 # reset self.converged_ to False
570 1 6 6.0 0.0 self.converged_ = False
571 11 78 7.1 0.0 for i in xrange(self.n_iter):
572 # Expectation step
573 10 283661 28366.1 14.2 curr_logprob, z = self.eval(X)
574 10 57193 5719.3 2.9 logprob.append(curr_logprob.sum() + self._logprior(z))
575
576 # Check for convergence.
577 10 143 14.3 0.0 if i > 0 and abs(logprob[-1] - logprob[-2]) < self.thresh:
578 self.converged_ = True
579 break
580
581 # Maximization step
582 10 1451244 145124.4 72.4 self._do_mstep(X, z, self.params)
583
584 1 4 4.0 0.0 return self
File: /tmp/vb_sklearn/sklearn/mixture/gmm.py
Function: predict at line 353
Total time: 0 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
353 def predict(self, X):
354 """Predict label for data.
355
356 Parameters
357 ----------
358 X : array-like, shape = [n_samples, n_features]
359
360 Returns
361 -------
362 C : array, shape = (n_samples,)
363 """
364 logprob, responsibilities = self.eval(X)
365 return responsibilities.argmax(axis=1)
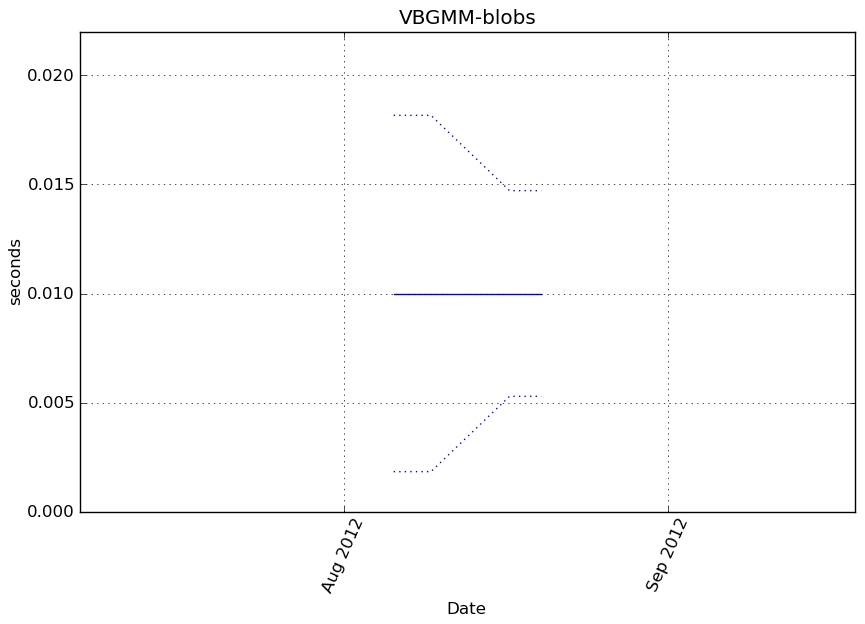
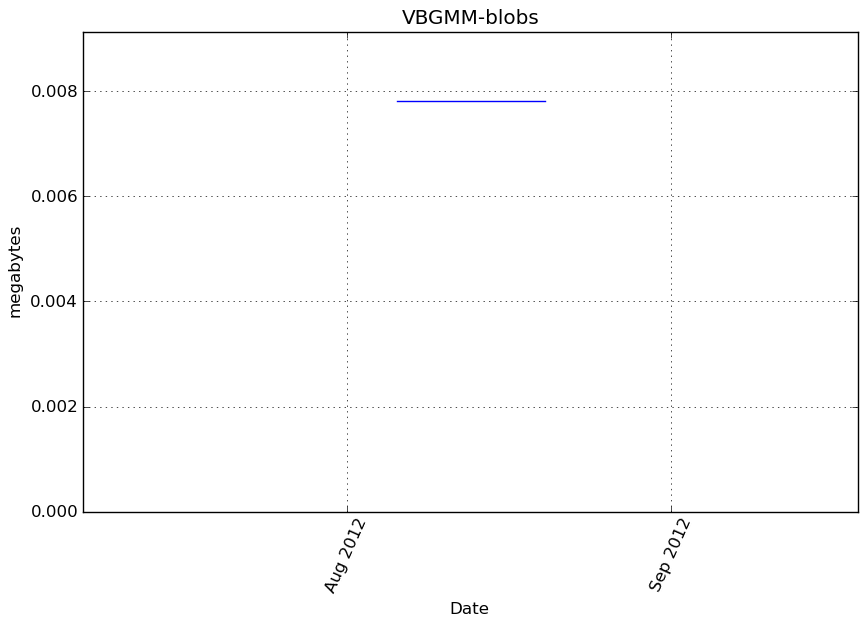
Benchmark statement
obj.predict(X_t)
Execution time
Memory usage
Additional output
cProfile
586 function calls in 0.030 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.030 0.030 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 0.030 0.030 <f>:1(<module>)
1 0.000 0.000 0.030 0.030 /tmp/vb_sklearn/sklearn/mixture/gmm.py:353(predict)
1 0.000 0.000 0.030 0.030 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:663(eval)
1 0.000 0.000 0.029 0.029 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:92(_bound_state_log_lik)
10 0.000 0.000 0.028 0.003 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:86(_sym_quad_form)
10 0.000 0.000 0.028 0.003 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/spatial/distance.py:1693(cdist)
10 0.026 0.003 0.026 0.003 {scipy.spatial._distance_wrap.cdist_mahalanobis_wrap}
30 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/spatial/distance.py:132(_copy_arrays_if_base_present)
30 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/spatial/distance.py:120(_copy_array_if_base_present)
30 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numerictypes.py:703(issubsctype)
1 0.000 0.000 0.001 0.001 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:36(log_normalize)
60 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numerictypes.py:608(obj2sctype)
31 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
31 0.000 0.000 0.000 0.000 {numpy.core.multiarray.array}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/extmath.py:210(logsumexp)
90 0.000 0.000 0.000 0.000 {issubclass}
50 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/spatial/distance.py:151(_convert_to_double)
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
10 0.000 0.000 0.000 0.000 {method 'reshape' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 {method 'max' of 'numpy.ndarray' objects}
4 0.000 0.000 0.000 0.000 {method 'sum' of 'numpy.ndarray' objects}
104 0.000 0.000 0.000 0.000 {isinstance}
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/mixture/dpgmm.py:28(digamma)
13 0.000 0.000 0.000 0.000 {numpy.core.multiarray.zeros}
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
3 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/getlimits.py:91(__new__)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1069(rollaxis)
3 0.000 0.000 0.000 0.000 {method 'get' of 'dict' objects}
1 0.000 0.000 0.000 0.000 {method 'copy' of 'numpy.ndarray' objects}
20 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:397(swapaxes)
10 0.000 0.000 0.000 0.000 {callable}
10 0.000 0.000 0.000 0.000 {method 'lower' of 'str' objects}
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
1 0.000 0.000 0.000 0.000 {range}
1 0.000 0.000 0.000 0.000 {method 'swapaxes' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'remove' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'transpose' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'insert' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/mixture/dpgmm.py
Function: fit at line 472
Total time: 2.00456 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
472 def fit(self, X, **kwargs):
473 """Estimate model parameters with the variational
474 algorithm.
475
476 For a full derivation and description of the algorithm see
477 doc/dp-derivation/dp-derivation.tex
478
479 A initialization step is performed before entering the em
480 algorithm. If you want to avoid this step, set the keyword
481 argument init_params to the empty string '' when when creating
482 the object. Likewise, if you would like just to do an
483 initialization, set n_iter=0.
484
485 Parameters
486 ----------
487 X : array_like, shape (n, n_features)
488 List of n_features-dimensional data points. Each row
489 corresponds to a single data point.
490 """
491 1 14 14.0 0.0 self.random_state = check_random_state(self.random_state)
492 1 5 5.0 0.0 if kwargs:
493 warnings.warn("Setting parameters in the 'fit' method is"
494 "deprecated. Set it on initialization instead.",
495 DeprecationWarning)
496 # initialisations for in case the user still adds parameters to fit
497 # so things don't break
498 if 'n_iter' in kwargs:
499 self.n_iter = kwargs['n_iter']
500 if 'params' in kwargs:
501 self.params = kwargs['params']
502 if 'init_params' in kwargs:
503 self.init_params = kwargs['init_params']
504
505 ## initialization step
506 1 14 14.0 0.0 X = np.asarray(X)
507 1 5 5.0 0.0 if X.ndim == 1:
508 X = X[:, np.newaxis]
509
510 1 6 6.0 0.0 n_features = X.shape[1]
511 1 26 26.0 0.0 z = np.ones((X.shape[0], self.n_components))
512 1 79 79.0 0.0 z /= self.n_components
513
514 1 26 26.0 0.0 self._initial_bound = - 0.5 * n_features * np.log(2 * np.pi)
515 1 16 16.0 0.0 self._initial_bound -= np.log(2 * np.pi * np.e)
516
517 1 5 5.0 0.0 if (self.init_params != '') or not hasattr(self, 'gamma_'):
518 1 38 38.0 0.0 self._initialize_gamma()
519
520 1 5 5.0 0.0 if 'm' in self.init_params or not hasattr(self, 'means_'):
521 1 5 5.0 0.0 self.means_ = cluster.KMeans(
522 1 4 4.0 0.0 n_clusters=self.n_components,
523 1 209252 209252.0 10.4 random_state=self.random_state).fit(X).cluster_centers_[::-1]
524
525 1 7 7.0 0.0 if 'w' in self.init_params or not hasattr(self, 'weights_'):
526 1 91 91.0 0.0 self.weights_ = np.tile(1.0 / self.n_components, self.n_components)
527
528 1 5 5.0 0.0 if 'c' in self.init_params or not hasattr(self, 'precs_'):
529 1 5 5.0 0.0 if self.covariance_type == 'spherical':
530 self.dof_ = np.ones(self.n_components)
531 self.scale_ = np.ones(self.n_components)
532 self.precs_ = np.ones((self.n_components, n_features))
533 self.bound_prec_ = 0.5 * n_features * (
534 digamma(self.dof_) - np.log(self.scale_))
535 1 4 4.0 0.0 elif self.covariance_type == 'diag':
536 self.dof_ = 1 + 0.5 * n_features
537 self.dof_ *= np.ones((self.n_components, n_features))
538 self.scale_ = np.ones((self.n_components, n_features))
539 self.precs_ = np.ones((self.n_components, n_features))
540 self.bound_prec_ = 0.5 * (np.sum(digamma(self.dof_) -
541 np.log(self.scale_), 1))
542 self.bound_prec_ -= 0.5 * np.sum(self.precs_, 1)
543 1 5 5.0 0.0 elif self.covariance_type == 'tied':
544 self.dof_ = 1.
545 self.scale_ = np.identity(n_features)
546 self.precs_ = np.identity(n_features)
547 self.det_scale_ = 1.
548 self.bound_prec_ = 0.5 * wishart_log_det(
549 self.dof_, self.scale_, self.det_scale_, n_features)
550 self.bound_prec_ -= 0.5 * self.dof_ * np.trace(self.scale_)
551 1 4 4.0 0.0 elif self.covariance_type == 'full':
552 1 8 8.0 0.0 self.dof_ = (1 + self.n_components + X.shape[0])
553 1 41 41.0 0.0 self.dof_ *= np.ones(self.n_components)
554 1 5 5.0 0.0 self.scale_ = [2 * np.identity(n_features)
555 11 440 40.0 0.0 for i in xrange(self.n_components)]
556 1 4 4.0 0.0 self.precs_ = [np.identity(n_features)
557 11 212 19.3 0.0 for i in xrange(self.n_components)]
558 1 19 19.0 0.0 self.det_scale_ = np.ones(self.n_components)
559 1 8 8.0 0.0 self.bound_prec_ = np.zeros(self.n_components)
560 11 57 5.2 0.0 for k in xrange(self.n_components):
561 10 45 4.5 0.0 self.bound_prec_[k] = wishart_log_det(
562 10 62 6.2 0.0 self.dof_[k], self.scale_[k], self.det_scale_[k],
563 10 1193 119.3 0.1 n_features)
564 10 66 6.6 0.0 self.bound_prec_[k] -= (self.dof_[k] *
565 10 427 42.7 0.0 np.trace(self.scale_[k]))
566 1 16 16.0 0.0 self.bound_prec_ *= 0.5
567
568 1 5 5.0 0.0 logprob = []
569 # reset self.converged_ to False
570 1 6 6.0 0.0 self.converged_ = False
571 11 78 7.1 0.0 for i in xrange(self.n_iter):
572 # Expectation step
573 10 283661 28366.1 14.2 curr_logprob, z = self.eval(X)
574 10 57193 5719.3 2.9 logprob.append(curr_logprob.sum() + self._logprior(z))
575
576 # Check for convergence.
577 10 143 14.3 0.0 if i > 0 and abs(logprob[-1] - logprob[-2]) < self.thresh:
578 self.converged_ = True
579 break
580
581 # Maximization step
582 10 1451244 145124.4 72.4 self._do_mstep(X, z, self.params)
583
584 1 4 4.0 0.0 return self
File: /tmp/vb_sklearn/sklearn/mixture/gmm.py
Function: predict at line 353
Total time: 0.018989 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
353 def predict(self, X):
354 """Predict label for data.
355
356 Parameters
357 ----------
358 X : array-like, shape = [n_samples, n_features]
359
360 Returns
361 -------
362 C : array, shape = (n_samples,)
363 """
364 1 18949 18949.0 99.8 logprob, responsibilities = self.eval(X)
365 1 40 40.0 0.2 return responsibilities.argmax(axis=1)