Benchmarks for semi_supervised¶
LabelSpreading-knn-arcene-semi¶
Benchmark setup
from sklearn.semi_supervised import LabelSpreading from deps import load_data kwargs = {'kernel': 'knn'} X, y, X_t, y_t = load_data('arcene-semi') obj = LabelSpreading(**kwargs)
Benchmark statement
obj.fit(X, y)
Execution time
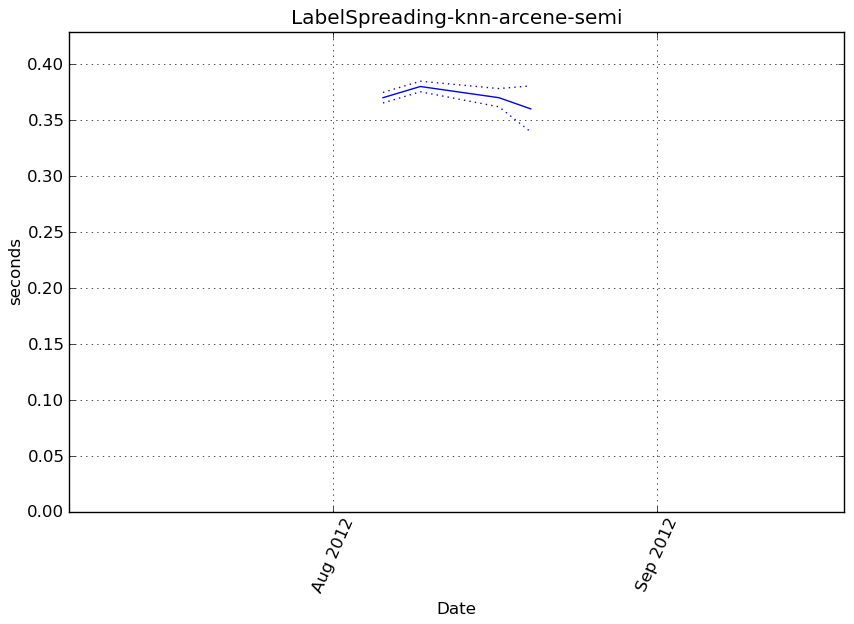
Memory usage
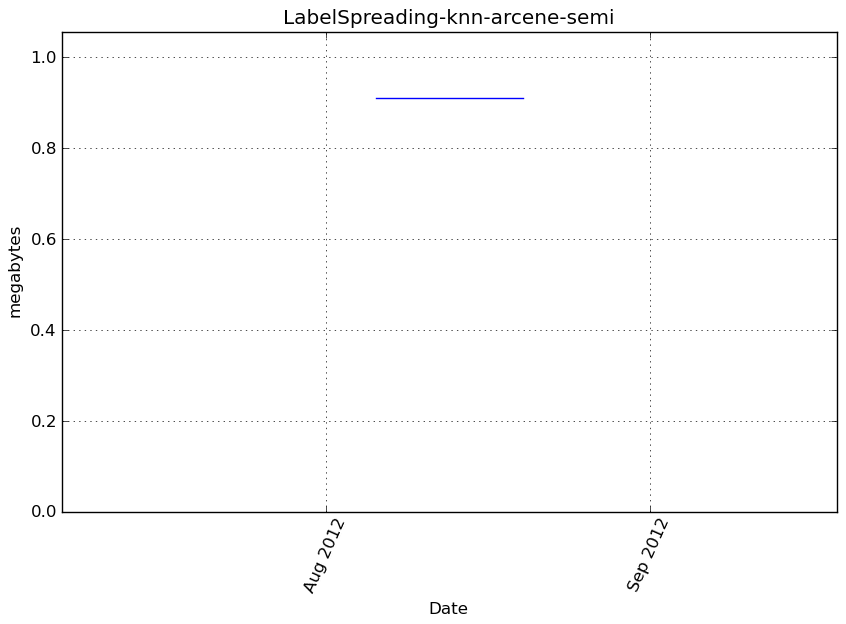
Additional output
cProfile
1310 function calls (1309 primitive calls) in 0.321 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.321 0.321 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 0.321 0.321 <f>:1(<module>)
1 0.001 0.001 0.321 0.321 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:185(fit)
1 0.000 0.000 0.316 0.316 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:377(_build_graph)
1 0.000 0.000 0.315 0.315 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:112(_get_kernel)
1 0.000 0.000 0.287 0.287 /tmp/vb_sklearn/sklearn/neighbors/base.py:261(kneighbors_graph)
1 0.000 0.000 0.287 0.287 /tmp/vb_sklearn/sklearn/neighbors/base.py:156(kneighbors)
1 0.284 0.284 0.284 0.284 {method 'query' of 'sklearn.neighbors.ball_tree.BallTree' objects}
1 0.000 0.000 0.027 0.027 /tmp/vb_sklearn/sklearn/neighbors/base.py:578(fit)
1 0.025 0.025 0.027 0.027 /tmp/vb_sklearn/sklearn/neighbors/base.py:96(_fit)
20 0.006 0.000 0.006 0.000 {method 'sum' of 'numpy.ndarray' objects}
2 0.000 0.000 0.006 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
15 0.000 0.000 0.003 0.000 /tmp/vb_sklearn/sklearn/utils/extmath.py:70(safe_sparse_dot)
16 0.000 0.000 0.003 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:229(__mul__)
1 0.000 0.000 0.003 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
1 0.000 0.000 0.003 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:23(safe_asarray)
15 0.000 0.000 0.002 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:250(_mul_vector)
1 0.000 0.000 0.002 0.002 /tmp/vb_sklearn/sklearn/utils/graph.py:132(graph_laplacian)
1 0.000 0.000 0.001 0.001 /tmp/vb_sklearn/sklearn/utils/graph.py:78(_graph_laplacian_sparse)
17 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:18(upcast)
106 0.001 0.000 0.001 0.000 {numpy.core.multiarray.array}
3 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:20(__init__)
59 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
43 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
1 0.000 0.000 0.001 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/coo.py:281(tocsr)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/data.py:35(__neg__)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:486(sum)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/coo.py:115(__init__)
3 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:101(check_format)
16 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:70(_not_converged)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:526(tocoo)
16 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:77(isscalarlike)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/coo.py:205(_check)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:643(_with_data)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/coo.py:370(_mul_vector)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/coo.py:354(_with_data)
15 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/csr.py:287(csr_matvec)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:567(sum_duplicates)
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:622(prune)
16 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:124(isdense)
39 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
118 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
112 0.000 0.000 0.000 0.000 {isinstance}
15 0.000 0.000 0.000 0.000 {_csr.csr_matvec}
170 0.000 0.000 0.000 0.000 {numpy.core.multiarray.can_cast}
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
18 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
16 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1044(ravel)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:613(sort_indices)
18 0.000 0.000 0.000 0.000 {numpy.core.multiarray.zeros}
16 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1574(isscalar)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/matrixlib/defmatrix.py:55(asmatrix)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
7 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/coo.py:194(getnnz)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/matrixlib/defmatrix.py:233(__new__)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
5 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:96(isshape)
4 0.000 0.000 0.000 0.000 {method 'max' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numerictypes.py:733(issubdtype)
5 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/data.py:17(__init__)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:581(__get_sorted)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/csr.py:529(csr_sort_indices)
16 0.000 0.000 0.000 0.000 {method 'reshape' of 'numpy.ndarray' objects}
3 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
1 0.000 0.000 0.000 0.000 {_csr.csr_sort_indices}
5 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:50(to_native)
2 0.000 0.000 0.000 0.000 {method 'view' of 'numpy.ndarray' objects}
5 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:59(set_shape)
4 0.000 0.000 0.000 0.000 {method 'min' of 'numpy.ndarray' objects}
7 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.concatenate}
67 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:81(get_shape)
19 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
5 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:51(__init__)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/coo.py:75(coo_tocsr)
4/3 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/matrixlib/defmatrix.py:279(__array_finalize__)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/coo.py:174(coo_matvec)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/neighbors/unsupervised.py:85(__init__)
70 0.000 0.000 0.000 0.000 {len}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:81(isintlike)
1 0.000 0.000 0.000 0.000 {hasattr}
20 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/data.py:20(_get_dtype)
6 0.000 0.000 0.000 0.000 {method 'copy' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {_coo.coo_tocsr}
30 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:2116(rank)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/csr.py:70(expandptr)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:683(argmax)
15 0.000 0.000 0.000 0.000 {getattr}
16 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:85(getnnz)
3 0.000 0.000 0.000 0.000 {method 'astype' of 'numpy.ndarray' objects}
3 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:111(issequence)
1 0.000 0.000 0.000 0.000 {_coo.coo_matvec}
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.arange}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/neighbors/base.py:77(_init_params)
1 0.000 0.000 0.000 0.000 {method 'mro' of 'type' objects}
13 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/csr.py:180(_swap)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numerictypes.py:665(issubclass_)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/csr.py:85(csr_has_sorted_indices)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/csr.py:567(csr_sum_duplicates)
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:370(__getattr__)
5 0.000 0.000 0.000 0.000 {method 'newbyteorder' of 'numpy.dtype' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:781(copy)
1 0.000 0.000 0.000 0.000 {_csr.csr_sum_duplicates}
3 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:54(getdtype)
1 0.000 0.000 0.000 0.000 {_csr.expandptr}
1 0.000 0.000 0.000 0.000 {method 'sort' of 'numpy.ndarray' objects}
4 0.000 0.000 0.000 0.000 {issubclass}
1 0.000 0.000 0.000 0.000 {_csr.csr_has_sorted_indices}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:597(__set_sorted)
1 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'squeeze' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: predict at line 135
Total time: 0 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
135 def predict(self, X):
136 """Performs inductive inference across the model.
137
138 Parameters
139 ----------
140 X : array_like, shape = [n_samples, n_features]
141
142 Returns
143 -------
144 y : array_like, shape = [n_samples]
145 Predictions for input data
146 """
147 probas = self.predict_proba(X)
148 return self.classes_[np.argmax(probas, axis=1)].ravel()
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: fit at line 185
Total time: 0.364085 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
185 def fit(self, X, y):
186 """Fit a semi-supervised label propagation model based
187
188 All the input data is provided matrix X (labeled and unlabeled)
189 and corresponding label matrix y with a dedicated marker value for
190 unlabeled samples.
191
192 Parameters
193 ----------
194 X : array-like, shape = [n_samples, n_features]
195 A {n_samples by n_samples} size matrix will be created from this
196
197 y : array_like, shape = [n_samples]
198 n_labeled_samples (unlabeled points are marked as -1)
199 All unlabeled samples will be transductively assigned labels
200
201 Returns
202 -------
203 self : returns an instance of self.
204 """
205 1 18 18.0 0.0 if sparse.isspmatrix(X):
206 self.X_ = X
207 else:
208 1 8 8.0 0.0 self.X_ = np.asarray(X)
209
210 # actual graph construction (implementations should override this)
211 1 360556 360556.0 99.0 graph_matrix = self._build_graph()
212
213 # label construction
214 # construct a categorical distribution for classification only
215 1 51 51.0 0.0 classes = np.unique(y)
216 1 24 24.0 0.0 classes = (classes[classes != -1])
217 1 2 2.0 0.0 self.classes_ = classes
218
219 1 3 3.0 0.0 n_samples, n_classes = len(y), len(classes)
220
221 1 8 8.0 0.0 y = np.asarray(y)
222 1 9 9.0 0.0 unlabeled = y == -1
223 1 10 10.0 0.0 clamp_weights = np.ones((n_samples, 1))
224 1 18 18.0 0.0 clamp_weights[unlabeled, 0] = self.alpha
225
226 # initialize distributions
227 1 6 6.0 0.0 self.label_distributions_ = np.zeros((n_samples, n_classes))
228 2 7 3.5 0.0 for label in classes:
229 1 20 20.0 0.0 self.label_distributions_[y == label, classes == label] = 1
230
231 1 8 8.0 0.0 y_static = np.copy(self.label_distributions_)
232 1 2 2.0 0.0 if self.alpha > 0.:
233 1 10 10.0 0.0 y_static *= 1 - self.alpha
234 1 18 18.0 0.0 y_static[unlabeled] = 0
235
236 1 5 5.0 0.0 l_previous = np.zeros((self.X_.shape[0], n_classes))
237
238 1 2 2.0 0.0 remaining_iter = self.max_iters
239 1 14 14.0 0.0 if sparse.isspmatrix(graph_matrix):
240 1 383 383.0 0.1 graph_matrix = graph_matrix.tocsr()
241 16 329 20.6 0.1 while (_not_converged(self.label_distributions_, l_previous, self.tol)
242 15 28 1.9 0.0 and remaining_iter > 1):
243 15 29 1.9 0.0 l_previous = self.label_distributions_
244 15 23 1.5 0.0 self.label_distributions_ = safe_sparse_dot(graph_matrix,
245 15 2201 146.7 0.6 self.label_distributions_)
246 # clamp
247 15 33 2.2 0.0 self.label_distributions_ = np.multiply(clamp_weights,
248 15 175 11.7 0.0 self.label_distributions_) + y_static
249 15 28 1.9 0.0 remaining_iter -= 1
250
251 1 22 22.0 0.0 normalizer = np.sum(self.label_distributions_, axis=1)[:, np.newaxis]
252 1 13 13.0 0.0 self.label_distributions_ /= normalizer
253 # set the transduction item
254 1 2 2.0 0.0 transduction = self.classes_[np.argmax(self.label_distributions_,
255 1 15 15.0 0.0 axis=1)]
256 1 4 4.0 0.0 self.transduction_ = transduction.ravel()
257 1 1 1.0 0.0 return self
Benchmark statement
obj.predict(X_t)
Execution time
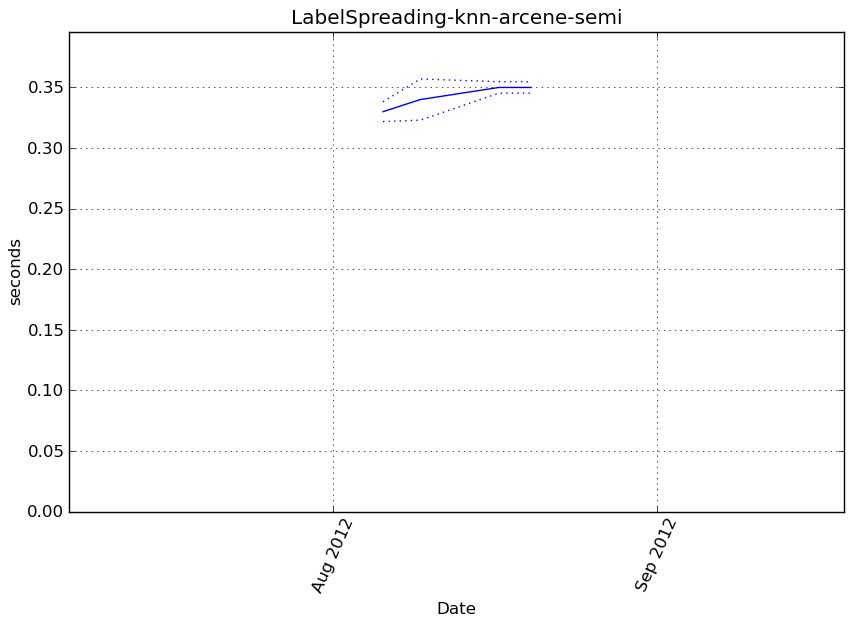
Memory usage
Additional output
cProfile
472 function calls in 0.263 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.263 0.263 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 0.263 0.263 <f>:1(<module>)
1 0.000 0.000 0.263 0.263 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:135(predict)
1 0.001 0.001 0.263 0.263 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:150(predict_proba)
1 0.000 0.000 0.262 0.262 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:112(_get_kernel)
1 0.000 0.000 0.262 0.262 /tmp/vb_sklearn/sklearn/neighbors/base.py:156(kneighbors)
1 0.259 0.259 0.259 0.259 {method 'query' of 'sklearn.neighbors.ball_tree.BallTree' objects}
102 0.003 0.000 0.003 0.000 {method 'sum' of 'numpy.ndarray' objects}
1 0.000 0.000 0.003 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
1 0.000 0.000 0.003 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
101 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
105 0.000 0.000 0.000 0.000 {isinstance}
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
7 0.000 0.000 0.000 0.000 {numpy.core.multiarray.array}
104 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
8 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
12 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:683(argmax)
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: predict at line 135
Total time: 0.639773 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
135 def predict(self, X):
136 """Performs inductive inference across the model.
137
138 Parameters
139 ----------
140 X : array_like, shape = [n_samples, n_features]
141
142 Returns
143 -------
144 y : array_like, shape = [n_samples]
145 Predictions for input data
146 """
147 1 639669 639669.0 100.0 probas = self.predict_proba(X)
148 1 104 104.0 0.0 return self.classes_[np.argmax(probas, axis=1)].ravel()
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: fit at line 185
Total time: 0.364085 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
185 def fit(self, X, y):
186 """Fit a semi-supervised label propagation model based
187
188 All the input data is provided matrix X (labeled and unlabeled)
189 and corresponding label matrix y with a dedicated marker value for
190 unlabeled samples.
191
192 Parameters
193 ----------
194 X : array-like, shape = [n_samples, n_features]
195 A {n_samples by n_samples} size matrix will be created from this
196
197 y : array_like, shape = [n_samples]
198 n_labeled_samples (unlabeled points are marked as -1)
199 All unlabeled samples will be transductively assigned labels
200
201 Returns
202 -------
203 self : returns an instance of self.
204 """
205 1 18 18.0 0.0 if sparse.isspmatrix(X):
206 self.X_ = X
207 else:
208 1 8 8.0 0.0 self.X_ = np.asarray(X)
209
210 # actual graph construction (implementations should override this)
211 1 360556 360556.0 99.0 graph_matrix = self._build_graph()
212
213 # label construction
214 # construct a categorical distribution for classification only
215 1 51 51.0 0.0 classes = np.unique(y)
216 1 24 24.0 0.0 classes = (classes[classes != -1])
217 1 2 2.0 0.0 self.classes_ = classes
218
219 1 3 3.0 0.0 n_samples, n_classes = len(y), len(classes)
220
221 1 8 8.0 0.0 y = np.asarray(y)
222 1 9 9.0 0.0 unlabeled = y == -1
223 1 10 10.0 0.0 clamp_weights = np.ones((n_samples, 1))
224 1 18 18.0 0.0 clamp_weights[unlabeled, 0] = self.alpha
225
226 # initialize distributions
227 1 6 6.0 0.0 self.label_distributions_ = np.zeros((n_samples, n_classes))
228 2 7 3.5 0.0 for label in classes:
229 1 20 20.0 0.0 self.label_distributions_[y == label, classes == label] = 1
230
231 1 8 8.0 0.0 y_static = np.copy(self.label_distributions_)
232 1 2 2.0 0.0 if self.alpha > 0.:
233 1 10 10.0 0.0 y_static *= 1 - self.alpha
234 1 18 18.0 0.0 y_static[unlabeled] = 0
235
236 1 5 5.0 0.0 l_previous = np.zeros((self.X_.shape[0], n_classes))
237
238 1 2 2.0 0.0 remaining_iter = self.max_iters
239 1 14 14.0 0.0 if sparse.isspmatrix(graph_matrix):
240 1 383 383.0 0.1 graph_matrix = graph_matrix.tocsr()
241 16 329 20.6 0.1 while (_not_converged(self.label_distributions_, l_previous, self.tol)
242 15 28 1.9 0.0 and remaining_iter > 1):
243 15 29 1.9 0.0 l_previous = self.label_distributions_
244 15 23 1.5 0.0 self.label_distributions_ = safe_sparse_dot(graph_matrix,
245 15 2201 146.7 0.6 self.label_distributions_)
246 # clamp
247 15 33 2.2 0.0 self.label_distributions_ = np.multiply(clamp_weights,
248 15 175 11.7 0.0 self.label_distributions_) + y_static
249 15 28 1.9 0.0 remaining_iter -= 1
250
251 1 22 22.0 0.0 normalizer = np.sum(self.label_distributions_, axis=1)[:, np.newaxis]
252 1 13 13.0 0.0 self.label_distributions_ /= normalizer
253 # set the transduction item
254 1 2 2.0 0.0 transduction = self.classes_[np.argmax(self.label_distributions_,
255 1 15 15.0 0.0 axis=1)]
256 1 4 4.0 0.0 self.transduction_ = transduction.ravel()
257 1 1 1.0 0.0 return self
LabelSpreading-knn-madelon-semi¶
Benchmark setup
from sklearn.semi_supervised import LabelSpreading from deps import load_data kwargs = {'kernel': 'knn'} X, y, X_t, y_t = load_data('madelon-semi') obj = LabelSpreading(**kwargs)
Benchmark statement
obj.fit(X, y)
Execution time
Memory usage
Additional output
cProfile
1423 function calls (1422 primitive calls) in 7.753 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 7.753 7.753 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 7.753 7.753 <f>:1(<module>)
1 0.002 0.002 7.753 7.753 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:185(fit)
1 0.000 0.000 7.744 7.744 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:377(_build_graph)
1 0.000 0.000 7.740 7.740 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:112(_get_kernel)
1 0.000 0.000 7.585 7.585 /tmp/vb_sklearn/sklearn/neighbors/base.py:261(kneighbors_graph)
1 0.000 0.000 7.585 7.585 /tmp/vb_sklearn/sklearn/neighbors/base.py:156(kneighbors)
1 7.582 7.582 7.582 7.582 {method 'query' of 'sklearn.neighbors.ball_tree.BallTree' objects}
1 0.000 0.000 0.154 0.154 /tmp/vb_sklearn/sklearn/neighbors/base.py:578(fit)
1 0.152 0.152 0.154 0.154 /tmp/vb_sklearn/sklearn/neighbors/base.py:96(_fit)
22 0.006 0.000 0.006 0.000 {method 'sum' of 'numpy.ndarray' objects}
2 0.000 0.000 0.005 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
17 0.000 0.000 0.005 0.000 /tmp/vb_sklearn/sklearn/utils/extmath.py:70(safe_sparse_dot)
18 0.000 0.000 0.005 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:229(__mul__)
1 0.000 0.000 0.004 0.004 /tmp/vb_sklearn/sklearn/utils/graph.py:132(graph_laplacian)
1 0.002 0.002 0.003 0.003 /tmp/vb_sklearn/sklearn/utils/graph.py:78(_graph_laplacian_sparse)
1 0.000 0.000 0.003 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
1 0.000 0.000 0.003 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:23(safe_asarray)
17 0.000 0.000 0.003 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:250(_mul_vector)
1 0.000 0.000 0.002 0.002 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/coo.py:281(tocsr)
19 0.001 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:18(upcast)
17 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/csr.py:287(csr_matvec)
17 0.001 0.000 0.001 0.000 {_csr.csr_matvec}
2 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/data.py:35(__neg__)
114 0.001 0.000 0.001 0.000 {numpy.core.multiarray.array}
3 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:20(__init__)
18 0.001 0.000 0.001 0.000 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:70(_not_converged)
2 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/coo.py:115(__init__)
65 0.001 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
1 0.000 0.000 0.001 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:567(sum_duplicates)
47 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
1 0.000 0.000 0.001 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:613(sort_indices)
2 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/coo.py:205(_check)
1 0.000 0.000 0.001 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:486(sum)
1 0.000 0.000 0.001 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:526(tocoo)
1 0.000 0.000 0.001 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/csr.py:529(csr_sort_indices)
1 0.001 0.001 0.001 0.001 {_csr.csr_sort_indices}
3 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:101(check_format)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/coo.py:354(_with_data)
18 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:77(isscalarlike)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:643(_with_data)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/coo.py:370(_mul_vector)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/coo.py:75(coo_tocsr)
1 0.000 0.000 0.000 0.000 {_coo.coo_tocsr}
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:622(prune)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/neighbors/base.py:27(warn_equidistant)
18 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:124(isdense)
1 0.000 0.000 0.000 0.000 {_warnings.warn}
41 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
130 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
4 0.000 0.000 0.000 0.000 {method 'max' of 'numpy.ndarray' objects}
4 0.000 0.000 0.000 0.000 {method 'min' of 'numpy.ndarray' objects}
190 0.000 0.000 0.000 0.000 {numpy.core.multiarray.can_cast}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
122 0.000 0.000 0.000 0.000 {isinstance}
20 0.000 0.000 0.000 0.000 {numpy.core.multiarray.zeros}
6 0.000 0.000 0.000 0.000 {method 'copy' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/warnings.py:24(_show_warning)
18 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1044(ravel)
3 0.000 0.000 0.000 0.000 {method 'astype' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/matrixlib/defmatrix.py:55(asmatrix)
3 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/coo.py:174(coo_matvec)
20 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
1 0.000 0.000 0.000 0.000 {_coo.coo_matvec}
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
18 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1574(isscalar)
3 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/matrixlib/defmatrix.py:233(__new__)
1 0.000 0.000 0.000 0.000 {method 'write' of 'file' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/csr.py:70(expandptr)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
18 0.000 0.000 0.000 0.000 {method 'reshape' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/csr.py:567(csr_sum_duplicates)
7 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/coo.py:194(getnnz)
1 0.000 0.000 0.000 0.000 {method 'sort' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/warnings.py:36(formatwarning)
1 0.000 0.000 0.000 0.000 {_csr.expandptr}
5 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:96(isshape)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
1 0.000 0.000 0.000 0.000 {_csr.csr_sum_duplicates}
5 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/data.py:17(__init__)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numerictypes.py:733(issubdtype)
5 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:50(to_native)
2 0.000 0.000 0.000 0.000 {method 'view' of 'numpy.ndarray' objects}
7 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:683(argmax)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:581(__get_sorted)
21 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
73 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:81(get_shape)
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
5 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:59(set_shape)
4/3 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/matrixlib/defmatrix.py:279(__array_finalize__)
5 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:51(__init__)
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.concatenate}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/neighbors/unsupervised.py:85(__init__)
71 0.000 0.000 0.000 0.000 {len}
22 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/data.py:20(_get_dtype)
1 0.000 0.000 0.000 0.000 {hasattr}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:81(isintlike)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/linecache.py:13(getline)
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.arange}
17 0.000 0.000 0.000 0.000 {getattr}
30 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:2116(rank)
16 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:85(getnnz)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/neighbors/base.py:77(_init_params)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:781(copy)
1 0.000 0.000 0.000 0.000 {method 'mro' of 'type' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:111(issequence)
13 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/csr.py:180(_swap)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numerictypes.py:665(issubclass_)
5 0.000 0.000 0.000 0.000 {method 'newbyteorder' of 'numpy.dtype' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:370(__getattr__)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/csr.py:85(csr_has_sorted_indices)
3 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:54(getdtype)
1 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/linecache.py:33(getlines)
4 0.000 0.000 0.000 0.000 {issubclass}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:597(__set_sorted)
1 0.000 0.000 0.000 0.000 {_csr.csr_has_sorted_indices}
1 0.000 0.000 0.000 0.000 {method 'squeeze' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'strip' of 'str' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: predict at line 135
Total time: 0 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
135 def predict(self, X):
136 """Performs inductive inference across the model.
137
138 Parameters
139 ----------
140 X : array_like, shape = [n_samples, n_features]
141
142 Returns
143 -------
144 y : array_like, shape = [n_samples]
145 Predictions for input data
146 """
147 probas = self.predict_proba(X)
148 return self.classes_[np.argmax(probas, axis=1)].ravel()
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: fit at line 185
Total time: 7.81785 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
185 def fit(self, X, y):
186 """Fit a semi-supervised label propagation model based
187
188 All the input data is provided matrix X (labeled and unlabeled)
189 and corresponding label matrix y with a dedicated marker value for
190 unlabeled samples.
191
192 Parameters
193 ----------
194 X : array-like, shape = [n_samples, n_features]
195 A {n_samples by n_samples} size matrix will be created from this
196
197 y : array_like, shape = [n_samples]
198 n_labeled_samples (unlabeled points are marked as -1)
199 All unlabeled samples will be transductively assigned labels
200
201 Returns
202 -------
203 self : returns an instance of self.
204 """
205 1 30 30.0 0.0 if sparse.isspmatrix(X):
206 self.X_ = X
207 else:
208 1 14 14.0 0.0 self.X_ = np.asarray(X)
209
210 # actual graph construction (implementations should override this)
211 1 7807644 7807644.0 99.9 graph_matrix = self._build_graph()
212
213 # label construction
214 # construct a categorical distribution for classification only
215 1 175 175.0 0.0 classes = np.unique(y)
216 1 21 21.0 0.0 classes = (classes[classes != -1])
217 1 4 4.0 0.0 self.classes_ = classes
218
219 1 5 5.0 0.0 n_samples, n_classes = len(y), len(classes)
220
221 1 12 12.0 0.0 y = np.asarray(y)
222 1 19 19.0 0.0 unlabeled = y == -1
223 1 20 20.0 0.0 clamp_weights = np.ones((n_samples, 1))
224 1 235 235.0 0.0 clamp_weights[unlabeled, 0] = self.alpha
225
226 # initialize distributions
227 1 11 11.0 0.0 self.label_distributions_ = np.zeros((n_samples, n_classes))
228 2 12 6.0 0.0 for label in classes:
229 1 136 136.0 0.0 self.label_distributions_[y == label, classes == label] = 1
230
231 1 17 17.0 0.0 y_static = np.copy(self.label_distributions_)
232 1 4 4.0 0.0 if self.alpha > 0.:
233 1 22 22.0 0.0 y_static *= 1 - self.alpha
234 1 293 293.0 0.0 y_static[unlabeled] = 0
235
236 1 11 11.0 0.0 l_previous = np.zeros((self.X_.shape[0], n_classes))
237
238 1 3 3.0 0.0 remaining_iter = self.max_iters
239 1 24 24.0 0.0 if sparse.isspmatrix(graph_matrix):
240 1 1508 1508.0 0.0 graph_matrix = graph_matrix.tocsr()
241 18 1073 59.6 0.0 while (_not_converged(self.label_distributions_, l_previous, self.tol)
242 17 61 3.6 0.0 and remaining_iter > 1):
243 17 61 3.6 0.0 l_previous = self.label_distributions_
244 17 49 2.9 0.0 self.label_distributions_ = safe_sparse_dot(graph_matrix,
245 17 5421 318.9 0.1 self.label_distributions_)
246 # clamp
247 17 72 4.2 0.0 self.label_distributions_ = np.multiply(clamp_weights,
248 17 591 34.8 0.0 self.label_distributions_) + y_static
249 17 58 3.4 0.0 remaining_iter -= 1
250
251 1 80 80.0 0.0 normalizer = np.sum(self.label_distributions_, axis=1)[:, np.newaxis]
252 1 58 58.0 0.0 self.label_distributions_ /= normalizer
253 # set the transduction item
254 1 4 4.0 0.0 transduction = self.classes_[np.argmax(self.label_distributions_,
255 1 91 91.0 0.0 axis=1)]
256 1 6 6.0 0.0 self.transduction_ = transduction.ravel()
257 1 3 3.0 0.0 return self
Benchmark statement
obj.predict(X_t)
Execution time
Memory usage
Additional output
cProfile
2481 function calls in 2.293 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 2.293 2.293 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 2.293 2.293 <f>:1(<module>)
1 0.000 0.000 2.293 2.293 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:135(predict)
1 0.008 0.008 2.293 2.293 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:150(predict_proba)
1 0.000 0.000 2.277 2.277 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:112(_get_kernel)
1 0.000 0.000 2.277 2.277 /tmp/vb_sklearn/sklearn/neighbors/base.py:156(kneighbors)
1 2.276 2.276 2.276 2.276 {method 'query' of 'sklearn.neighbors.ball_tree.BallTree' objects}
601 0.001 0.000 0.007 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
602 0.005 0.000 0.005 0.000 {method 'sum' of 'numpy.ndarray' objects}
605 0.001 0.000 0.001 0.000 {isinstance}
1 0.000 0.000 0.001 0.001 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
1 0.000 0.000 0.001 0.001 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
7 0.000 0.000 0.000 0.000 {numpy.core.multiarray.array}
604 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/neighbors/base.py:27(warn_equidistant)
1 0.000 0.000 0.000 0.000 {_warnings.warn}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/warnings.py:24(_show_warning)
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
1 0.000 0.000 0.000 0.000 {method 'write' of 'file' objects}
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/warnings.py:36(formatwarning)
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:683(argmax)
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/linecache.py:13(getline)
8 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
13 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/linecache.py:33(getlines)
1 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'strip' of 'str' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: predict at line 135
Total time: 2.29565 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
135 def predict(self, X):
136 """Performs inductive inference across the model.
137
138 Parameters
139 ----------
140 X : array_like, shape = [n_samples, n_features]
141
142 Returns
143 -------
144 y : array_like, shape = [n_samples]
145 Predictions for input data
146 """
147 1 2295605 2295605.0 100.0 probas = self.predict_proba(X)
148 1 48 48.0 0.0 return self.classes_[np.argmax(probas, axis=1)].ravel()
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: fit at line 185
Total time: 7.81785 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
185 def fit(self, X, y):
186 """Fit a semi-supervised label propagation model based
187
188 All the input data is provided matrix X (labeled and unlabeled)
189 and corresponding label matrix y with a dedicated marker value for
190 unlabeled samples.
191
192 Parameters
193 ----------
194 X : array-like, shape = [n_samples, n_features]
195 A {n_samples by n_samples} size matrix will be created from this
196
197 y : array_like, shape = [n_samples]
198 n_labeled_samples (unlabeled points are marked as -1)
199 All unlabeled samples will be transductively assigned labels
200
201 Returns
202 -------
203 self : returns an instance of self.
204 """
205 1 30 30.0 0.0 if sparse.isspmatrix(X):
206 self.X_ = X
207 else:
208 1 14 14.0 0.0 self.X_ = np.asarray(X)
209
210 # actual graph construction (implementations should override this)
211 1 7807644 7807644.0 99.9 graph_matrix = self._build_graph()
212
213 # label construction
214 # construct a categorical distribution for classification only
215 1 175 175.0 0.0 classes = np.unique(y)
216 1 21 21.0 0.0 classes = (classes[classes != -1])
217 1 4 4.0 0.0 self.classes_ = classes
218
219 1 5 5.0 0.0 n_samples, n_classes = len(y), len(classes)
220
221 1 12 12.0 0.0 y = np.asarray(y)
222 1 19 19.0 0.0 unlabeled = y == -1
223 1 20 20.0 0.0 clamp_weights = np.ones((n_samples, 1))
224 1 235 235.0 0.0 clamp_weights[unlabeled, 0] = self.alpha
225
226 # initialize distributions
227 1 11 11.0 0.0 self.label_distributions_ = np.zeros((n_samples, n_classes))
228 2 12 6.0 0.0 for label in classes:
229 1 136 136.0 0.0 self.label_distributions_[y == label, classes == label] = 1
230
231 1 17 17.0 0.0 y_static = np.copy(self.label_distributions_)
232 1 4 4.0 0.0 if self.alpha > 0.:
233 1 22 22.0 0.0 y_static *= 1 - self.alpha
234 1 293 293.0 0.0 y_static[unlabeled] = 0
235
236 1 11 11.0 0.0 l_previous = np.zeros((self.X_.shape[0], n_classes))
237
238 1 3 3.0 0.0 remaining_iter = self.max_iters
239 1 24 24.0 0.0 if sparse.isspmatrix(graph_matrix):
240 1 1508 1508.0 0.0 graph_matrix = graph_matrix.tocsr()
241 18 1073 59.6 0.0 while (_not_converged(self.label_distributions_, l_previous, self.tol)
242 17 61 3.6 0.0 and remaining_iter > 1):
243 17 61 3.6 0.0 l_previous = self.label_distributions_
244 17 49 2.9 0.0 self.label_distributions_ = safe_sparse_dot(graph_matrix,
245 17 5421 318.9 0.1 self.label_distributions_)
246 # clamp
247 17 72 4.2 0.0 self.label_distributions_ = np.multiply(clamp_weights,
248 17 591 34.8 0.0 self.label_distributions_) + y_static
249 17 58 3.4 0.0 remaining_iter -= 1
250
251 1 80 80.0 0.0 normalizer = np.sum(self.label_distributions_, axis=1)[:, np.newaxis]
252 1 58 58.0 0.0 self.label_distributions_ /= normalizer
253 # set the transduction item
254 1 4 4.0 0.0 transduction = self.classes_[np.argmax(self.label_distributions_,
255 1 91 91.0 0.0 axis=1)]
256 1 6 6.0 0.0 self.transduction_ = transduction.ravel()
257 1 3 3.0 0.0 return self
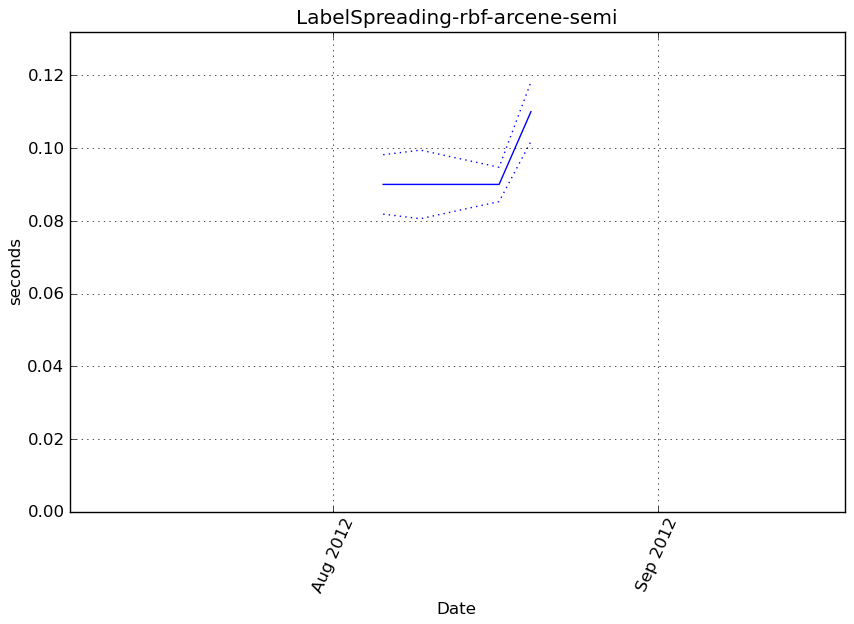
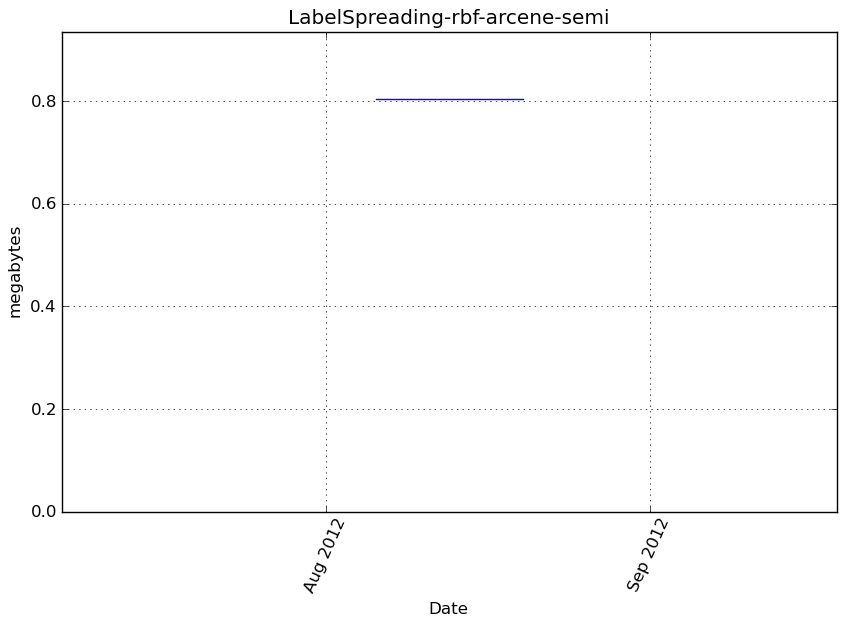
LabelSpreading-rbf-arcene-semi¶
Benchmark setup
from sklearn.semi_supervised import LabelSpreading from deps import load_data kwargs = {'kernel': 'rbf'} X, y, X_t, y_t = load_data('arcene-semi') obj = LabelSpreading(**kwargs)
Benchmark statement
obj.fit(X, y)
Execution time
Memory usage
Additional output
cProfile
187 function calls in 0.106 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.106 0.106 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 0.106 0.106 <f>:1(<module>)
1 0.000 0.000 0.106 0.106 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:185(fit)
1 0.000 0.000 0.105 0.105 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:377(_build_graph)
1 0.000 0.000 0.105 0.105 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:112(_get_kernel)
1 0.001 0.001 0.105 0.105 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:325(rbf_kernel)
1 0.007 0.007 0.098 0.098 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:101(euclidean_distances)
3 0.000 0.000 0.083 0.028 /tmp/vb_sklearn/sklearn/utils/extmath.py:70(safe_sparse_dot)
3 0.083 0.028 0.083 0.028 {numpy.core._dotblas.dot}
10 0.013 0.001 0.013 0.001 {method 'sum' of 'numpy.ndarray' objects}
2 0.000 0.000 0.011 0.006 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:52(check_pairwise_arrays)
4 0.000 0.000 0.011 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
2 0.000 0.000 0.006 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
2 0.000 0.000 0.005 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:23(safe_asarray)
2 0.000 0.000 0.003 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
1 0.000 0.000 0.001 0.001 /tmp/vb_sklearn/sklearn/utils/graph.py:132(graph_laplacian)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/graph.py:113(_graph_laplacian_dense)
17 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
17 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
3 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:70(_not_converged)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numerictypes.py:733(issubdtype)
34 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.concatenate}
19 0.000 0.000 0.000 0.000 {isinstance}
6 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
9 0.000 0.000 0.000 0.000 {numpy.core.multiarray.array}
1 0.000 0.000 0.000 0.000 {method 'copy' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
1 0.000 0.000 0.000 0.000 {method 'mro' of 'type' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:683(argmax)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numerictypes.py:665(issubclass_)
13 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:781(copy)
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
4 0.000 0.000 0.000 0.000 {issubclass}
2 0.000 0.000 0.000 0.000 {numpy.core.multiarray.zeros}
1 0.000 0.000 0.000 0.000 {method 'sort' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
1 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: predict at line 135
Total time: 0 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
135 def predict(self, X):
136 """Performs inductive inference across the model.
137
138 Parameters
139 ----------
140 X : array_like, shape = [n_samples, n_features]
141
142 Returns
143 -------
144 y : array_like, shape = [n_samples]
145 Predictions for input data
146 """
147 probas = self.predict_proba(X)
148 return self.classes_[np.argmax(probas, axis=1)].ravel()
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: fit at line 185
Total time: 0.098473 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
185 def fit(self, X, y):
186 """Fit a semi-supervised label propagation model based
187
188 All the input data is provided matrix X (labeled and unlabeled)
189 and corresponding label matrix y with a dedicated marker value for
190 unlabeled samples.
191
192 Parameters
193 ----------
194 X : array-like, shape = [n_samples, n_features]
195 A {n_samples by n_samples} size matrix will be created from this
196
197 y : array_like, shape = [n_samples]
198 n_labeled_samples (unlabeled points are marked as -1)
199 All unlabeled samples will be transductively assigned labels
200
201 Returns
202 -------
203 self : returns an instance of self.
204 """
205 1 29 29.0 0.0 if sparse.isspmatrix(X):
206 self.X_ = X
207 else:
208 1 13 13.0 0.0 self.X_ = np.asarray(X)
209
210 # actual graph construction (implementations should override this)
211 1 97609 97609.0 99.1 graph_matrix = self._build_graph()
212
213 # label construction
214 # construct a categorical distribution for classification only
215 1 95 95.0 0.1 classes = np.unique(y)
216 1 21 21.0 0.0 classes = (classes[classes != -1])
217 1 4 4.0 0.0 self.classes_ = classes
218
219 1 5 5.0 0.0 n_samples, n_classes = len(y), len(classes)
220
221 1 14 14.0 0.0 y = np.asarray(y)
222 1 14 14.0 0.0 unlabeled = y == -1
223 1 20 20.0 0.0 clamp_weights = np.ones((n_samples, 1))
224 1 29 29.0 0.0 clamp_weights[unlabeled, 0] = self.alpha
225
226 # initialize distributions
227 1 8 8.0 0.0 self.label_distributions_ = np.zeros((n_samples, n_classes))
228 2 13 6.5 0.0 for label in classes:
229 1 45 45.0 0.0 self.label_distributions_[y == label, classes == label] = 1
230
231 1 15 15.0 0.0 y_static = np.copy(self.label_distributions_)
232 1 4 4.0 0.0 if self.alpha > 0.:
233 1 16 16.0 0.0 y_static *= 1 - self.alpha
234 1 30 30.0 0.0 y_static[unlabeled] = 0
235
236 1 9 9.0 0.0 l_previous = np.zeros((self.X_.shape[0], n_classes))
237
238 1 3 3.0 0.0 remaining_iter = self.max_iters
239 1 24 24.0 0.0 if sparse.isspmatrix(graph_matrix):
240 graph_matrix = graph_matrix.tocsr()
241 3 116 38.7 0.1 while (_not_converged(self.label_distributions_, l_previous, self.tol)
242 2 8 4.0 0.0 and remaining_iter > 1):
243 2 7 3.5 0.0 l_previous = self.label_distributions_
244 2 6 3.0 0.0 self.label_distributions_ = safe_sparse_dot(graph_matrix,
245 2 152 76.0 0.2 self.label_distributions_)
246 # clamp
247 2 7 3.5 0.0 self.label_distributions_ = np.multiply(clamp_weights,
248 2 41 20.5 0.0 self.label_distributions_) + y_static
249 2 7 3.5 0.0 remaining_iter -= 1
250
251 1 34 34.0 0.0 normalizer = np.sum(self.label_distributions_, axis=1)[:, np.newaxis]
252 1 37 37.0 0.0 self.label_distributions_ /= normalizer
253 # set the transduction item
254 1 4 4.0 0.0 transduction = self.classes_[np.argmax(self.label_distributions_,
255 1 26 26.0 0.0 axis=1)]
256 1 6 6.0 0.0 self.transduction_ = transduction.ravel()
257 1 2 2.0 0.0 return self
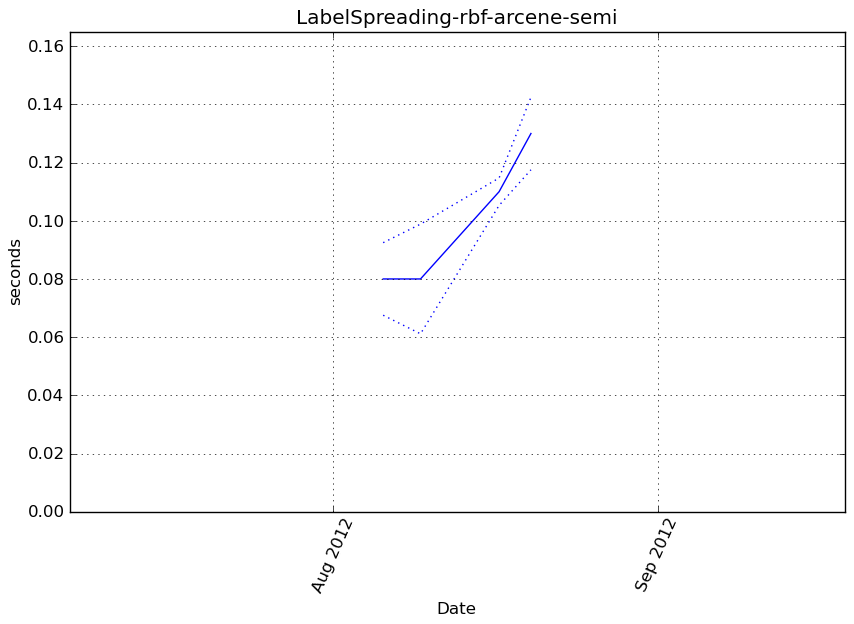
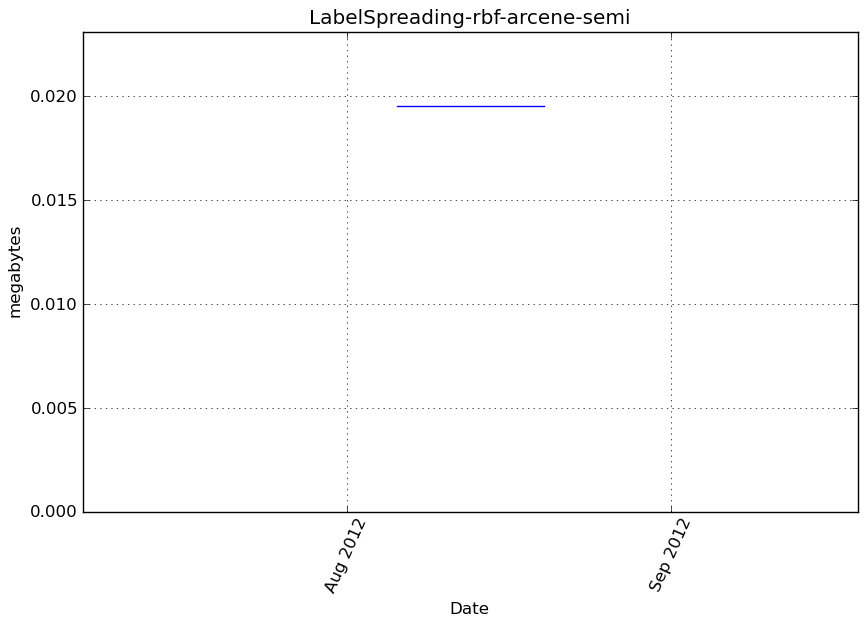
Benchmark statement
obj.predict(X_t)
Execution time
Memory usage
Additional output
cProfile
200 function calls in 0.120 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.120 0.120 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 0.119 0.119 <f>:1(<module>)
1 0.000 0.000 0.119 0.119 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:135(predict)
1 0.000 0.000 0.119 0.119 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:150(predict_proba)
1 0.000 0.000 0.114 0.114 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:112(_get_kernel)
1 0.001 0.001 0.114 0.114 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:325(rbf_kernel)
1 0.006 0.006 0.103 0.103 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:101(euclidean_distances)
2 0.084 0.042 0.084 0.042 {numpy.core._dotblas.dot}
1 0.000 0.000 0.079 0.079 /tmp/vb_sklearn/sklearn/utils/extmath.py:70(safe_sparse_dot)
11 0.027 0.002 0.027 0.002 {method 'sum' of 'numpy.ndarray' objects}
2 0.000 0.000 0.023 0.011 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:52(check_pairwise_arrays)
8 0.000 0.000 0.022 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
4 0.000 0.000 0.011 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
4 0.000 0.000 0.011 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:23(safe_asarray)
3 0.000 0.000 0.006 0.002 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
17 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
17 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
4 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
6 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
34 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
20 0.000 0.000 0.000 0.000 {isinstance}
14 0.000 0.000 0.000 0.000 {numpy.core.multiarray.array}
6 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
8 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
22 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:683(argmax)
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
6 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: predict at line 135
Total time: 0.119211 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
135 def predict(self, X):
136 """Performs inductive inference across the model.
137
138 Parameters
139 ----------
140 X : array_like, shape = [n_samples, n_features]
141
142 Returns
143 -------
144 y : array_like, shape = [n_samples]
145 Predictions for input data
146 """
147 1 119181 119181.0 100.0 probas = self.predict_proba(X)
148 1 30 30.0 0.0 return self.classes_[np.argmax(probas, axis=1)].ravel()
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: fit at line 185
Total time: 0.098473 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
185 def fit(self, X, y):
186 """Fit a semi-supervised label propagation model based
187
188 All the input data is provided matrix X (labeled and unlabeled)
189 and corresponding label matrix y with a dedicated marker value for
190 unlabeled samples.
191
192 Parameters
193 ----------
194 X : array-like, shape = [n_samples, n_features]
195 A {n_samples by n_samples} size matrix will be created from this
196
197 y : array_like, shape = [n_samples]
198 n_labeled_samples (unlabeled points are marked as -1)
199 All unlabeled samples will be transductively assigned labels
200
201 Returns
202 -------
203 self : returns an instance of self.
204 """
205 1 29 29.0 0.0 if sparse.isspmatrix(X):
206 self.X_ = X
207 else:
208 1 13 13.0 0.0 self.X_ = np.asarray(X)
209
210 # actual graph construction (implementations should override this)
211 1 97609 97609.0 99.1 graph_matrix = self._build_graph()
212
213 # label construction
214 # construct a categorical distribution for classification only
215 1 95 95.0 0.1 classes = np.unique(y)
216 1 21 21.0 0.0 classes = (classes[classes != -1])
217 1 4 4.0 0.0 self.classes_ = classes
218
219 1 5 5.0 0.0 n_samples, n_classes = len(y), len(classes)
220
221 1 14 14.0 0.0 y = np.asarray(y)
222 1 14 14.0 0.0 unlabeled = y == -1
223 1 20 20.0 0.0 clamp_weights = np.ones((n_samples, 1))
224 1 29 29.0 0.0 clamp_weights[unlabeled, 0] = self.alpha
225
226 # initialize distributions
227 1 8 8.0 0.0 self.label_distributions_ = np.zeros((n_samples, n_classes))
228 2 13 6.5 0.0 for label in classes:
229 1 45 45.0 0.0 self.label_distributions_[y == label, classes == label] = 1
230
231 1 15 15.0 0.0 y_static = np.copy(self.label_distributions_)
232 1 4 4.0 0.0 if self.alpha > 0.:
233 1 16 16.0 0.0 y_static *= 1 - self.alpha
234 1 30 30.0 0.0 y_static[unlabeled] = 0
235
236 1 9 9.0 0.0 l_previous = np.zeros((self.X_.shape[0], n_classes))
237
238 1 3 3.0 0.0 remaining_iter = self.max_iters
239 1 24 24.0 0.0 if sparse.isspmatrix(graph_matrix):
240 graph_matrix = graph_matrix.tocsr()
241 3 116 38.7 0.1 while (_not_converged(self.label_distributions_, l_previous, self.tol)
242 2 8 4.0 0.0 and remaining_iter > 1):
243 2 7 3.5 0.0 l_previous = self.label_distributions_
244 2 6 3.0 0.0 self.label_distributions_ = safe_sparse_dot(graph_matrix,
245 2 152 76.0 0.2 self.label_distributions_)
246 # clamp
247 2 7 3.5 0.0 self.label_distributions_ = np.multiply(clamp_weights,
248 2 41 20.5 0.0 self.label_distributions_) + y_static
249 2 7 3.5 0.0 remaining_iter -= 1
250
251 1 34 34.0 0.0 normalizer = np.sum(self.label_distributions_, axis=1)[:, np.newaxis]
252 1 37 37.0 0.0 self.label_distributions_ /= normalizer
253 # set the transduction item
254 1 4 4.0 0.0 transduction = self.classes_[np.argmax(self.label_distributions_,
255 1 26 26.0 0.0 axis=1)]
256 1 6 6.0 0.0 self.transduction_ = transduction.ravel()
257 1 2 2.0 0.0 return self
LabelSpreading-rbf-madelon-semi¶
Benchmark setup
from sklearn.semi_supervised import LabelSpreading from deps import load_data kwargs = {'kernel': 'rbf'} X, y, X_t, y_t = load_data('madelon-semi') obj = LabelSpreading(**kwargs)
Benchmark statement
obj.fit(X, y)
Execution time
Memory usage
Additional output
cProfile
187 function calls in 2.156 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 2.156 2.156 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.007 0.007 2.156 2.156 <f>:1(<module>)
1 0.001 0.001 2.149 2.149 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:185(fit)
1 0.012 0.012 2.131 2.131 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:377(_build_graph)
1 0.000 0.000 1.842 1.842 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:112(_get_kernel)
1 0.252 0.252 1.842 1.842 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:325(rbf_kernel)
1 0.076 0.076 1.586 1.586 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:101(euclidean_distances)
3 0.000 0.000 1.521 0.507 /tmp/vb_sklearn/sklearn/utils/extmath.py:70(safe_sparse_dot)
3 1.521 0.507 1.521 0.507 {numpy.core._dotblas.dot}
1 0.000 0.000 0.277 0.277 /tmp/vb_sklearn/sklearn/utils/graph.py:132(graph_laplacian)
1 0.096 0.096 0.277 0.277 /tmp/vb_sklearn/sklearn/utils/graph.py:113(_graph_laplacian_dense)
10 0.171 0.017 0.171 0.017 {method 'sum' of 'numpy.ndarray' objects}
1 0.018 0.018 0.018 0.018 {method 'copy' of 'numpy.ndarray' objects}
2 0.000 0.000 0.007 0.003 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:52(check_pairwise_arrays)
4 0.000 0.000 0.006 0.002 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
2 0.000 0.000 0.003 0.002 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
2 0.000 0.000 0.003 0.002 /tmp/vb_sklearn/sklearn/utils/validation.py:23(safe_asarray)
2 0.000 0.000 0.002 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
17 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
17 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
3 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:70(_not_converged)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numerictypes.py:733(issubdtype)
34 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:683(argmax)
1 0.000 0.000 0.000 0.000 {method 'sort' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.concatenate}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
19 0.000 0.000 0.000 0.000 {isinstance}
9 0.000 0.000 0.000 0.000 {numpy.core.multiarray.array}
6 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numerictypes.py:665(issubclass_)
1 0.000 0.000 0.000 0.000 {method 'mro' of 'type' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
2 0.000 0.000 0.000 0.000 {numpy.core.multiarray.zeros}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:781(copy)
4 0.000 0.000 0.000 0.000 {issubclass}
1 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
13 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
1 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: predict at line 135
Total time: 0 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
135 def predict(self, X):
136 """Performs inductive inference across the model.
137
138 Parameters
139 ----------
140 X : array_like, shape = [n_samples, n_features]
141
142 Returns
143 -------
144 y : array_like, shape = [n_samples]
145 Predictions for input data
146 """
147 probas = self.predict_proba(X)
148 return self.classes_[np.argmax(probas, axis=1)].ravel()
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: fit at line 185
Total time: 2.1928 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
185 def fit(self, X, y):
186 """Fit a semi-supervised label propagation model based
187
188 All the input data is provided matrix X (labeled and unlabeled)
189 and corresponding label matrix y with a dedicated marker value for
190 unlabeled samples.
191
192 Parameters
193 ----------
194 X : array-like, shape = [n_samples, n_features]
195 A {n_samples by n_samples} size matrix will be created from this
196
197 y : array_like, shape = [n_samples]
198 n_labeled_samples (unlabeled points are marked as -1)
199 All unlabeled samples will be transductively assigned labels
200
201 Returns
202 -------
203 self : returns an instance of self.
204 """
205 1 31 31.0 0.0 if sparse.isspmatrix(X):
206 self.X_ = X
207 else:
208 1 13 13.0 0.0 self.X_ = np.asarray(X)
209
210 # actual graph construction (implementations should override this)
211 1 2175277 2175277.0 99.2 graph_matrix = self._build_graph()
212
213 # label construction
214 # construct a categorical distribution for classification only
215 1 221 221.0 0.0 classes = np.unique(y)
216 1 24 24.0 0.0 classes = (classes[classes != -1])
217 1 4 4.0 0.0 self.classes_ = classes
218
219 1 4 4.0 0.0 n_samples, n_classes = len(y), len(classes)
220
221 1 15 15.0 0.0 y = np.asarray(y)
222 1 20 20.0 0.0 unlabeled = y == -1
223 1 25 25.0 0.0 clamp_weights = np.ones((n_samples, 1))
224 1 235 235.0 0.0 clamp_weights[unlabeled, 0] = self.alpha
225
226 # initialize distributions
227 1 10 10.0 0.0 self.label_distributions_ = np.zeros((n_samples, n_classes))
228 2 14 7.0 0.0 for label in classes:
229 1 138 138.0 0.0 self.label_distributions_[y == label, classes == label] = 1
230
231 1 19 19.0 0.0 y_static = np.copy(self.label_distributions_)
232 1 4 4.0 0.0 if self.alpha > 0.:
233 1 24 24.0 0.0 y_static *= 1 - self.alpha
234 1 294 294.0 0.0 y_static[unlabeled] = 0
235
236 1 11 11.0 0.0 l_previous = np.zeros((self.X_.shape[0], n_classes))
237
238 1 3 3.0 0.0 remaining_iter = self.max_iters
239 1 26 26.0 0.0 if sparse.isspmatrix(graph_matrix):
240 graph_matrix = graph_matrix.tocsr()
241 3 236 78.7 0.0 while (_not_converged(self.label_distributions_, l_previous, self.tol)
242 2 8 4.0 0.0 and remaining_iter > 1):
243 2 8 4.0 0.0 l_previous = self.label_distributions_
244 2 7 3.5 0.0 self.label_distributions_ = safe_sparse_dot(graph_matrix,
245 2 15685 7842.5 0.7 self.label_distributions_)
246 # clamp
247 2 17 8.5 0.0 self.label_distributions_ = np.multiply(clamp_weights,
248 2 115 57.5 0.0 self.label_distributions_) + y_static
249 2 6 3.0 0.0 remaining_iter -= 1
250
251 1 104 104.0 0.0 normalizer = np.sum(self.label_distributions_, axis=1)[:, np.newaxis]
252 1 78 78.0 0.0 self.label_distributions_ /= normalizer
253 # set the transduction item
254 1 5 5.0 0.0 transduction = self.classes_[np.argmax(self.label_distributions_,
255 1 111 111.0 0.0 axis=1)]
256 1 8 8.0 0.0 self.transduction_ = transduction.ravel()
257 1 2 2.0 0.0 return self
Benchmark statement
obj.predict(X_t)
Execution time
Memory usage
Additional output
cProfile
200 function calls in 1.268 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 1.268 1.268 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 1.268 1.268 <f>:1(<module>)
1 0.000 0.000 1.268 1.268 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:135(predict)
1 0.000 0.000 1.268 1.268 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:150(predict_proba)
2 1.150 0.575 1.150 0.575 {numpy.core._dotblas.dot}
1 0.000 0.000 0.573 0.573 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:112(_get_kernel)
1 0.075 0.075 0.573 0.573 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:325(rbf_kernel)
1 0.025 0.025 0.491 0.491 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:101(euclidean_distances)
1 0.000 0.000 0.455 0.455 /tmp/vb_sklearn/sklearn/utils/extmath.py:70(safe_sparse_dot)
11 0.018 0.002 0.018 0.002 {method 'sum' of 'numpy.ndarray' objects}
2 0.000 0.000 0.015 0.007 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:52(check_pairwise_arrays)
8 0.000 0.000 0.014 0.002 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
4 0.000 0.000 0.007 0.002 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
4 0.000 0.000 0.007 0.002 /tmp/vb_sklearn/sklearn/utils/validation.py:23(safe_asarray)
3 0.000 0.000 0.004 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
17 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
17 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
4 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
6 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
20 0.000 0.000 0.000 0.000 {isinstance}
34 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
6 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
14 0.000 0.000 0.000 0.000 {numpy.core.multiarray.array}
8 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:683(argmax)
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
22 0.000 0.000 0.000 0.000 {len}
6 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: predict at line 135
Total time: 1.28236 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
135 def predict(self, X):
136 """Performs inductive inference across the model.
137
138 Parameters
139 ----------
140 X : array_like, shape = [n_samples, n_features]
141
142 Returns
143 -------
144 y : array_like, shape = [n_samples]
145 Predictions for input data
146 """
147 1 1282312 1282312.0 100.0 probas = self.predict_proba(X)
148 1 50 50.0 0.0 return self.classes_[np.argmax(probas, axis=1)].ravel()
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: fit at line 185
Total time: 2.1928 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
185 def fit(self, X, y):
186 """Fit a semi-supervised label propagation model based
187
188 All the input data is provided matrix X (labeled and unlabeled)
189 and corresponding label matrix y with a dedicated marker value for
190 unlabeled samples.
191
192 Parameters
193 ----------
194 X : array-like, shape = [n_samples, n_features]
195 A {n_samples by n_samples} size matrix will be created from this
196
197 y : array_like, shape = [n_samples]
198 n_labeled_samples (unlabeled points are marked as -1)
199 All unlabeled samples will be transductively assigned labels
200
201 Returns
202 -------
203 self : returns an instance of self.
204 """
205 1 31 31.0 0.0 if sparse.isspmatrix(X):
206 self.X_ = X
207 else:
208 1 13 13.0 0.0 self.X_ = np.asarray(X)
209
210 # actual graph construction (implementations should override this)
211 1 2175277 2175277.0 99.2 graph_matrix = self._build_graph()
212
213 # label construction
214 # construct a categorical distribution for classification only
215 1 221 221.0 0.0 classes = np.unique(y)
216 1 24 24.0 0.0 classes = (classes[classes != -1])
217 1 4 4.0 0.0 self.classes_ = classes
218
219 1 4 4.0 0.0 n_samples, n_classes = len(y), len(classes)
220
221 1 15 15.0 0.0 y = np.asarray(y)
222 1 20 20.0 0.0 unlabeled = y == -1
223 1 25 25.0 0.0 clamp_weights = np.ones((n_samples, 1))
224 1 235 235.0 0.0 clamp_weights[unlabeled, 0] = self.alpha
225
226 # initialize distributions
227 1 10 10.0 0.0 self.label_distributions_ = np.zeros((n_samples, n_classes))
228 2 14 7.0 0.0 for label in classes:
229 1 138 138.0 0.0 self.label_distributions_[y == label, classes == label] = 1
230
231 1 19 19.0 0.0 y_static = np.copy(self.label_distributions_)
232 1 4 4.0 0.0 if self.alpha > 0.:
233 1 24 24.0 0.0 y_static *= 1 - self.alpha
234 1 294 294.0 0.0 y_static[unlabeled] = 0
235
236 1 11 11.0 0.0 l_previous = np.zeros((self.X_.shape[0], n_classes))
237
238 1 3 3.0 0.0 remaining_iter = self.max_iters
239 1 26 26.0 0.0 if sparse.isspmatrix(graph_matrix):
240 graph_matrix = graph_matrix.tocsr()
241 3 236 78.7 0.0 while (_not_converged(self.label_distributions_, l_previous, self.tol)
242 2 8 4.0 0.0 and remaining_iter > 1):
243 2 8 4.0 0.0 l_previous = self.label_distributions_
244 2 7 3.5 0.0 self.label_distributions_ = safe_sparse_dot(graph_matrix,
245 2 15685 7842.5 0.7 self.label_distributions_)
246 # clamp
247 2 17 8.5 0.0 self.label_distributions_ = np.multiply(clamp_weights,
248 2 115 57.5 0.0 self.label_distributions_) + y_static
249 2 6 3.0 0.0 remaining_iter -= 1
250
251 1 104 104.0 0.0 normalizer = np.sum(self.label_distributions_, axis=1)[:, np.newaxis]
252 1 78 78.0 0.0 self.label_distributions_ /= normalizer
253 # set the transduction item
254 1 5 5.0 0.0 transduction = self.classes_[np.argmax(self.label_distributions_,
255 1 111 111.0 0.0 axis=1)]
256 1 8 8.0 0.0 self.transduction_ = transduction.ravel()
257 1 2 2.0 0.0 return self
LabelPropagation-knn-arcene-semi¶
Benchmark setup
from sklearn.semi_supervised import LabelPropagation from deps import load_data kwargs = {'kernel': 'knn'} X, y, X_t, y_t = load_data('arcene-semi') obj = LabelPropagation(**kwargs)
Benchmark statement
obj.fit(X, y)
Execution time
Memory usage
Additional output
cProfile
1143 function calls (1142 primitive calls) in 0.317 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.317 0.317 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 0.317 0.317 <f>:1(<module>)
1 0.001 0.001 0.317 0.317 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:185(fit)
1 0.000 0.000 0.312 0.312 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:304(_build_graph)
1 0.000 0.000 0.311 0.311 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:112(_get_kernel)
1 0.000 0.000 0.283 0.283 /tmp/vb_sklearn/sklearn/neighbors/base.py:261(kneighbors_graph)
1 0.000 0.000 0.283 0.283 /tmp/vb_sklearn/sklearn/neighbors/base.py:156(kneighbors)
1 0.280 0.280 0.280 0.280 {method 'query' of 'sklearn.neighbors.ball_tree.BallTree' objects}
1 0.000 0.000 0.027 0.027 /tmp/vb_sklearn/sklearn/neighbors/base.py:578(fit)
1 0.025 0.025 0.027 0.027 /tmp/vb_sklearn/sklearn/neighbors/base.py:96(_fit)
20 0.006 0.000 0.006 0.000 {method 'sum' of 'numpy.ndarray' objects}
2 0.000 0.000 0.005 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
16 0.000 0.000 0.003 0.000 /tmp/vb_sklearn/sklearn/utils/extmath.py:70(safe_sparse_dot)
17 0.000 0.000 0.003 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:229(__mul__)
1 0.000 0.000 0.003 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:23(safe_asarray)
1 0.000 0.000 0.003 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
17 0.000 0.000 0.002 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:250(_mul_vector)
17 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:18(upcast)
1 0.000 0.000 0.001 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:310(sum)
1 0.000 0.000 0.001 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:486(sum)
92 0.001 0.000 0.001 0.000 {numpy.core.multiarray.array}
1 0.000 0.000 0.001 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:302(__rmul__)
61 0.001 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
43 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
2 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:20(__init__)
17 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:70(_not_converged)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:101(check_format)
18 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:77(isscalarlike)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/csr.py:107(transpose)
18 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:124(isdense)
16 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/csr.py:287(csr_matvec)
114 0.000 0.000 0.000 0.000 {isinstance}
122 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
17 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1044(ravel)
31 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
170 0.000 0.000 0.000 0.000 {numpy.core.multiarray.can_cast}
16 0.000 0.000 0.000 0.000 {_csr.csr_matvec}
19 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
19 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1574(isscalar)
19 0.000 0.000 0.000 0.000 {numpy.core.multiarray.zeros}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:622(prune)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/matrixlib/defmatrix.py:55(asmatrix)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:96(isshape)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/matrixlib/defmatrix.py:233(__new__)
3 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
17 0.000 0.000 0.000 0.000 {method 'reshape' of 'numpy.ndarray' objects}
20 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/twodim_base.py:220(diag)
2 0.000 0.000 0.000 0.000 {method 'view' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/csc.py:183(csc_matvec)
6/5 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/matrixlib/defmatrix.py:279(__array_finalize__)
57 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:81(get_shape)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/matrixlib/defmatrix.py:327(__mul__)
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.concatenate}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/data.py:17(__init__)
17 0.000 0.000 0.000 0.000 {getattr}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/neighbors/unsupervised.py:85(__init__)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:50(to_native)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:683(argmax)
3 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:51(__init__)
18 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/data.py:20(_get_dtype)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:59(set_shape)
1 0.000 0.000 0.000 0.000 {_csc.csc_matvec}
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/neighbors/base.py:77(_init_params)
3 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.arange}
1 0.000 0.000 0.000 0.000 {method 'sort' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 {method 'transpose' of 'numpy.ndarray' objects}
30 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:781(copy)
8 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:85(getnnz)
3 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/csr.py:180(_swap)
6 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:2116(rank)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:54(getdtype)
2 0.000 0.000 0.000 0.000 {method 'newbyteorder' of 'numpy.dtype' objects}
1 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
3 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/csc.py:173(_swap)
2 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/csr.py:129(tocsr)
1 0.000 0.000 0.000 0.000 {hasattr}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: predict at line 135
Total time: 0 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
135 def predict(self, X):
136 """Performs inductive inference across the model.
137
138 Parameters
139 ----------
140 X : array_like, shape = [n_samples, n_features]
141
142 Returns
143 -------
144 y : array_like, shape = [n_samples]
145 Predictions for input data
146 """
147 probas = self.predict_proba(X)
148 return self.classes_[np.argmax(probas, axis=1)].ravel()
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: fit at line 185
Total time: 0.178805 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
185 def fit(self, X, y):
186 """Fit a semi-supervised label propagation model based
187
188 All the input data is provided matrix X (labeled and unlabeled)
189 and corresponding label matrix y with a dedicated marker value for
190 unlabeled samples.
191
192 Parameters
193 ----------
194 X : array-like, shape = [n_samples, n_features]
195 A {n_samples by n_samples} size matrix will be created from this
196
197 y : array_like, shape = [n_samples]
198 n_labeled_samples (unlabeled points are marked as -1)
199 All unlabeled samples will be transductively assigned labels
200
201 Returns
202 -------
203 self : returns an instance of self.
204 """
205 1 18 18.0 0.0 if sparse.isspmatrix(X):
206 self.X_ = X
207 else:
208 1 8 8.0 0.0 self.X_ = np.asarray(X)
209
210 # actual graph construction (implementations should override this)
211 1 175479 175479.0 98.1 graph_matrix = self._build_graph()
212
213 # label construction
214 # construct a categorical distribution for classification only
215 1 52 52.0 0.0 classes = np.unique(y)
216 1 12 12.0 0.0 classes = (classes[classes != -1])
217 1 2 2.0 0.0 self.classes_ = classes
218
219 1 3 3.0 0.0 n_samples, n_classes = len(y), len(classes)
220
221 1 6 6.0 0.0 y = np.asarray(y)
222 1 8 8.0 0.0 unlabeled = y == -1
223 1 9 9.0 0.0 clamp_weights = np.ones((n_samples, 1))
224 1 18 18.0 0.0 clamp_weights[unlabeled, 0] = self.alpha
225
226 # initialize distributions
227 1 5 5.0 0.0 self.label_distributions_ = np.zeros((n_samples, n_classes))
228 2 6 3.0 0.0 for label in classes:
229 1 21 21.0 0.0 self.label_distributions_[y == label, classes == label] = 1
230
231 1 9 9.0 0.0 y_static = np.copy(self.label_distributions_)
232 1 3 3.0 0.0 if self.alpha > 0.:
233 1 10 10.0 0.0 y_static *= 1 - self.alpha
234 1 19 19.0 0.0 y_static[unlabeled] = 0
235
236 1 5 5.0 0.0 l_previous = np.zeros((self.X_.shape[0], n_classes))
237
238 1 1 1.0 0.0 remaining_iter = self.max_iters
239 1 14 14.0 0.0 if sparse.isspmatrix(graph_matrix):
240 1 4 4.0 0.0 graph_matrix = graph_matrix.tocsr()
241 17 344 20.2 0.2 while (_not_converged(self.label_distributions_, l_previous, self.tol)
242 16 30 1.9 0.0 and remaining_iter > 1):
243 16 32 2.0 0.0 l_previous = self.label_distributions_
244 16 21 1.3 0.0 self.label_distributions_ = safe_sparse_dot(graph_matrix,
245 16 2356 147.2 1.3 self.label_distributions_)
246 # clamp
247 16 39 2.4 0.0 self.label_distributions_ = np.multiply(clamp_weights,
248 16 186 11.6 0.1 self.label_distributions_) + y_static
249 16 30 1.9 0.0 remaining_iter -= 1
250
251 1 21 21.0 0.0 normalizer = np.sum(self.label_distributions_, axis=1)[:, np.newaxis]
252 1 12 12.0 0.0 self.label_distributions_ /= normalizer
253 # set the transduction item
254 1 2 2.0 0.0 transduction = self.classes_[np.argmax(self.label_distributions_,
255 1 15 15.0 0.0 axis=1)]
256 1 3 3.0 0.0 self.transduction_ = transduction.ravel()
257 1 2 2.0 0.0 return self
Benchmark statement
obj.predict(X_t)
Execution time
Memory usage
Additional output
cProfile
472 function calls in 0.264 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.264 0.264 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 0.264 0.264 <f>:1(<module>)
1 0.000 0.000 0.264 0.264 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:135(predict)
1 0.001 0.001 0.264 0.264 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:150(predict_proba)
1 0.000 0.000 0.262 0.262 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:112(_get_kernel)
1 0.000 0.000 0.262 0.262 /tmp/vb_sklearn/sklearn/neighbors/base.py:156(kneighbors)
1 0.259 0.259 0.260 0.260 {method 'query' of 'sklearn.neighbors.ball_tree.BallTree' objects}
102 0.003 0.000 0.003 0.000 {method 'sum' of 'numpy.ndarray' objects}
1 0.000 0.000 0.003 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
1 0.000 0.000 0.003 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
101 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
105 0.000 0.000 0.000 0.000 {isinstance}
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
7 0.000 0.000 0.000 0.000 {numpy.core.multiarray.array}
104 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
8 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:683(argmax)
12 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: predict at line 135
Total time: 0.318536 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
135 def predict(self, X):
136 """Performs inductive inference across the model.
137
138 Parameters
139 ----------
140 X : array_like, shape = [n_samples, n_features]
141
142 Returns
143 -------
144 y : array_like, shape = [n_samples]
145 Predictions for input data
146 """
147 1 318506 318506.0 100.0 probas = self.predict_proba(X)
148 1 30 30.0 0.0 return self.classes_[np.argmax(probas, axis=1)].ravel()
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: fit at line 185
Total time: 0.178805 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
185 def fit(self, X, y):
186 """Fit a semi-supervised label propagation model based
187
188 All the input data is provided matrix X (labeled and unlabeled)
189 and corresponding label matrix y with a dedicated marker value for
190 unlabeled samples.
191
192 Parameters
193 ----------
194 X : array-like, shape = [n_samples, n_features]
195 A {n_samples by n_samples} size matrix will be created from this
196
197 y : array_like, shape = [n_samples]
198 n_labeled_samples (unlabeled points are marked as -1)
199 All unlabeled samples will be transductively assigned labels
200
201 Returns
202 -------
203 self : returns an instance of self.
204 """
205 1 18 18.0 0.0 if sparse.isspmatrix(X):
206 self.X_ = X
207 else:
208 1 8 8.0 0.0 self.X_ = np.asarray(X)
209
210 # actual graph construction (implementations should override this)
211 1 175479 175479.0 98.1 graph_matrix = self._build_graph()
212
213 # label construction
214 # construct a categorical distribution for classification only
215 1 52 52.0 0.0 classes = np.unique(y)
216 1 12 12.0 0.0 classes = (classes[classes != -1])
217 1 2 2.0 0.0 self.classes_ = classes
218
219 1 3 3.0 0.0 n_samples, n_classes = len(y), len(classes)
220
221 1 6 6.0 0.0 y = np.asarray(y)
222 1 8 8.0 0.0 unlabeled = y == -1
223 1 9 9.0 0.0 clamp_weights = np.ones((n_samples, 1))
224 1 18 18.0 0.0 clamp_weights[unlabeled, 0] = self.alpha
225
226 # initialize distributions
227 1 5 5.0 0.0 self.label_distributions_ = np.zeros((n_samples, n_classes))
228 2 6 3.0 0.0 for label in classes:
229 1 21 21.0 0.0 self.label_distributions_[y == label, classes == label] = 1
230
231 1 9 9.0 0.0 y_static = np.copy(self.label_distributions_)
232 1 3 3.0 0.0 if self.alpha > 0.:
233 1 10 10.0 0.0 y_static *= 1 - self.alpha
234 1 19 19.0 0.0 y_static[unlabeled] = 0
235
236 1 5 5.0 0.0 l_previous = np.zeros((self.X_.shape[0], n_classes))
237
238 1 1 1.0 0.0 remaining_iter = self.max_iters
239 1 14 14.0 0.0 if sparse.isspmatrix(graph_matrix):
240 1 4 4.0 0.0 graph_matrix = graph_matrix.tocsr()
241 17 344 20.2 0.2 while (_not_converged(self.label_distributions_, l_previous, self.tol)
242 16 30 1.9 0.0 and remaining_iter > 1):
243 16 32 2.0 0.0 l_previous = self.label_distributions_
244 16 21 1.3 0.0 self.label_distributions_ = safe_sparse_dot(graph_matrix,
245 16 2356 147.2 1.3 self.label_distributions_)
246 # clamp
247 16 39 2.4 0.0 self.label_distributions_ = np.multiply(clamp_weights,
248 16 186 11.6 0.1 self.label_distributions_) + y_static
249 16 30 1.9 0.0 remaining_iter -= 1
250
251 1 21 21.0 0.0 normalizer = np.sum(self.label_distributions_, axis=1)[:, np.newaxis]
252 1 12 12.0 0.0 self.label_distributions_ /= normalizer
253 # set the transduction item
254 1 2 2.0 0.0 transduction = self.classes_[np.argmax(self.label_distributions_,
255 1 15 15.0 0.0 axis=1)]
256 1 3 3.0 0.0 self.transduction_ = transduction.ravel()
257 1 2 2.0 0.0 return self
LabelPropagation-knn-madelon-semi¶
Benchmark setup
from sklearn.semi_supervised import LabelPropagation from deps import load_data kwargs = {'kernel': 'knn'} X, y, X_t, y_t = load_data('madelon-semi') obj = LabelPropagation(**kwargs)
Benchmark statement
obj.fit(X, y)
Execution time
Memory usage
Additional output
cProfile
1828 function calls (1827 primitive calls) in 7.678 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 7.678 7.678 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 7.678 7.678 <f>:1(<module>)
1 0.002 0.002 7.678 7.678 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:185(fit)
1 0.000 0.000 7.666 7.666 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:304(_build_graph)
1 0.000 0.000 7.664 7.664 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:112(_get_kernel)
1 0.000 0.000 7.510 7.510 /tmp/vb_sklearn/sklearn/neighbors/base.py:261(kneighbors_graph)
1 0.000 0.000 7.510 7.510 /tmp/vb_sklearn/sklearn/neighbors/base.py:156(kneighbors)
1 7.506 7.506 7.506 7.506 {method 'query' of 'sklearn.neighbors.ball_tree.BallTree' objects}
1 0.000 0.000 0.154 0.154 /tmp/vb_sklearn/sklearn/neighbors/base.py:578(fit)
1 0.151 0.151 0.154 0.154 /tmp/vb_sklearn/sklearn/neighbors/base.py:96(_fit)
29 0.000 0.000 0.008 0.000 /tmp/vb_sklearn/sklearn/utils/extmath.py:70(safe_sparse_dot)
30 0.001 0.000 0.008 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:229(__mul__)
33 0.006 0.000 0.006 0.000 {method 'sum' of 'numpy.ndarray' objects}
2 0.000 0.000 0.005 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
30 0.000 0.000 0.005 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:250(_mul_vector)
1 0.000 0.000 0.003 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
1 0.000 0.000 0.003 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:23(safe_asarray)
30 0.001 0.000 0.002 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:18(upcast)
29 0.000 0.000 0.002 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/csr.py:287(csr_matvec)
29 0.002 0.000 0.002 0.000 {_csr.csr_matvec}
30 0.001 0.000 0.002 0.000 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:70(_not_converged)
144 0.001 0.000 0.001 0.000 {numpy.core.multiarray.array}
100 0.001 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
69 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
1 0.000 0.000 0.001 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:310(sum)
1 0.000 0.000 0.001 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:486(sum)
31 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:77(isscalarlike)
1 0.000 0.000 0.001 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:302(__rmul__)
2 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:20(__init__)
31 0.000 0.000 0.001 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:124(isdense)
200 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:101(check_format)
30 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1044(ravel)
32 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
32 0.000 0.000 0.000 0.000 {numpy.core.multiarray.zeros}
300 0.000 0.000 0.000 0.000 {numpy.core.multiarray.can_cast}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/csr.py:107(transpose)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/neighbors/base.py:27(warn_equidistant)
179 0.000 0.000 0.000 0.000 {isinstance}
44 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
1 0.000 0.000 0.000 0.000 {_warnings.warn}
32 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1574(isscalar)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/warnings.py:24(_show_warning)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sparsetools/csc.py:183(csc_matvec)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
3 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
1 0.000 0.000 0.000 0.000 {_csc.csc_matvec}
30 0.000 0.000 0.000 0.000 {method 'reshape' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:622(prune)
33 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
3 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/matrixlib/defmatrix.py:55(asmatrix)
1 0.000 0.000 0.000 0.000 {method 'write' of 'file' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/matrixlib/defmatrix.py:233(__new__)
1 0.000 0.000 0.000 0.000 {method 'sort' of 'numpy.ndarray' objects}
96 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:81(get_shape)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/warnings.py:36(formatwarning)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:683(argmax)
30 0.000 0.000 0.000 0.000 {getattr}
2 0.000 0.000 0.000 0.000 {method 'view' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
31 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/data.py:20(_get_dtype)
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.concatenate}
6/5 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/matrixlib/defmatrix.py:279(__array_finalize__)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/twodim_base.py:220(diag)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/data.py:17(__init__)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/neighbors/unsupervised.py:85(__init__)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/matrixlib/defmatrix.py:327(__mul__)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:50(to_native)
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.arange}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:96(isshape)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/linecache.py:13(getline)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:51(__init__)
3 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:59(set_shape)
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/neighbors/base.py:77(_init_params)
2 0.000 0.000 0.000 0.000 {method 'transpose' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:781(copy)
8 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/compressed.py:85(getnnz)
31 0.000 0.000 0.000 0.000 {len}
6 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:2116(rank)
1 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/linecache.py:33(getlines)
3 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/csr.py:180(_swap)
2 0.000 0.000 0.000 0.000 {method 'newbyteorder' of 'numpy.dtype' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:54(getdtype)
1 0.000 0.000 0.000 0.000 {method 'strip' of 'str' objects}
3 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/csc.py:173(_swap)
1 0.000 0.000 0.000 0.000 {hasattr}
2 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/csr.py:129(tocsr)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: predict at line 135
Total time: 0 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
135 def predict(self, X):
136 """Performs inductive inference across the model.
137
138 Parameters
139 ----------
140 X : array_like, shape = [n_samples, n_features]
141
142 Returns
143 -------
144 y : array_like, shape = [n_samples]
145 Predictions for input data
146 """
147 probas = self.predict_proba(X)
148 return self.classes_[np.argmax(probas, axis=1)].ravel()
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: fit at line 185
Total time: 7.81498 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
185 def fit(self, X, y):
186 """Fit a semi-supervised label propagation model based
187
188 All the input data is provided matrix X (labeled and unlabeled)
189 and corresponding label matrix y with a dedicated marker value for
190 unlabeled samples.
191
192 Parameters
193 ----------
194 X : array-like, shape = [n_samples, n_features]
195 A {n_samples by n_samples} size matrix will be created from this
196
197 y : array_like, shape = [n_samples]
198 n_labeled_samples (unlabeled points are marked as -1)
199 All unlabeled samples will be transductively assigned labels
200
201 Returns
202 -------
203 self : returns an instance of self.
204 """
205 1 30 30.0 0.0 if sparse.isspmatrix(X):
206 self.X_ = X
207 else:
208 1 14 14.0 0.0 self.X_ = np.asarray(X)
209
210 # actual graph construction (implementations should override this)
211 1 7800669 7800669.0 99.8 graph_matrix = self._build_graph()
212
213 # label construction
214 # construct a categorical distribution for classification only
215 1 215 215.0 0.0 classes = np.unique(y)
216 1 24 24.0 0.0 classes = (classes[classes != -1])
217 1 4 4.0 0.0 self.classes_ = classes
218
219 1 4 4.0 0.0 n_samples, n_classes = len(y), len(classes)
220
221 1 12 12.0 0.0 y = np.asarray(y)
222 1 20 20.0 0.0 unlabeled = y == -1
223 1 21 21.0 0.0 clamp_weights = np.ones((n_samples, 1))
224 1 235 235.0 0.0 clamp_weights[unlabeled, 0] = self.alpha
225
226 # initialize distributions
227 1 10 10.0 0.0 self.label_distributions_ = np.zeros((n_samples, n_classes))
228 2 12 6.0 0.0 for label in classes:
229 1 135 135.0 0.0 self.label_distributions_[y == label, classes == label] = 1
230
231 1 40 40.0 0.0 y_static = np.copy(self.label_distributions_)
232 1 5 5.0 0.0 if self.alpha > 0.:
233 1 26 26.0 0.0 y_static *= 1 - self.alpha
234 1 297 297.0 0.0 y_static[unlabeled] = 0
235
236 1 11 11.0 0.0 l_previous = np.zeros((self.X_.shape[0], n_classes))
237
238 1 3 3.0 0.0 remaining_iter = self.max_iters
239 1 26 26.0 0.0 if sparse.isspmatrix(graph_matrix):
240 1 8 8.0 0.0 graph_matrix = graph_matrix.tocsr()
241 30 1800 60.0 0.0 while (_not_converged(self.label_distributions_, l_previous, self.tol)
242 30 114 3.8 0.0 and remaining_iter > 1):
243 29 110 3.8 0.0 l_previous = self.label_distributions_
244 29 81 2.8 0.0 self.label_distributions_ = safe_sparse_dot(graph_matrix,
245 29 9499 327.6 0.1 self.label_distributions_)
246 # clamp
247 29 130 4.5 0.0 self.label_distributions_ = np.multiply(clamp_weights,
248 29 1056 36.4 0.0 self.label_distributions_) + y_static
249 29 105 3.6 0.0 remaining_iter -= 1
250
251 1 99 99.0 0.0 normalizer = np.sum(self.label_distributions_, axis=1)[:, np.newaxis]
252 1 58 58.0 0.0 self.label_distributions_ /= normalizer
253 # set the transduction item
254 1 3 3.0 0.0 transduction = self.classes_[np.argmax(self.label_distributions_,
255 1 92 92.0 0.0 axis=1)]
256 1 7 7.0 0.0 self.transduction_ = transduction.ravel()
257 1 3 3.0 0.0 return self
Benchmark statement
obj.predict(X_t)
Execution time
Memory usage
Additional output
cProfile
2481 function calls in 2.301 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 2.301 2.301 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 2.301 2.301 <f>:1(<module>)
1 0.000 0.000 2.301 2.301 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:135(predict)
1 0.008 0.008 2.301 2.301 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:150(predict_proba)
1 0.000 0.000 2.273 2.273 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:112(_get_kernel)
1 0.000 0.000 2.273 2.273 /tmp/vb_sklearn/sklearn/neighbors/base.py:156(kneighbors)
1 2.272 2.272 2.272 2.272 {method 'query' of 'sklearn.neighbors.ball_tree.BallTree' objects}
601 0.013 0.000 0.019 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
602 0.006 0.000 0.006 0.000 {method 'sum' of 'numpy.ndarray' objects}
1 0.000 0.000 0.001 0.001 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
605 0.001 0.000 0.001 0.000 {isinstance}
1 0.000 0.000 0.001 0.001 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
7 0.000 0.000 0.000 0.000 {numpy.core.multiarray.array}
604 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/neighbors/base.py:27(warn_equidistant)
1 0.000 0.000 0.000 0.000 {_warnings.warn}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/warnings.py:24(_show_warning)
1 0.000 0.000 0.000 0.000 {method 'write' of 'file' objects}
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/warnings.py:36(formatwarning)
4 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:683(argmax)
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
8 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/linecache.py:13(getline)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
13 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/linecache.py:33(getlines)
1 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'strip' of 'str' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: predict at line 135
Total time: 2.29733 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
135 def predict(self, X):
136 """Performs inductive inference across the model.
137
138 Parameters
139 ----------
140 X : array_like, shape = [n_samples, n_features]
141
142 Returns
143 -------
144 y : array_like, shape = [n_samples]
145 Predictions for input data
146 """
147 1 2297284 2297284.0 100.0 probas = self.predict_proba(X)
148 1 47 47.0 0.0 return self.classes_[np.argmax(probas, axis=1)].ravel()
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: fit at line 185
Total time: 7.81498 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
185 def fit(self, X, y):
186 """Fit a semi-supervised label propagation model based
187
188 All the input data is provided matrix X (labeled and unlabeled)
189 and corresponding label matrix y with a dedicated marker value for
190 unlabeled samples.
191
192 Parameters
193 ----------
194 X : array-like, shape = [n_samples, n_features]
195 A {n_samples by n_samples} size matrix will be created from this
196
197 y : array_like, shape = [n_samples]
198 n_labeled_samples (unlabeled points are marked as -1)
199 All unlabeled samples will be transductively assigned labels
200
201 Returns
202 -------
203 self : returns an instance of self.
204 """
205 1 30 30.0 0.0 if sparse.isspmatrix(X):
206 self.X_ = X
207 else:
208 1 14 14.0 0.0 self.X_ = np.asarray(X)
209
210 # actual graph construction (implementations should override this)
211 1 7800669 7800669.0 99.8 graph_matrix = self._build_graph()
212
213 # label construction
214 # construct a categorical distribution for classification only
215 1 215 215.0 0.0 classes = np.unique(y)
216 1 24 24.0 0.0 classes = (classes[classes != -1])
217 1 4 4.0 0.0 self.classes_ = classes
218
219 1 4 4.0 0.0 n_samples, n_classes = len(y), len(classes)
220
221 1 12 12.0 0.0 y = np.asarray(y)
222 1 20 20.0 0.0 unlabeled = y == -1
223 1 21 21.0 0.0 clamp_weights = np.ones((n_samples, 1))
224 1 235 235.0 0.0 clamp_weights[unlabeled, 0] = self.alpha
225
226 # initialize distributions
227 1 10 10.0 0.0 self.label_distributions_ = np.zeros((n_samples, n_classes))
228 2 12 6.0 0.0 for label in classes:
229 1 135 135.0 0.0 self.label_distributions_[y == label, classes == label] = 1
230
231 1 40 40.0 0.0 y_static = np.copy(self.label_distributions_)
232 1 5 5.0 0.0 if self.alpha > 0.:
233 1 26 26.0 0.0 y_static *= 1 - self.alpha
234 1 297 297.0 0.0 y_static[unlabeled] = 0
235
236 1 11 11.0 0.0 l_previous = np.zeros((self.X_.shape[0], n_classes))
237
238 1 3 3.0 0.0 remaining_iter = self.max_iters
239 1 26 26.0 0.0 if sparse.isspmatrix(graph_matrix):
240 1 8 8.0 0.0 graph_matrix = graph_matrix.tocsr()
241 30 1800 60.0 0.0 while (_not_converged(self.label_distributions_, l_previous, self.tol)
242 30 114 3.8 0.0 and remaining_iter > 1):
243 29 110 3.8 0.0 l_previous = self.label_distributions_
244 29 81 2.8 0.0 self.label_distributions_ = safe_sparse_dot(graph_matrix,
245 29 9499 327.6 0.1 self.label_distributions_)
246 # clamp
247 29 130 4.5 0.0 self.label_distributions_ = np.multiply(clamp_weights,
248 29 1056 36.4 0.0 self.label_distributions_) + y_static
249 29 105 3.6 0.0 remaining_iter -= 1
250
251 1 99 99.0 0.0 normalizer = np.sum(self.label_distributions_, axis=1)[:, np.newaxis]
252 1 58 58.0 0.0 self.label_distributions_ /= normalizer
253 # set the transduction item
254 1 3 3.0 0.0 transduction = self.classes_[np.argmax(self.label_distributions_,
255 1 92 92.0 0.0 axis=1)]
256 1 7 7.0 0.0 self.transduction_ = transduction.ravel()
257 1 3 3.0 0.0 return self
LabelPropagation-rbf-arcene-semi¶
Benchmark setup
from sklearn.semi_supervised import LabelPropagation from deps import load_data kwargs = {'kernel': 'rbf'} X, y, X_t, y_t = load_data('arcene-semi') obj = LabelPropagation(**kwargs)
Benchmark statement
obj.fit(X, y)
Execution time
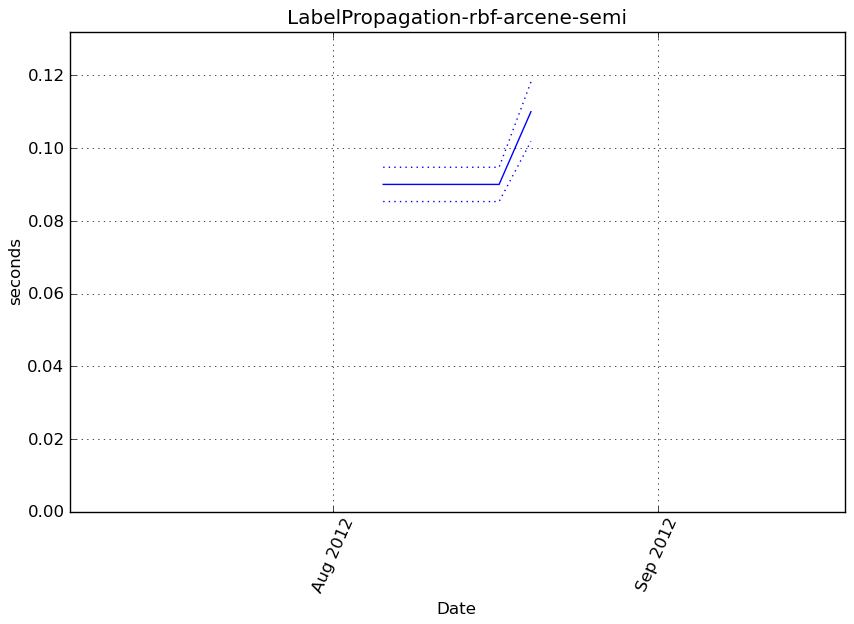
Memory usage
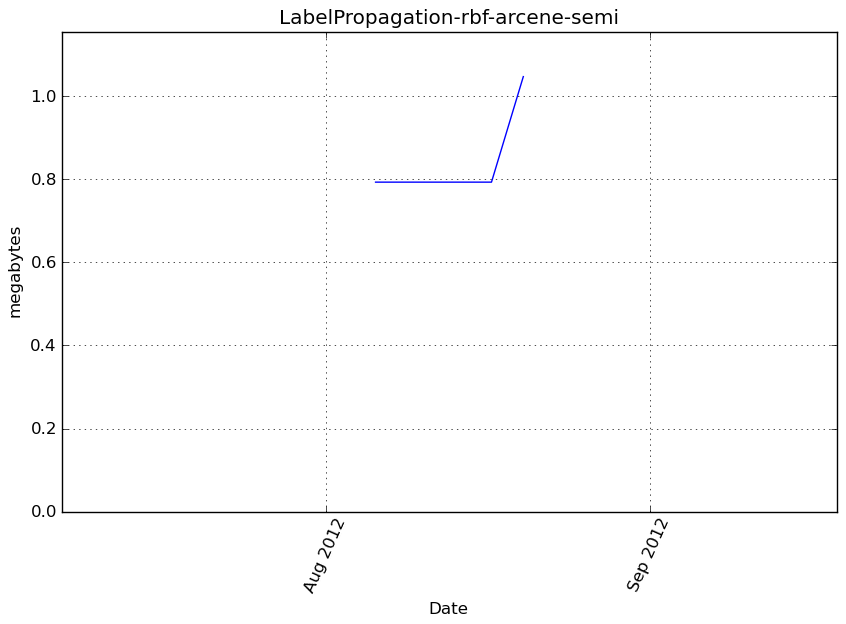
Additional output
cProfile
155 function calls in 0.106 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.106 0.106 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 0.106 0.106 <f>:1(<module>)
1 0.000 0.000 0.106 0.106 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:185(fit)
1 0.000 0.000 0.105 0.105 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:304(_build_graph)
1 0.000 0.000 0.105 0.105 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:112(_get_kernel)
1 0.001 0.001 0.105 0.105 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:325(rbf_kernel)
1 0.007 0.007 0.099 0.099 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:101(euclidean_distances)
2 0.000 0.000 0.084 0.042 /tmp/vb_sklearn/sklearn/utils/extmath.py:70(safe_sparse_dot)
2 0.084 0.042 0.084 0.042 {numpy.core._dotblas.dot}
9 0.014 0.002 0.014 0.002 {method 'sum' of 'numpy.ndarray' objects}
2 0.000 0.000 0.011 0.006 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:52(check_pairwise_arrays)
4 0.000 0.000 0.011 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
2 0.000 0.000 0.006 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:23(safe_asarray)
2 0.000 0.000 0.006 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
2 0.000 0.000 0.003 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
14 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
14 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:70(_not_converged)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
28 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.concatenate}
16 0.000 0.000 0.000 0.000 {isinstance}
9 0.000 0.000 0.000 0.000 {numpy.core.multiarray.array}
6 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:683(argmax)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:781(copy)
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 {numpy.core.multiarray.zeros}
12 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'sort' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
2 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: predict at line 135
Total time: 0 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
135 def predict(self, X):
136 """Performs inductive inference across the model.
137
138 Parameters
139 ----------
140 X : array_like, shape = [n_samples, n_features]
141
142 Returns
143 -------
144 y : array_like, shape = [n_samples]
145 Predictions for input data
146 """
147 probas = self.predict_proba(X)
148 return self.classes_[np.argmax(probas, axis=1)].ravel()
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: fit at line 185
Total time: 0.09865 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
185 def fit(self, X, y):
186 """Fit a semi-supervised label propagation model based
187
188 All the input data is provided matrix X (labeled and unlabeled)
189 and corresponding label matrix y with a dedicated marker value for
190 unlabeled samples.
191
192 Parameters
193 ----------
194 X : array-like, shape = [n_samples, n_features]
195 A {n_samples by n_samples} size matrix will be created from this
196
197 y : array_like, shape = [n_samples]
198 n_labeled_samples (unlabeled points are marked as -1)
199 All unlabeled samples will be transductively assigned labels
200
201 Returns
202 -------
203 self : returns an instance of self.
204 """
205 1 30 30.0 0.0 if sparse.isspmatrix(X):
206 self.X_ = X
207 else:
208 1 14 14.0 0.0 self.X_ = np.asarray(X)
209
210 # actual graph construction (implementations should override this)
211 1 97747 97747.0 99.1 graph_matrix = self._build_graph()
212
213 # label construction
214 # construct a categorical distribution for classification only
215 1 99 99.0 0.1 classes = np.unique(y)
216 1 21 21.0 0.0 classes = (classes[classes != -1])
217 1 4 4.0 0.0 self.classes_ = classes
218
219 1 5 5.0 0.0 n_samples, n_classes = len(y), len(classes)
220
221 1 14 14.0 0.0 y = np.asarray(y)
222 1 14 14.0 0.0 unlabeled = y == -1
223 1 21 21.0 0.0 clamp_weights = np.ones((n_samples, 1))
224 1 31 31.0 0.0 clamp_weights[unlabeled, 0] = self.alpha
225
226 # initialize distributions
227 1 9 9.0 0.0 self.label_distributions_ = np.zeros((n_samples, n_classes))
228 2 16 8.0 0.0 for label in classes:
229 1 145 145.0 0.1 self.label_distributions_[y == label, classes == label] = 1
230
231 1 19 19.0 0.0 y_static = np.copy(self.label_distributions_)
232 1 4 4.0 0.0 if self.alpha > 0.:
233 1 21 21.0 0.0 y_static *= 1 - self.alpha
234 1 32 32.0 0.0 y_static[unlabeled] = 0
235
236 1 9 9.0 0.0 l_previous = np.zeros((self.X_.shape[0], n_classes))
237
238 1 3 3.0 0.0 remaining_iter = self.max_iters
239 1 26 26.0 0.0 if sparse.isspmatrix(graph_matrix):
240 graph_matrix = graph_matrix.tocsr()
241 2 85 42.5 0.1 while (_not_converged(self.label_distributions_, l_previous, self.tol)
242 1 4 4.0 0.0 and remaining_iter > 1):
243 1 4 4.0 0.0 l_previous = self.label_distributions_
244 1 3 3.0 0.0 self.label_distributions_ = safe_sparse_dot(graph_matrix,
245 1 85 85.0 0.1 self.label_distributions_)
246 # clamp
247 1 4 4.0 0.0 self.label_distributions_ = np.multiply(clamp_weights,
248 1 22 22.0 0.0 self.label_distributions_) + y_static
249 1 3 3.0 0.0 remaining_iter -= 1
250
251 1 42 42.0 0.0 normalizer = np.sum(self.label_distributions_, axis=1)[:, np.newaxis]
252 1 37 37.0 0.0 self.label_distributions_ /= normalizer
253 # set the transduction item
254 1 4 4.0 0.0 transduction = self.classes_[np.argmax(self.label_distributions_,
255 1 25 25.0 0.0 axis=1)]
256 1 45 45.0 0.0 self.transduction_ = transduction.ravel()
257 1 3 3.0 0.0 return self
Benchmark statement
obj.predict(X_t)
Execution time
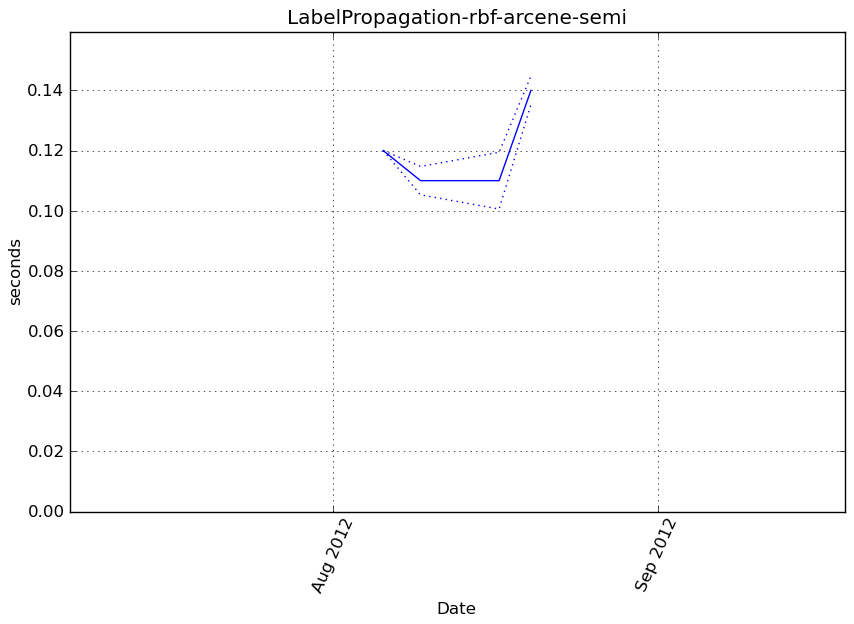
Memory usage
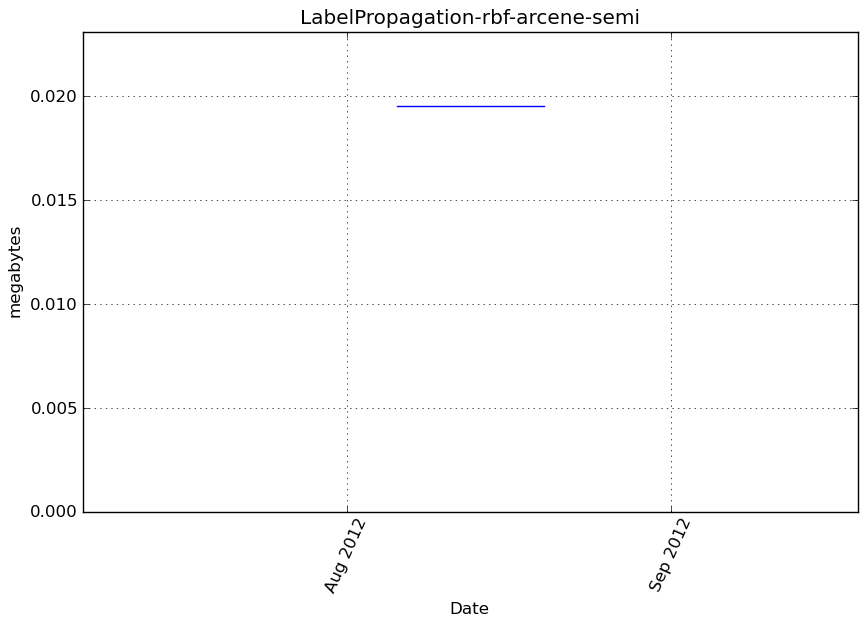
Additional output
cProfile
200 function calls in 0.120 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.120 0.120 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 0.120 0.120 <f>:1(<module>)
1 0.000 0.000 0.120 0.120 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:135(predict)
1 0.000 0.000 0.120 0.120 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:150(predict_proba)
1 0.000 0.000 0.115 0.115 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:112(_get_kernel)
1 0.001 0.001 0.115 0.115 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:325(rbf_kernel)
1 0.006 0.006 0.103 0.103 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:101(euclidean_distances)
2 0.084 0.042 0.084 0.042 {numpy.core._dotblas.dot}
1 0.000 0.000 0.080 0.080 /tmp/vb_sklearn/sklearn/utils/extmath.py:70(safe_sparse_dot)
11 0.027 0.002 0.027 0.002 {method 'sum' of 'numpy.ndarray' objects}
2 0.000 0.000 0.023 0.011 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:52(check_pairwise_arrays)
8 0.000 0.000 0.022 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
4 0.000 0.000 0.011 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
4 0.000 0.000 0.011 0.003 /tmp/vb_sklearn/sklearn/utils/validation.py:23(safe_asarray)
3 0.000 0.000 0.006 0.002 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
17 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
17 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
4 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
6 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
34 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
20 0.000 0.000 0.000 0.000 {isinstance}
6 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
14 0.000 0.000 0.000 0.000 {numpy.core.multiarray.array}
8 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:683(argmax)
22 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
6 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: predict at line 135
Total time: 0.119545 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
135 def predict(self, X):
136 """Performs inductive inference across the model.
137
138 Parameters
139 ----------
140 X : array_like, shape = [n_samples, n_features]
141
142 Returns
143 -------
144 y : array_like, shape = [n_samples]
145 Predictions for input data
146 """
147 1 119514 119514.0 100.0 probas = self.predict_proba(X)
148 1 31 31.0 0.0 return self.classes_[np.argmax(probas, axis=1)].ravel()
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: fit at line 185
Total time: 0.09865 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
185 def fit(self, X, y):
186 """Fit a semi-supervised label propagation model based
187
188 All the input data is provided matrix X (labeled and unlabeled)
189 and corresponding label matrix y with a dedicated marker value for
190 unlabeled samples.
191
192 Parameters
193 ----------
194 X : array-like, shape = [n_samples, n_features]
195 A {n_samples by n_samples} size matrix will be created from this
196
197 y : array_like, shape = [n_samples]
198 n_labeled_samples (unlabeled points are marked as -1)
199 All unlabeled samples will be transductively assigned labels
200
201 Returns
202 -------
203 self : returns an instance of self.
204 """
205 1 30 30.0 0.0 if sparse.isspmatrix(X):
206 self.X_ = X
207 else:
208 1 14 14.0 0.0 self.X_ = np.asarray(X)
209
210 # actual graph construction (implementations should override this)
211 1 97747 97747.0 99.1 graph_matrix = self._build_graph()
212
213 # label construction
214 # construct a categorical distribution for classification only
215 1 99 99.0 0.1 classes = np.unique(y)
216 1 21 21.0 0.0 classes = (classes[classes != -1])
217 1 4 4.0 0.0 self.classes_ = classes
218
219 1 5 5.0 0.0 n_samples, n_classes = len(y), len(classes)
220
221 1 14 14.0 0.0 y = np.asarray(y)
222 1 14 14.0 0.0 unlabeled = y == -1
223 1 21 21.0 0.0 clamp_weights = np.ones((n_samples, 1))
224 1 31 31.0 0.0 clamp_weights[unlabeled, 0] = self.alpha
225
226 # initialize distributions
227 1 9 9.0 0.0 self.label_distributions_ = np.zeros((n_samples, n_classes))
228 2 16 8.0 0.0 for label in classes:
229 1 145 145.0 0.1 self.label_distributions_[y == label, classes == label] = 1
230
231 1 19 19.0 0.0 y_static = np.copy(self.label_distributions_)
232 1 4 4.0 0.0 if self.alpha > 0.:
233 1 21 21.0 0.0 y_static *= 1 - self.alpha
234 1 32 32.0 0.0 y_static[unlabeled] = 0
235
236 1 9 9.0 0.0 l_previous = np.zeros((self.X_.shape[0], n_classes))
237
238 1 3 3.0 0.0 remaining_iter = self.max_iters
239 1 26 26.0 0.0 if sparse.isspmatrix(graph_matrix):
240 graph_matrix = graph_matrix.tocsr()
241 2 85 42.5 0.1 while (_not_converged(self.label_distributions_, l_previous, self.tol)
242 1 4 4.0 0.0 and remaining_iter > 1):
243 1 4 4.0 0.0 l_previous = self.label_distributions_
244 1 3 3.0 0.0 self.label_distributions_ = safe_sparse_dot(graph_matrix,
245 1 85 85.0 0.1 self.label_distributions_)
246 # clamp
247 1 4 4.0 0.0 self.label_distributions_ = np.multiply(clamp_weights,
248 1 22 22.0 0.0 self.label_distributions_) + y_static
249 1 3 3.0 0.0 remaining_iter -= 1
250
251 1 42 42.0 0.0 normalizer = np.sum(self.label_distributions_, axis=1)[:, np.newaxis]
252 1 37 37.0 0.0 self.label_distributions_ /= normalizer
253 # set the transduction item
254 1 4 4.0 0.0 transduction = self.classes_[np.argmax(self.label_distributions_,
255 1 25 25.0 0.0 axis=1)]
256 1 45 45.0 0.0 self.transduction_ = transduction.ravel()
257 1 3 3.0 0.0 return self
LabelPropagation-rbf-madelon-semi¶
Benchmark setup
from sklearn.semi_supervised import LabelPropagation from deps import load_data kwargs = {'kernel': 'rbf'} X, y, X_t, y_t = load_data('madelon-semi') obj = LabelPropagation(**kwargs)
Benchmark statement
obj.fit(X, y)
Execution time
Memory usage
Additional output
cProfile
155 function calls in 2.020 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 2.020 2.020 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 2.020 2.020 <f>:1(<module>)
1 0.001 0.001 2.020 2.020 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:185(fit)
1 0.041 0.041 2.010 2.010 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:304(_build_graph)
1 0.000 0.000 1.813 1.813 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:112(_get_kernel)
1 0.242 0.242 1.813 1.813 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:325(rbf_kernel)
1 0.076 0.076 1.568 1.568 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:101(euclidean_distances)
2 0.000 0.000 1.495 0.747 /tmp/vb_sklearn/sklearn/utils/extmath.py:70(safe_sparse_dot)
2 1.495 0.747 1.495 0.747 {numpy.core._dotblas.dot}
9 0.163 0.018 0.163 0.018 {method 'sum' of 'numpy.ndarray' objects}
2 0.000 0.000 0.006 0.003 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:52(check_pairwise_arrays)
4 0.000 0.000 0.006 0.002 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
2 0.000 0.000 0.003 0.002 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
2 0.000 0.000 0.003 0.002 /tmp/vb_sklearn/sklearn/utils/validation.py:23(safe_asarray)
2 0.000 0.000 0.002 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
14 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/arraysetops.py:90(unique)
14 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:70(_not_converged)
2 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
1 0.000 0.000 0.000 0.000 {method 'sort' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:683(argmax)
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.concatenate}
28 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
16 0.000 0.000 0.000 0.000 {isinstance}
9 0.000 0.000 0.000 0.000 {numpy.core.multiarray.array}
6 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:1791(ones)
1 0.000 0.000 0.000 0.000 {method 'flatten' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/lib/function_base.py:781(copy)
2 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
2 0.000 0.000 0.000 0.000 {numpy.core.multiarray.zeros}
1 0.000 0.000 0.000 0.000 {method 'fill' of 'numpy.ndarray' objects}
12 0.000 0.000 0.000 0.000 {len}
1 0.000 0.000 0.000 0.000 {numpy.core.multiarray.empty}
1 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
2 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: predict at line 135
Total time: 0 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
135 def predict(self, X):
136 """Performs inductive inference across the model.
137
138 Parameters
139 ----------
140 X : array_like, shape = [n_samples, n_features]
141
142 Returns
143 -------
144 y : array_like, shape = [n_samples]
145 Predictions for input data
146 """
147 probas = self.predict_proba(X)
148 return self.classes_[np.argmax(probas, axis=1)].ravel()
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: fit at line 185
Total time: 2.05724 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
185 def fit(self, X, y):
186 """Fit a semi-supervised label propagation model based
187
188 All the input data is provided matrix X (labeled and unlabeled)
189 and corresponding label matrix y with a dedicated marker value for
190 unlabeled samples.
191
192 Parameters
193 ----------
194 X : array-like, shape = [n_samples, n_features]
195 A {n_samples by n_samples} size matrix will be created from this
196
197 y : array_like, shape = [n_samples]
198 n_labeled_samples (unlabeled points are marked as -1)
199 All unlabeled samples will be transductively assigned labels
200
201 Returns
202 -------
203 self : returns an instance of self.
204 """
205 1 31 31.0 0.0 if sparse.isspmatrix(X):
206 self.X_ = X
207 else:
208 1 13 13.0 0.0 self.X_ = np.asarray(X)
209
210 # actual graph construction (implementations should override this)
211 1 2047631 2047631.0 99.5 graph_matrix = self._build_graph()
212
213 # label construction
214 # construct a categorical distribution for classification only
215 1 221 221.0 0.0 classes = np.unique(y)
216 1 26 26.0 0.0 classes = (classes[classes != -1])
217 1 5 5.0 0.0 self.classes_ = classes
218
219 1 5 5.0 0.0 n_samples, n_classes = len(y), len(classes)
220
221 1 16 16.0 0.0 y = np.asarray(y)
222 1 20 20.0 0.0 unlabeled = y == -1
223 1 27 27.0 0.0 clamp_weights = np.ones((n_samples, 1))
224 1 238 238.0 0.0 clamp_weights[unlabeled, 0] = self.alpha
225
226 # initialize distributions
227 1 10 10.0 0.0 self.label_distributions_ = np.zeros((n_samples, n_classes))
228 2 14 7.0 0.0 for label in classes:
229 1 138 138.0 0.0 self.label_distributions_[y == label, classes == label] = 1
230
231 1 19 19.0 0.0 y_static = np.copy(self.label_distributions_)
232 1 5 5.0 0.0 if self.alpha > 0.:
233 1 25 25.0 0.0 y_static *= 1 - self.alpha
234 1 302 302.0 0.0 y_static[unlabeled] = 0
235
236 1 12 12.0 0.0 l_previous = np.zeros((self.X_.shape[0], n_classes))
237
238 1 3 3.0 0.0 remaining_iter = self.max_iters
239 1 34 34.0 0.0 if sparse.isspmatrix(graph_matrix):
240 graph_matrix = graph_matrix.tocsr()
241 2 162 81.0 0.0 while (_not_converged(self.label_distributions_, l_previous, self.tol)
242 1 3 3.0 0.0 and remaining_iter > 1):
243 1 4 4.0 0.0 l_previous = self.label_distributions_
244 1 3 3.0 0.0 self.label_distributions_ = safe_sparse_dot(graph_matrix,
245 1 7861 7861.0 0.4 self.label_distributions_)
246 # clamp
247 1 7 7.0 0.0 self.label_distributions_ = np.multiply(clamp_weights,
248 1 58 58.0 0.0 self.label_distributions_) + y_static
249 1 4 4.0 0.0 remaining_iter -= 1
250
251 1 105 105.0 0.0 normalizer = np.sum(self.label_distributions_, axis=1)[:, np.newaxis]
252 1 56 56.0 0.0 self.label_distributions_ /= normalizer
253 # set the transduction item
254 1 4 4.0 0.0 transduction = self.classes_[np.argmax(self.label_distributions_,
255 1 165 165.0 0.0 axis=1)]
256 1 8 8.0 0.0 self.transduction_ = transduction.ravel()
257 1 3 3.0 0.0 return self
Benchmark statement
obj.predict(X_t)
Execution time
Memory usage
Additional output
cProfile
200 function calls in 1.258 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 1.258 1.258 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/vbench/benchmark.py:286(f)
1 0.000 0.000 1.258 1.258 <f>:1(<module>)
1 0.000 0.000 1.258 1.258 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:135(predict)
1 0.000 0.000 1.258 1.258 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:150(predict_proba)
2 1.121 0.561 1.121 0.561 {numpy.core._dotblas.dot}
1 0.000 0.000 0.589 0.589 /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py:112(_get_kernel)
1 0.097 0.097 0.589 0.589 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:325(rbf_kernel)
1 0.022 0.022 0.485 0.485 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:101(euclidean_distances)
1 0.000 0.000 0.452 0.452 /tmp/vb_sklearn/sklearn/utils/extmath.py:70(safe_sparse_dot)
11 0.018 0.002 0.018 0.002 {method 'sum' of 'numpy.ndarray' objects}
2 0.000 0.000 0.015 0.007 /tmp/vb_sklearn/sklearn/metrics/pairwise.py:52(check_pairwise_arrays)
8 0.000 0.000 0.014 0.002 /tmp/vb_sklearn/sklearn/utils/validation.py:10(assert_all_finite)
4 0.000 0.000 0.007 0.002 /tmp/vb_sklearn/sklearn/utils/validation.py:70(atleast2d_or_csr)
4 0.000 0.000 0.007 0.002 /tmp/vb_sklearn/sklearn/utils/validation.py:23(safe_asarray)
3 0.000 0.000 0.004 0.001 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:1379(sum)
17 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/base.py:553(isspmatrix)
17 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/scipy/sparse/sputils.py:116(_isinstance)
4 0.000 0.000 0.000 0.000 /tmp/vb_sklearn/sklearn/utils/validation.py:62(array2d)
6 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/shape_base.py:58(atleast_2d)
34 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}
20 0.000 0.000 0.000 0.000 {isinstance}
6 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:237(asanyarray)
14 0.000 0.000 0.000 0.000 {numpy.core.multiarray.array}
8 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/numeric.py:167(asarray)
1 0.000 0.000 0.000 0.000 /home/slave/virtualenvs/cpython-2.7.2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:683(argmax)
1 0.000 0.000 0.000 0.000 {method 'argmax' of 'numpy.ndarray' objects}
22 0.000 0.000 0.000 0.000 {len}
6 0.000 0.000 0.000 0.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
LineProfiler
Timer unit: 1e-06 s
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: predict at line 135
Total time: 1.25452 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
135 def predict(self, X):
136 """Performs inductive inference across the model.
137
138 Parameters
139 ----------
140 X : array_like, shape = [n_samples, n_features]
141
142 Returns
143 -------
144 y : array_like, shape = [n_samples]
145 Predictions for input data
146 """
147 1 1254470 1254470.0 100.0 probas = self.predict_proba(X)
148 1 49 49.0 0.0 return self.classes_[np.argmax(probas, axis=1)].ravel()
File: /tmp/vb_sklearn/sklearn/semi_supervised/label_propagation.py
Function: fit at line 185
Total time: 2.05724 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
185 def fit(self, X, y):
186 """Fit a semi-supervised label propagation model based
187
188 All the input data is provided matrix X (labeled and unlabeled)
189 and corresponding label matrix y with a dedicated marker value for
190 unlabeled samples.
191
192 Parameters
193 ----------
194 X : array-like, shape = [n_samples, n_features]
195 A {n_samples by n_samples} size matrix will be created from this
196
197 y : array_like, shape = [n_samples]
198 n_labeled_samples (unlabeled points are marked as -1)
199 All unlabeled samples will be transductively assigned labels
200
201 Returns
202 -------
203 self : returns an instance of self.
204 """
205 1 31 31.0 0.0 if sparse.isspmatrix(X):
206 self.X_ = X
207 else:
208 1 13 13.0 0.0 self.X_ = np.asarray(X)
209
210 # actual graph construction (implementations should override this)
211 1 2047631 2047631.0 99.5 graph_matrix = self._build_graph()
212
213 # label construction
214 # construct a categorical distribution for classification only
215 1 221 221.0 0.0 classes = np.unique(y)
216 1 26 26.0 0.0 classes = (classes[classes != -1])
217 1 5 5.0 0.0 self.classes_ = classes
218
219 1 5 5.0 0.0 n_samples, n_classes = len(y), len(classes)
220
221 1 16 16.0 0.0 y = np.asarray(y)
222 1 20 20.0 0.0 unlabeled = y == -1
223 1 27 27.0 0.0 clamp_weights = np.ones((n_samples, 1))
224 1 238 238.0 0.0 clamp_weights[unlabeled, 0] = self.alpha
225
226 # initialize distributions
227 1 10 10.0 0.0 self.label_distributions_ = np.zeros((n_samples, n_classes))
228 2 14 7.0 0.0 for label in classes:
229 1 138 138.0 0.0 self.label_distributions_[y == label, classes == label] = 1
230
231 1 19 19.0 0.0 y_static = np.copy(self.label_distributions_)
232 1 5 5.0 0.0 if self.alpha > 0.:
233 1 25 25.0 0.0 y_static *= 1 - self.alpha
234 1 302 302.0 0.0 y_static[unlabeled] = 0
235
236 1 12 12.0 0.0 l_previous = np.zeros((self.X_.shape[0], n_classes))
237
238 1 3 3.0 0.0 remaining_iter = self.max_iters
239 1 34 34.0 0.0 if sparse.isspmatrix(graph_matrix):
240 graph_matrix = graph_matrix.tocsr()
241 2 162 81.0 0.0 while (_not_converged(self.label_distributions_, l_previous, self.tol)
242 1 3 3.0 0.0 and remaining_iter > 1):
243 1 4 4.0 0.0 l_previous = self.label_distributions_
244 1 3 3.0 0.0 self.label_distributions_ = safe_sparse_dot(graph_matrix,
245 1 7861 7861.0 0.4 self.label_distributions_)
246 # clamp
247 1 7 7.0 0.0 self.label_distributions_ = np.multiply(clamp_weights,
248 1 58 58.0 0.0 self.label_distributions_) + y_static
249 1 4 4.0 0.0 remaining_iter -= 1
250
251 1 105 105.0 0.0 normalizer = np.sum(self.label_distributions_, axis=1)[:, np.newaxis]
252 1 56 56.0 0.0 self.label_distributions_ /= normalizer
253 # set the transduction item
254 1 4 4.0 0.0 transduction = self.classes_[np.argmax(self.label_distributions_,
255 1 165 165.0 0.0 axis=1)]
256 1 8 8.0 0.0 self.transduction_ = transduction.ravel()
257 1 3 3.0 0.0 return self