Benchmarks for tree¶
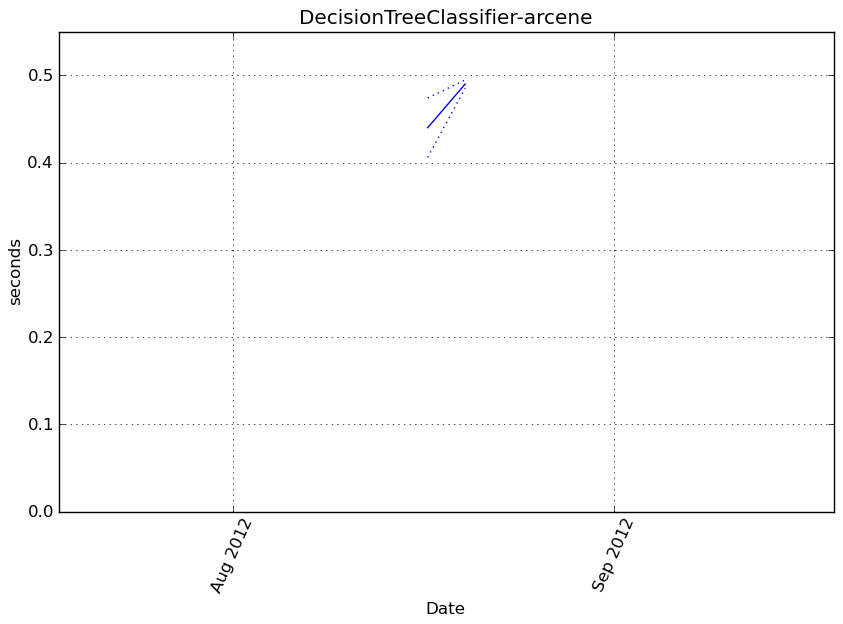
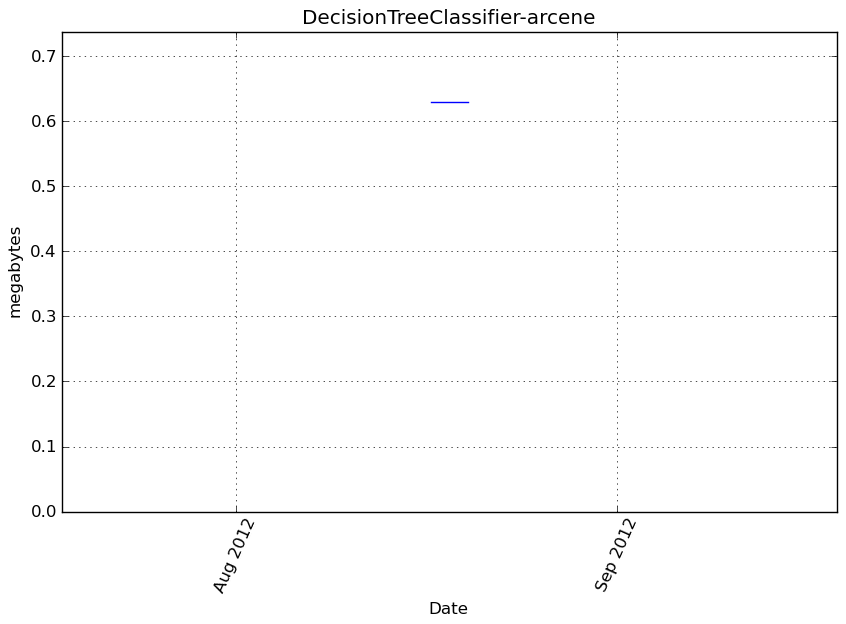
DecisionTreeClassifier-arcene¶
Benchmark setup
from sklearn.tree import DecisionTreeClassifier from deps import load_data kwargs = {} X, y, X_t, y_t = load_data('arcene') obj = DecisionTreeClassifier(**kwargs)
Benchmark statement
obj.fit(X, y)
Execution time
Memory usage
Additional output
cProfile
68 function calls in 0.429 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.429 0.429 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 0.429 0.429 <f>:1(<module>)
1 0.000 0.000 0.429 0.429 /tmp/vb_sklearn/sklearn/tree/tree.py:171(fit)
1 0.335 0.335 0.418 0.418 {method 'build' of 'sklearn.tree._tree.Tree' objects}
2 0.000 0.000 0.083 0.041 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:598(argsort)
2 0.083 0.041 0.083 0.041 {method 'argsort' of 'numpy.ndarray' objects}
1 0.000 0.000 0.011 0.011 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
8 0.011 0.001 0.011 0.001 {numpy.core.multiarray.array}
2 0.000 0.000 0.011 0.005 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1774(amax)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:32(_wrapit)
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.concatenate}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
1 0.000 0.000 0.000 0.000 {method 'sum' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:325(asfortranarray)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:6(atleast_1d)
1 0.000 0.000 0.000 0.000 {method 'max' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:781(copy)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:757(searchsorted)
4 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'sort' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:289(ascontiguousarray)
1 0.000 0.000 0.000 0.000 {method 'searchsorted' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
3 0.000 0.000 0.000 0.000 {getattr}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:449(isfortran)
2 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
6 0.000 0.000 0.000 0.000 {len}
4 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {max}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/tree/tree.py
Function: fit at line 171
Total time: 0.46102 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
171 def fit(self, X, y, sample_mask=None, X_argsorted=None):
172 """Build a decision tree from the training set (X, y).
173
174 Parameters
175 ----------
176 X : array-like of shape = [n_samples, n_features]
177 The training input samples. Use ``dtype=np.float32``
178 and ``order='F'`` for maximum efficiency.
179
180 y : array-like, shape = [n_samples] or [n_samples, n_outputs]
181 The target values (integers that correspond to classes in
182 classification, real numbers in regression).
183 Use ``dtype=np.float64`` and ``order='C'`` for maximum
184 efficiency.
185
186 Returns
187 -------
188 self : object
189 Returns self.
190 """
191 # set min_samples_split sensibly
192 1 5 5.0 0.0 self.min_samples_split = max(self.min_samples_split,
193 1 8 8.0 0.0 2 * self.min_samples_leaf)
194
195 # Convert data
196 1 9 9.0 0.0 if getattr(X, "dtype", None) != DTYPE or \
197 X.ndim != 2 or not X.flags.fortran:
198 1 9222 9222.0 2.0 X = array2d(X, dtype=DTYPE, order="F")
199
200 1 10 10.0 0.0 n_samples, self.n_features_ = X.shape
201
202 1 11 11.0 0.0 is_classification = isinstance(self, ClassifierMixin)
203
204 1 40 40.0 0.0 y = np.atleast_1d(y)
205 1 5 5.0 0.0 if y.ndim == 1:
206 1 16 16.0 0.0 y = y[:, np.newaxis]
207
208 1 4 4.0 0.0 self.classes_ = []
209 1 5 5.0 0.0 self.n_classes_ = []
210 1 5 5.0 0.0 self.n_outputs_ = y.shape[1]
211
212 1 4 4.0 0.0 if is_classification:
213 1 25 25.0 0.0 y = np.copy(y)
214
215 2 13 6.5 0.0 for k in xrange(self.n_outputs_):
216 1 115 115.0 0.0 unique = np.unique(y[:, k])
217 1 6 6.0 0.0 self.classes_.append(unique)
218 1 6 6.0 0.0 self.n_classes_.append(unique.shape[0])
219 1 32 32.0 0.0 y[:, k] = np.searchsorted(unique, y[:, k])
220
221 else:
222 self.classes_ = [None] * self.n_outputs_
223 self.n_classes_ = [1] * self.n_outputs_
224
225 1 8 8.0 0.0 if getattr(y, "dtype", None) != DOUBLE or not y.flags.contiguous:
226 1 18 18.0 0.0 y = np.ascontiguousarray(y, dtype=DOUBLE)
227
228 1 4 4.0 0.0 if is_classification:
229 1 5 5.0 0.0 criterion = CLASSIFICATION[self.criterion](self.n_outputs_,
230 1 8 8.0 0.0 self.n_classes_)
231 else:
232 criterion = REGRESSION[self.criterion](self.n_outputs_)
233
234 # Check parameters
235 1 5 5.0 0.0 max_depth = np.inf if self.max_depth is None else self.max_depth
236
237 1 8 8.0 0.0 if isinstance(self.max_features, basestring):
238 if self.max_features == "auto":
239 if is_classification:
240 max_features = max(1, int(np.sqrt(self.n_features_)))
241 else:
242 max_features = self.n_features_
243 elif self.max_features == "sqrt":
244 max_features = max(1, int(np.sqrt(self.n_features_)))
245 elif self.max_features == "log2":
246 max_features = max(1, int(np.log2(self.n_features_)))
247 else:
248 raise ValueError(
249 'Invalid value for max_features. Allowed string '
250 'values are "auto", "sqrt" or "log2".')
251 1 4 4.0 0.0 elif self.max_features is None:
252 1 4 4.0 0.0 max_features = self.n_features_
253 else:
254 max_features = self.max_features
255
256 1 5 5.0 0.0 if len(y) != n_samples:
257 raise ValueError("Number of labels=%d does not match "
258 "number of samples=%d" % (len(y), n_samples))
259 1 4 4.0 0.0 if self.min_samples_split <= 0:
260 raise ValueError("min_samples_split must be greater than zero.")
261 1 4 4.0 0.0 if self.min_samples_leaf <= 0:
262 raise ValueError("min_samples_leaf must be greater than zero.")
263 1 5 5.0 0.0 if max_depth <= 0:
264 raise ValueError("max_depth must be greater than zero. ")
265 1 5 5.0 0.0 if self.min_density < 0.0 or self.min_density > 1.0:
266 raise ValueError("min_density must be in [0, 1]")
267 1 5 5.0 0.0 if not (0 < max_features <= self.n_features_):
268 raise ValueError("max_features must be in (0, n_features]")
269 1 4 4.0 0.0 if sample_mask is not None and len(sample_mask) != n_samples:
270 raise ValueError("Length of sample_mask=%d does not match "
271 "number of samples=%d" % (len(sample_mask),
272 n_samples))
273 1 4 4.0 0.0 if X_argsorted is not None and len(X_argsorted) != n_samples:
274 raise ValueError("Length of X_argsorted=%d does not match "
275 "number of samples=%d" % (len(X_argsorted),
276 n_samples))
277
278 # Build tree
279 1 5 5.0 0.0 self.tree_ = _tree.Tree(self.n_features_, self.n_classes_,
280 1 4 4.0 0.0 self.n_outputs_, criterion, max_depth,
281 1 4 4.0 0.0 self.min_samples_split, self.min_samples_leaf,
282 1 4 4.0 0.0 self.min_density, max_features,
283 1 101 101.0 0.0 self.find_split_, self.random_state)
284
285 1 5 5.0 0.0 self.tree_.build(X, y, sample_mask=sample_mask,
286 1 451241 451241.0 97.9 X_argsorted=X_argsorted)
287
288 1 10 10.0 0.0 if self.compute_importances:
289 self.feature_importances_ = \
290 self.tree_.compute_feature_importances()
291
292 1 5 5.0 0.0 return self
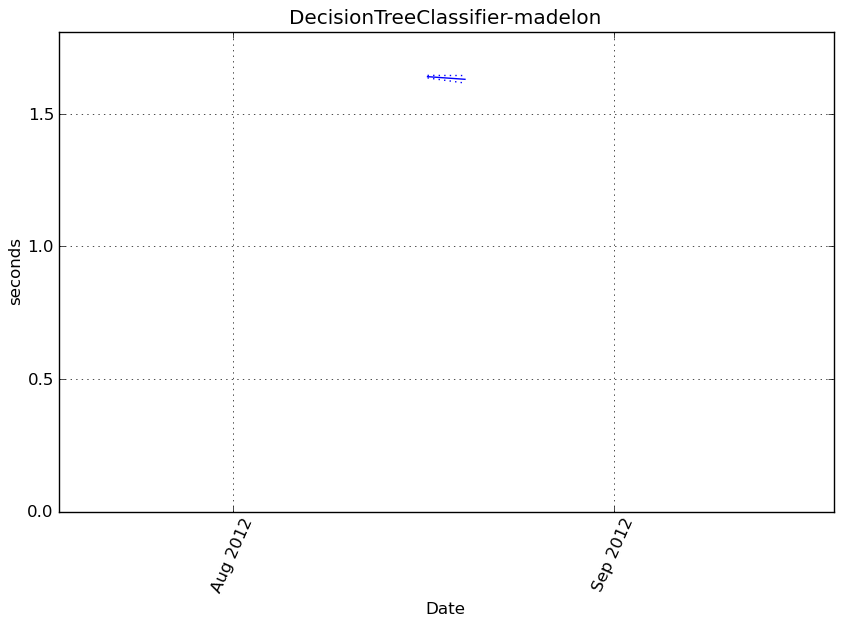
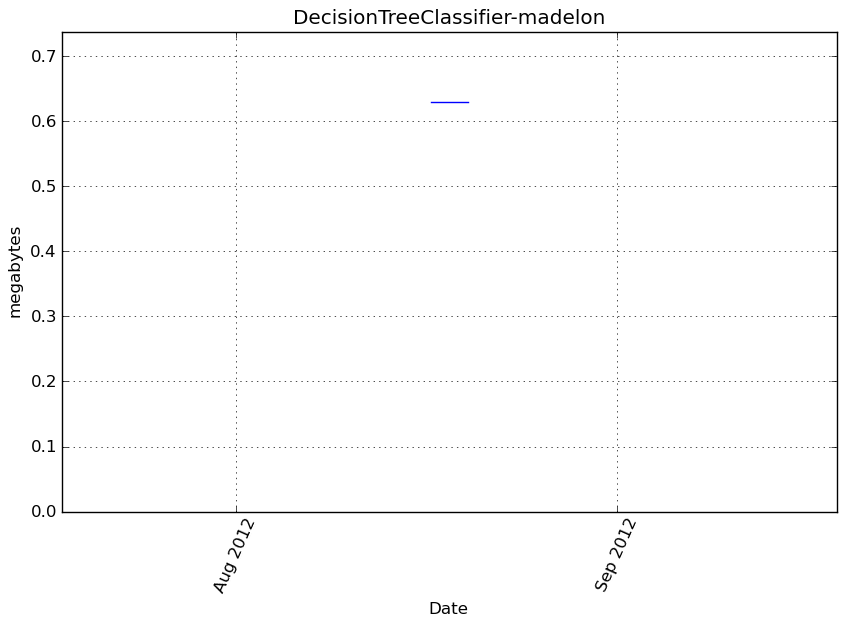
DecisionTreeClassifier-madelon¶
Benchmark setup
from sklearn.tree import DecisionTreeClassifier from deps import load_data kwargs = {} X, y, X_t, y_t = load_data('madelon') obj = DecisionTreeClassifier(**kwargs)
Benchmark statement
obj.fit(X, y)
Execution time
Memory usage
Additional output
cProfile
376 function calls in 1.581 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 1.581 1.581 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 1.581 1.581 <f>:1(<module>)
1 0.000 0.000 1.581 1.581 /tmp/vb_sklearn/sklearn/tree/tree.py:171(fit)
1 1.306 1.306 1.571 1.571 {method 'build' of 'sklearn.tree._tree.Tree' objects}
46 0.000 0.000 0.264 0.006 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:598(argsort)
46 0.263 0.006 0.263 0.006 {method 'argsort' of 'numpy.ndarray' objects}
52 0.010 0.000 0.010 0.000 {numpy.core.multiarray.array}
1 0.000 0.000 0.010 0.010 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
2 0.000 0.000 0.010 0.005 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
46 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
46 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:325(asfortranarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
46 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
46 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1774(amax)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:757(searchsorted)
1 0.000 0.000 0.000 0.000 {method 'searchsorted' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:32(_wrapit)
1 0.000 0.000 0.000 0.000 {method 'sort' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
1 0.000 0.000 0.000 0.000 {method 'sum' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.concatenate}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:6(atleast_1d)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:781(copy)
1 0.000 0.000 0.000 0.000 {method 'max' of 'numpy.ndarray' objects}
4 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:289(ascontiguousarray)
3 0.000 0.000 0.000 0.000 {getattr}
2 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
6 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:449(isfortran)
4 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {max}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/tree/tree.py
Function: fit at line 171
Total time: 1.64353 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
171 def fit(self, X, y, sample_mask=None, X_argsorted=None):
172 """Build a decision tree from the training set (X, y).
173
174 Parameters
175 ----------
176 X : array-like of shape = [n_samples, n_features]
177 The training input samples. Use ``dtype=np.float32``
178 and ``order='F'`` for maximum efficiency.
179
180 y : array-like, shape = [n_samples] or [n_samples, n_outputs]
181 The target values (integers that correspond to classes in
182 classification, real numbers in regression).
183 Use ``dtype=np.float64`` and ``order='C'`` for maximum
184 efficiency.
185
186 Returns
187 -------
188 self : object
189 Returns self.
190 """
191 # set min_samples_split sensibly
192 1 5 5.0 0.0 self.min_samples_split = max(self.min_samples_split,
193 1 7 7.0 0.0 2 * self.min_samples_leaf)
194
195 # Convert data
196 1 9 9.0 0.0 if getattr(X, "dtype", None) != DTYPE or \
197 X.ndim != 2 or not X.flags.fortran:
198 1 7458 7458.0 0.5 X = array2d(X, dtype=DTYPE, order="F")
199
200 1 10 10.0 0.0 n_samples, self.n_features_ = X.shape
201
202 1 10 10.0 0.0 is_classification = isinstance(self, ClassifierMixin)
203
204 1 37 37.0 0.0 y = np.atleast_1d(y)
205 1 4 4.0 0.0 if y.ndim == 1:
206 1 14 14.0 0.0 y = y[:, np.newaxis]
207
208 1 4 4.0 0.0 self.classes_ = []
209 1 4 4.0 0.0 self.n_classes_ = []
210 1 5 5.0 0.0 self.n_outputs_ = y.shape[1]
211
212 1 3 3.0 0.0 if is_classification:
213 1 26 26.0 0.0 y = np.copy(y)
214
215 2 12 6.0 0.0 for k in xrange(self.n_outputs_):
216 1 193 193.0 0.0 unique = np.unique(y[:, k])
217 1 6 6.0 0.0 self.classes_.append(unique)
218 1 6 6.0 0.0 self.n_classes_.append(unique.shape[0])
219 1 89 89.0 0.0 y[:, k] = np.searchsorted(unique, y[:, k])
220
221 else:
222 self.classes_ = [None] * self.n_outputs_
223 self.n_classes_ = [1] * self.n_outputs_
224
225 1 8 8.0 0.0 if getattr(y, "dtype", None) != DOUBLE or not y.flags.contiguous:
226 1 20 20.0 0.0 y = np.ascontiguousarray(y, dtype=DOUBLE)
227
228 1 4 4.0 0.0 if is_classification:
229 1 5 5.0 0.0 criterion = CLASSIFICATION[self.criterion](self.n_outputs_,
230 1 8 8.0 0.0 self.n_classes_)
231 else:
232 criterion = REGRESSION[self.criterion](self.n_outputs_)
233
234 # Check parameters
235 1 5 5.0 0.0 max_depth = np.inf if self.max_depth is None else self.max_depth
236
237 1 7 7.0 0.0 if isinstance(self.max_features, basestring):
238 if self.max_features == "auto":
239 if is_classification:
240 max_features = max(1, int(np.sqrt(self.n_features_)))
241 else:
242 max_features = self.n_features_
243 elif self.max_features == "sqrt":
244 max_features = max(1, int(np.sqrt(self.n_features_)))
245 elif self.max_features == "log2":
246 max_features = max(1, int(np.log2(self.n_features_)))
247 else:
248 raise ValueError(
249 'Invalid value for max_features. Allowed string '
250 'values are "auto", "sqrt" or "log2".')
251 1 4 4.0 0.0 elif self.max_features is None:
252 1 4 4.0 0.0 max_features = self.n_features_
253 else:
254 max_features = self.max_features
255
256 1 5 5.0 0.0 if len(y) != n_samples:
257 raise ValueError("Number of labels=%d does not match "
258 "number of samples=%d" % (len(y), n_samples))
259 1 4 4.0 0.0 if self.min_samples_split <= 0:
260 raise ValueError("min_samples_split must be greater than zero.")
261 1 4 4.0 0.0 if self.min_samples_leaf <= 0:
262 raise ValueError("min_samples_leaf must be greater than zero.")
263 1 5 5.0 0.0 if max_depth <= 0:
264 raise ValueError("max_depth must be greater than zero. ")
265 1 4 4.0 0.0 if self.min_density < 0.0 or self.min_density > 1.0:
266 raise ValueError("min_density must be in [0, 1]")
267 1 4 4.0 0.0 if not (0 < max_features <= self.n_features_):
268 raise ValueError("max_features must be in (0, n_features]")
269 1 4 4.0 0.0 if sample_mask is not None and len(sample_mask) != n_samples:
270 raise ValueError("Length of sample_mask=%d does not match "
271 "number of samples=%d" % (len(sample_mask),
272 n_samples))
273 1 4 4.0 0.0 if X_argsorted is not None and len(X_argsorted) != n_samples:
274 raise ValueError("Length of X_argsorted=%d does not match "
275 "number of samples=%d" % (len(X_argsorted),
276 n_samples))
277
278 # Build tree
279 1 5 5.0 0.0 self.tree_ = _tree.Tree(self.n_features_, self.n_classes_,
280 1 4 4.0 0.0 self.n_outputs_, criterion, max_depth,
281 1 3 3.0 0.0 self.min_samples_split, self.min_samples_leaf,
282 1 4 4.0 0.0 self.min_density, max_features,
283 1 96 96.0 0.0 self.find_split_, self.random_state)
284
285 1 8 8.0 0.0 self.tree_.build(X, y, sample_mask=sample_mask,
286 1 1635398 1635398.0 99.5 X_argsorted=X_argsorted)
287
288 1 6 6.0 0.0 if self.compute_importances:
289 self.feature_importances_ = \
290 self.tree_.compute_feature_importances()
291
292 1 2 2.0 0.0 return self
ExtraTreeClassifier-arcene¶
Benchmark setup
from sklearn.tree import ExtraTreeClassifier from deps import load_data kwargs = {} X, y, X_t, y_t = load_data('arcene') obj = ExtraTreeClassifier(**kwargs)
Benchmark statement
obj.fit(X, y)
Execution time
Memory usage
Additional output
cProfile
97 function calls in 0.172 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.172 0.172 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 0.172 0.172 <f>:1(<module>)
1 0.000 0.000 0.172 0.172 /tmp/vb_sklearn/sklearn/tree/tree.py:171(fit)
1 0.114 0.114 0.164 0.164 {method 'build' of 'sklearn.tree._tree.Tree' objects}
6 0.000 0.000 0.050 0.008 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:598(argsort)
6 0.050 0.008 0.050 0.008 {method 'argsort' of 'numpy.ndarray' objects}
1 0.000 0.000 0.007 0.007 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
12 0.007 0.001 0.007 0.001 {numpy.core.multiarray.array}
2 0.000 0.000 0.007 0.004 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1774(amax)
6 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
6 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:325(asfortranarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:32(_wrapit)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
1 0.000 0.000 0.000 0.000 {method 'sum' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.concatenate}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:6(atleast_1d)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:781(copy)
6 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'max' of 'numpy.ndarray' objects}
6 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
4 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:757(searchsorted)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:289(ascontiguousarray)
1 0.000 0.000 0.000 0.000 {method 'searchsorted' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'sort' of 'numpy.ndarray' objects}
3 0.000 0.000 0.000 0.000 {getattr}
2 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:449(isfortran)
2 0.000 0.000 0.000 0.000 {max}
6 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
4 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/tree/tree.py
Function: fit at line 171
Total time: 0.273924 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
171 def fit(self, X, y, sample_mask=None, X_argsorted=None):
172 """Build a decision tree from the training set (X, y).
173
174 Parameters
175 ----------
176 X : array-like of shape = [n_samples, n_features]
177 The training input samples. Use ``dtype=np.float32``
178 and ``order='F'`` for maximum efficiency.
179
180 y : array-like, shape = [n_samples] or [n_samples, n_outputs]
181 The target values (integers that correspond to classes in
182 classification, real numbers in regression).
183 Use ``dtype=np.float64`` and ``order='C'`` for maximum
184 efficiency.
185
186 Returns
187 -------
188 self : object
189 Returns self.
190 """
191 # set min_samples_split sensibly
192 1 4 4.0 0.0 self.min_samples_split = max(self.min_samples_split,
193 1 4 4.0 0.0 2 * self.min_samples_leaf)
194
195 # Convert data
196 1 6 6.0 0.0 if getattr(X, "dtype", None) != DTYPE or \
197 X.ndim != 2 or not X.flags.fortran:
198 1 5716 5716.0 2.1 X = array2d(X, dtype=DTYPE, order="F")
199
200 1 7 7.0 0.0 n_samples, self.n_features_ = X.shape
201
202 1 8 8.0 0.0 is_classification = isinstance(self, ClassifierMixin)
203
204 1 28 28.0 0.0 y = np.atleast_1d(y)
205 1 3 3.0 0.0 if y.ndim == 1:
206 1 12 12.0 0.0 y = y[:, np.newaxis]
207
208 1 2 2.0 0.0 self.classes_ = []
209 1 3 3.0 0.0 self.n_classes_ = []
210 1 3 3.0 0.0 self.n_outputs_ = y.shape[1]
211
212 1 2 2.0 0.0 if is_classification:
213 1 18 18.0 0.0 y = np.copy(y)
214
215 2 8 4.0 0.0 for k in xrange(self.n_outputs_):
216 1 77 77.0 0.0 unique = np.unique(y[:, k])
217 1 3 3.0 0.0 self.classes_.append(unique)
218 1 4 4.0 0.0 self.n_classes_.append(unique.shape[0])
219 1 19 19.0 0.0 y[:, k] = np.searchsorted(unique, y[:, k])
220
221 else:
222 self.classes_ = [None] * self.n_outputs_
223 self.n_classes_ = [1] * self.n_outputs_
224
225 1 5 5.0 0.0 if getattr(y, "dtype", None) != DOUBLE or not y.flags.contiguous:
226 1 12 12.0 0.0 y = np.ascontiguousarray(y, dtype=DOUBLE)
227
228 1 3 3.0 0.0 if is_classification:
229 1 4 4.0 0.0 criterion = CLASSIFICATION[self.criterion](self.n_outputs_,
230 1 5 5.0 0.0 self.n_classes_)
231 else:
232 criterion = REGRESSION[self.criterion](self.n_outputs_)
233
234 # Check parameters
235 1 3 3.0 0.0 max_depth = np.inf if self.max_depth is None else self.max_depth
236
237 1 5 5.0 0.0 if isinstance(self.max_features, basestring):
238 1 3 3.0 0.0 if self.max_features == "auto":
239 1 2 2.0 0.0 if is_classification:
240 1 21 21.0 0.0 max_features = max(1, int(np.sqrt(self.n_features_)))
241 else:
242 max_features = self.n_features_
243 elif self.max_features == "sqrt":
244 max_features = max(1, int(np.sqrt(self.n_features_)))
245 elif self.max_features == "log2":
246 max_features = max(1, int(np.log2(self.n_features_)))
247 else:
248 raise ValueError(
249 'Invalid value for max_features. Allowed string '
250 'values are "auto", "sqrt" or "log2".')
251 elif self.max_features is None:
252 max_features = self.n_features_
253 else:
254 max_features = self.max_features
255
256 1 3 3.0 0.0 if len(y) != n_samples:
257 raise ValueError("Number of labels=%d does not match "
258 "number of samples=%d" % (len(y), n_samples))
259 1 3 3.0 0.0 if self.min_samples_split <= 0:
260 raise ValueError("min_samples_split must be greater than zero.")
261 1 3 3.0 0.0 if self.min_samples_leaf <= 0:
262 raise ValueError("min_samples_leaf must be greater than zero.")
263 1 3 3.0 0.0 if max_depth <= 0:
264 raise ValueError("max_depth must be greater than zero. ")
265 1 3 3.0 0.0 if self.min_density < 0.0 or self.min_density > 1.0:
266 raise ValueError("min_density must be in [0, 1]")
267 1 3 3.0 0.0 if not (0 < max_features <= self.n_features_):
268 raise ValueError("max_features must be in (0, n_features]")
269 1 2 2.0 0.0 if sample_mask is not None and len(sample_mask) != n_samples:
270 raise ValueError("Length of sample_mask=%d does not match "
271 "number of samples=%d" % (len(sample_mask),
272 n_samples))
273 1 3 3.0 0.0 if X_argsorted is not None and len(X_argsorted) != n_samples:
274 raise ValueError("Length of X_argsorted=%d does not match "
275 "number of samples=%d" % (len(X_argsorted),
276 n_samples))
277
278 # Build tree
279 1 4 4.0 0.0 self.tree_ = _tree.Tree(self.n_features_, self.n_classes_,
280 1 3 3.0 0.0 self.n_outputs_, criterion, max_depth,
281 1 2 2.0 0.0 self.min_samples_split, self.min_samples_leaf,
282 1 2 2.0 0.0 self.min_density, max_features,
283 1 64 64.0 0.0 self.find_split_, self.random_state)
284
285 1 3 3.0 0.0 self.tree_.build(X, y, sample_mask=sample_mask,
286 1 267825 267825.0 97.8 X_argsorted=X_argsorted)
287
288 1 6 6.0 0.0 if self.compute_importances:
289 self.feature_importances_ = \
290 self.tree_.compute_feature_importances()
291
292 1 2 2.0 0.0 return self
ExtraTreeClassifier-madelon¶
Benchmark setup
from sklearn.tree import ExtraTreeClassifier from deps import load_data kwargs = {} X, y, X_t, y_t = load_data('madelon') obj = ExtraTreeClassifier(**kwargs)
Benchmark statement
obj.fit(X, y)
Execution time
Memory usage
Additional output
cProfile
1196 function calls in 0.621 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.621 0.621 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 0.621 0.621 <f>:1(<module>)
1 0.000 0.000 0.621 0.621 /tmp/vb_sklearn/sklearn/tree/tree.py:171(fit)
1 0.397 0.397 0.615 0.615 {method 'build' of 'sklearn.tree._tree.Tree' objects}
163 0.000 0.000 0.216 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:598(argsort)
163 0.215 0.001 0.215 0.001 {method 'argsort' of 'numpy.ndarray' objects}
169 0.006 0.000 0.006 0.000 {numpy.core.multiarray.array}
1 0.000 0.000 0.006 0.006 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
2 0.000 0.000 0.006 0.003 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
163 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
163 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:325(asfortranarray)
163 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
163 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1774(amax)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:757(searchsorted)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:32(_wrapit)
1 0.000 0.000 0.000 0.000 {method 'searchsorted' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'sort' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'sum' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.concatenate}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:6(atleast_1d)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:781(copy)
1 0.000 0.000 0.000 0.000 {method 'max' of 'numpy.ndarray' objects}
4 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:289(ascontiguousarray)
1 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
3 0.000 0.000 0.000 0.000 {getattr}
2 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
6 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:449(isfortran)
2 0.000 0.000 0.000 0.000 {max}
4 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/tree/tree.py
Function: fit at line 171
Total time: 0.741077 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
171 def fit(self, X, y, sample_mask=None, X_argsorted=None):
172 """Build a decision tree from the training set (X, y).
173
174 Parameters
175 ----------
176 X : array-like of shape = [n_samples, n_features]
177 The training input samples. Use ``dtype=np.float32``
178 and ``order='F'`` for maximum efficiency.
179
180 y : array-like, shape = [n_samples] or [n_samples, n_outputs]
181 The target values (integers that correspond to classes in
182 classification, real numbers in regression).
183 Use ``dtype=np.float64`` and ``order='C'`` for maximum
184 efficiency.
185
186 Returns
187 -------
188 self : object
189 Returns self.
190 """
191 # set min_samples_split sensibly
192 1 4 4.0 0.0 self.min_samples_split = max(self.min_samples_split,
193 1 4 4.0 0.0 2 * self.min_samples_leaf)
194
195 # Convert data
196 1 6 6.0 0.0 if getattr(X, "dtype", None) != DTYPE or \
197 X.ndim != 2 or not X.flags.fortran:
198 1 4802 4802.0 0.6 X = array2d(X, dtype=DTYPE, order="F")
199
200 1 7 7.0 0.0 n_samples, self.n_features_ = X.shape
201
202 1 8 8.0 0.0 is_classification = isinstance(self, ClassifierMixin)
203
204 1 27 27.0 0.0 y = np.atleast_1d(y)
205 1 2 2.0 0.0 if y.ndim == 1:
206 1 11 11.0 0.0 y = y[:, np.newaxis]
207
208 1 3 3.0 0.0 self.classes_ = []
209 1 2 2.0 0.0 self.n_classes_ = []
210 1 3 3.0 0.0 self.n_outputs_ = y.shape[1]
211
212 1 2 2.0 0.0 if is_classification:
213 1 20 20.0 0.0 y = np.copy(y)
214
215 2 9 4.5 0.0 for k in xrange(self.n_outputs_):
216 1 130 130.0 0.0 unique = np.unique(y[:, k])
217 1 4 4.0 0.0 self.classes_.append(unique)
218 1 3 3.0 0.0 self.n_classes_.append(unique.shape[0])
219 1 58 58.0 0.0 y[:, k] = np.searchsorted(unique, y[:, k])
220
221 else:
222 self.classes_ = [None] * self.n_outputs_
223 self.n_classes_ = [1] * self.n_outputs_
224
225 1 6 6.0 0.0 if getattr(y, "dtype", None) != DOUBLE or not y.flags.contiguous:
226 1 15 15.0 0.0 y = np.ascontiguousarray(y, dtype=DOUBLE)
227
228 1 2 2.0 0.0 if is_classification:
229 1 3 3.0 0.0 criterion = CLASSIFICATION[self.criterion](self.n_outputs_,
230 1 6 6.0 0.0 self.n_classes_)
231 else:
232 criterion = REGRESSION[self.criterion](self.n_outputs_)
233
234 # Check parameters
235 1 3 3.0 0.0 max_depth = np.inf if self.max_depth is None else self.max_depth
236
237 1 6 6.0 0.0 if isinstance(self.max_features, basestring):
238 1 3 3.0 0.0 if self.max_features == "auto":
239 1 4 4.0 0.0 if is_classification:
240 1 23 23.0 0.0 max_features = max(1, int(np.sqrt(self.n_features_)))
241 else:
242 max_features = self.n_features_
243 elif self.max_features == "sqrt":
244 max_features = max(1, int(np.sqrt(self.n_features_)))
245 elif self.max_features == "log2":
246 max_features = max(1, int(np.log2(self.n_features_)))
247 else:
248 raise ValueError(
249 'Invalid value for max_features. Allowed string '
250 'values are "auto", "sqrt" or "log2".')
251 elif self.max_features is None:
252 max_features = self.n_features_
253 else:
254 max_features = self.max_features
255
256 1 3 3.0 0.0 if len(y) != n_samples:
257 raise ValueError("Number of labels=%d does not match "
258 "number of samples=%d" % (len(y), n_samples))
259 1 2 2.0 0.0 if self.min_samples_split <= 0:
260 raise ValueError("min_samples_split must be greater than zero.")
261 1 3 3.0 0.0 if self.min_samples_leaf <= 0:
262 raise ValueError("min_samples_leaf must be greater than zero.")
263 1 3 3.0 0.0 if max_depth <= 0:
264 raise ValueError("max_depth must be greater than zero. ")
265 1 3 3.0 0.0 if self.min_density < 0.0 or self.min_density > 1.0:
266 raise ValueError("min_density must be in [0, 1]")
267 1 3 3.0 0.0 if not (0 < max_features <= self.n_features_):
268 raise ValueError("max_features must be in (0, n_features]")
269 1 2 2.0 0.0 if sample_mask is not None and len(sample_mask) != n_samples:
270 raise ValueError("Length of sample_mask=%d does not match "
271 "number of samples=%d" % (len(sample_mask),
272 n_samples))
273 1 2 2.0 0.0 if X_argsorted is not None and len(X_argsorted) != n_samples:
274 raise ValueError("Length of X_argsorted=%d does not match "
275 "number of samples=%d" % (len(X_argsorted),
276 n_samples))
277
278 # Build tree
279 1 3 3.0 0.0 self.tree_ = _tree.Tree(self.n_features_, self.n_classes_,
280 1 3 3.0 0.0 self.n_outputs_, criterion, max_depth,
281 1 2 2.0 0.0 self.min_samples_split, self.min_samples_leaf,
282 1 2 2.0 0.0 self.min_density, max_features,
283 1 66 66.0 0.0 self.find_split_, self.random_state)
284
285 1 3 3.0 0.0 self.tree_.build(X, y, sample_mask=sample_mask,
286 1 735787 735787.0 99.3 X_argsorted=X_argsorted)
287
288 1 10 10.0 0.0 if self.compute_importances:
289 self.feature_importances_ = \
290 self.tree_.compute_feature_importances()
291
292 1 4 4.0 0.0 return self